고정길이코드 VS 가변길이코드
고정길이코드는 각 문자당 비트 수(code word의 길이)가 정해져있기 때문에 인코딩, 디코딩 시 분석이 쉽다. 가변길이코드는 각 분자당 비트 수(code word의 길이)가 다르기 때문에 인코딩, 디코딩 시 분석이 어렵다. BUT, 가변길이코드가 고정길이 코드에 비해 더 적은 비트수를 사용해서 데이터를 처리할 수 있다.
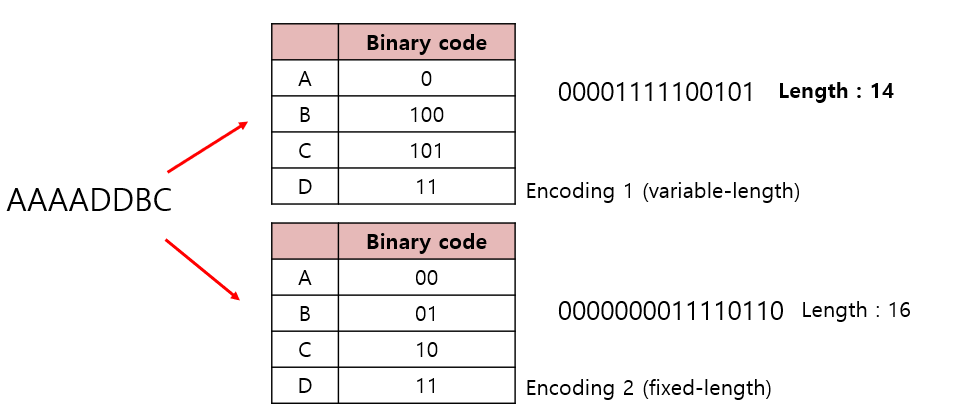
허프만 인코딩
문자열에서 빈도수가 큰 문자일수록 code word 길이를 작게 하여 이진 데이터를 할당함으로써 전체 문자의 비트 수를 줄인다. (Greedy algorithm)
✔규칙: 어떤 codeword도 다른 codeword의 prefix가 되지 않아야 한다.
Ex) A = 00, B = 001 (A의 codeword가 B의 codeword의 prefix.) 일 때,
만약, 001011010 과 같은 코드에서 처음 001부분에서 00으로 해석하여 A인지, 001로 해석하여 B인지 Ambiguous(모호)하다.
허프만 트리 (O(nlogn))
✔ full binary tree(leaf node를 제외한 나머지 노드들의 child가 2개)로 구현한다.
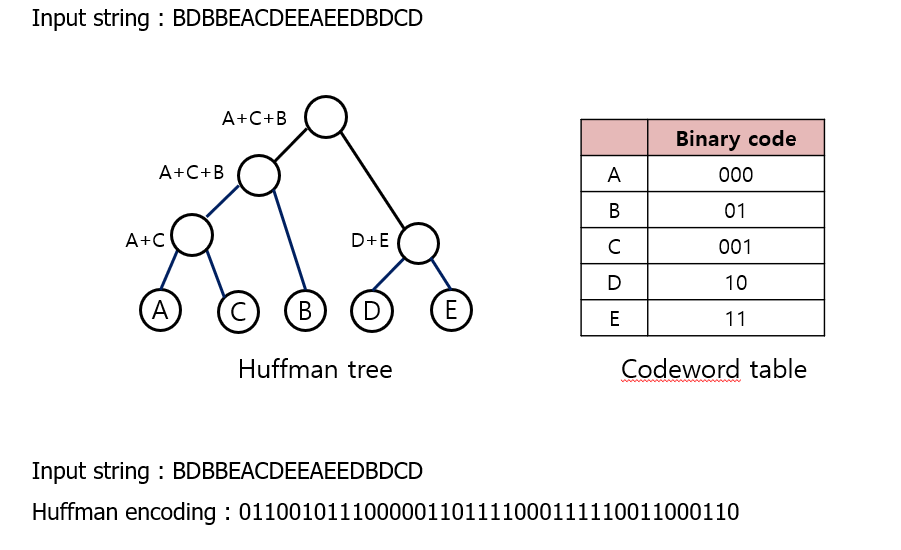
✔ 허프만 트리의 각 leaf node들은 인코딩하려는 original string의 각 alphabet에 해당한다.
