HDD 구조
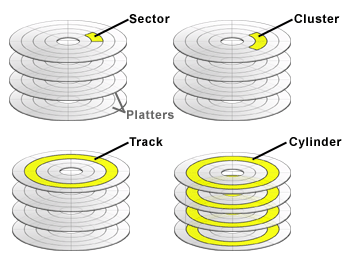
디스크를 일정한 크기의 1차원 배열로 생각하고, 인덱스로 접근하는데, 그 한 칸을 논리블록이라 한다. 실제 디스크 내 물리적 위치인 섹터와 논리블록이 1:1로 매핑된다. 섹터가 모여서 트랙이 되고, 각 플래터(원판 하나의 동일한 트랙의 집합을 실린더라 한다.
OS가 디스크를 관리하는 방법
디스크는 기계장치이기 때문에 에러가 많고 무언가에 찍히거나 해서 손상을 입어 Bad Block이 생길 수도 있고 데이터를 잘못 찾을 수 도 있다. 운영체제는 이런 문제들이 User-level SW에 보이지 않도록 본인이 알아서 해결할 수 있다.
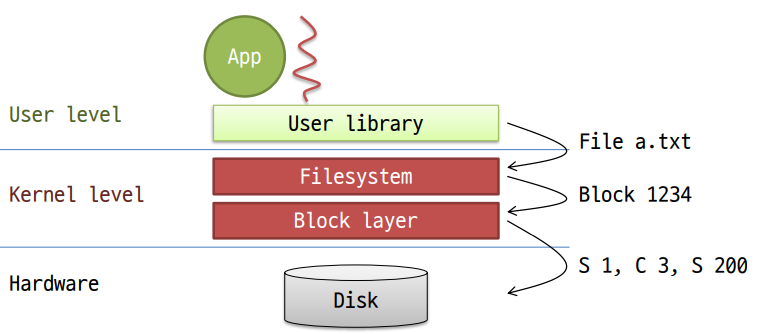
OS는 디스크 엑세스에 여러 레벨은 거치는데,
1. User-level에서 라이브러리로 엑세스 할 수 있는 Logical file을 거쳐
2. Kernel-level에서 파일 시스템에서 논리 블록을 거쳐
3. Kernel-level에서 Block-layer에서 physical disk block을 거친다. 여기에는 어디 플래터 어디 실린더에 어디 트랙 어디 섹터... 이런게 들어감.
디스크 요청은 cylinder #, surface #, track #, sector #, transfer size 등 많은 정보를 요구하는데 과거 디스크들은 OS가 이 정보를 모두 알려줘야 했다. 그래서 OS 이 모든 정보를 갖고 있어야 했는데, 현재 디스크들은 더 복잡해졌다. 섹터들의 사이즈가 다르고, 섹터끼리 매핑되어있는 경우도 있다. 디스크가 복잡해지고 똑똑해졌기 때문에 운영체제가 할 일이 줄어들었다. cylinder #, surface #, track #, sector #를 운영체제가 갖고있지 않아도 되고 운영체제와 논리 블록으로 소통한다. 디스크가 논리블록을 알아서 physical한 위치로 매핑한다. 따라서 운영체제는 해당 논리블록에 read를 할 것인지 write를 할 것인지만 알려주면 디스크가 알아서 처리한다. 결과적으로, 디스크의 물리적인 위치는 OS에 숨겨진다.
디스크 성능
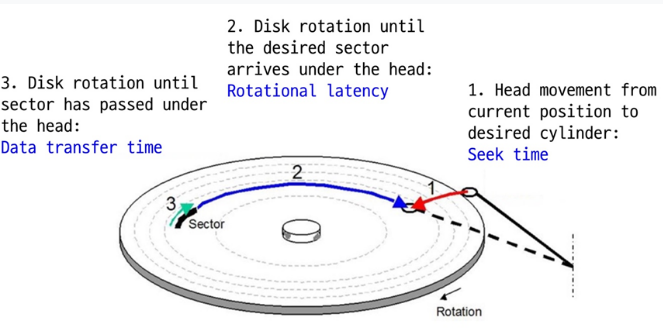
디스크 접근에 걸리는 시간은 세 가지로 구분할 수 있는데,
1. seek time : 디스크 헤드를 해당 실린더로 옮기는데 걸리는 시간으로, arm이 이동하는 것이기 때문에 가장 느리다.
2. rotation time : 특정 섹터가 헤드 위치까지 도달하기 위해 디스크 판을 회전시키는데 걸리는 시간으로, 판이 얼마나 돌아가느냐에 따라 이 시간이 결정된다. 두번째로 느리다.
3. transfer time : 해당 섹터가 헤드에 위치한 후, 섹터를 읽거나 쓰고 데이터를 전송하는데 걸리는 시간으로, 디스크의 byte 밀도에 따라 시간이 결정된다. 가장 빠르다.
디스크 성능을 높이기 위해서는?
디스크 입출력 효율을 높이기 위해서는 디스크 입출력에 소요되는 접근 시간을 줄여야 하는데, rotation time과 transfer time은 상대적인 수치가 작고 운영체제가 통제하기 힘든 영역이므로 헤드를 최소한으로 움직여 seek time을 최소화하는것이 중요하다. 또한, 디스크에 입출력 요청이 들어오면 디스크는 다른 일을 하고 있는데, 이때, 요청들은 디스크 큐에 들어간다. 이 여러 요청들에 대한 스케쥴링이 필요한데, 디스크 스케쥴링은 여러 섹터들에 대한 입출력 요청이 들어왔을 때, 어떤 순서로 처리할 것인지 결정하는 매커니즘이다.
FCFS-First Come First Served(FIFO)
먼저 들어온 요청을 먼저 처리하는 방법이다. 입출력 요청이 적은 경우 합리적이지만, 최악의 경우 요청이 실린더의 끝과 끝이 반복해서 요청된다면 seek time이 비효율적으로 늘어난다. 별로...안좋음
SSTF(Shortest Seek Time First)