✔ 각 알파벳의 codeword는 허프만 트리의 root node에서부터 각 알파벳까지의 path에 의해 결정된다.
✔ root node에서 출발하여 left child는 0, right child는 1의 값을 할당한다.
허프만 트리 구현
빈도수가 작은 순서대로 재귀적으로 subtree를 생성한다.
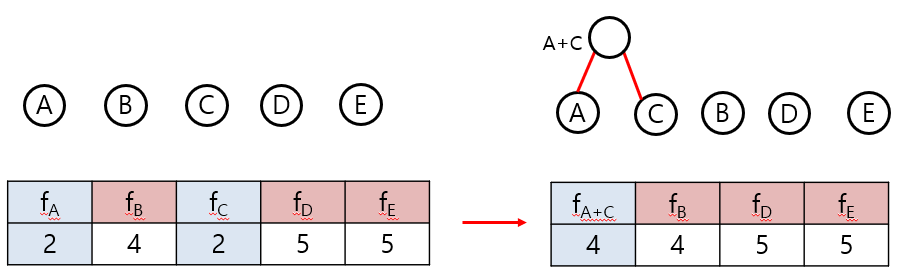
STEP 1) Original String에서 각 알파벳의 빈도수를 구하여 frequency table을 만든다.
STEP 2) 각 알파벳에 해당하는 leaf node들을 생성한다.
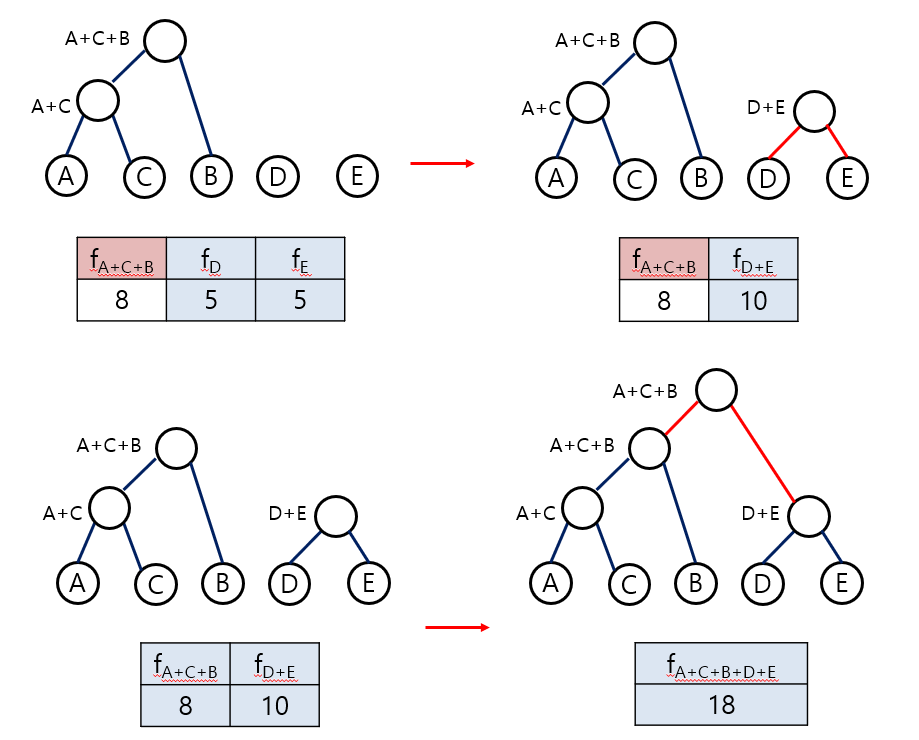
STEP 3) frequency table에서 빈도수가 가장 낮은 node 두개를 left, right child로 가지는 tree를 생성한다. 두 child의 빈도수를 합한 것이 parent node가 된다.
STEP 4) 합쳐진 두 child는 frequency table에서 삭제되고 parent node가 들어간다.
STEP 5) STEP3와 STEP4를 반복한다. -> frequency table에 알파벳 하나 남을 때까지
frequency table은 Priority Queue(우선순위 큐)로 구현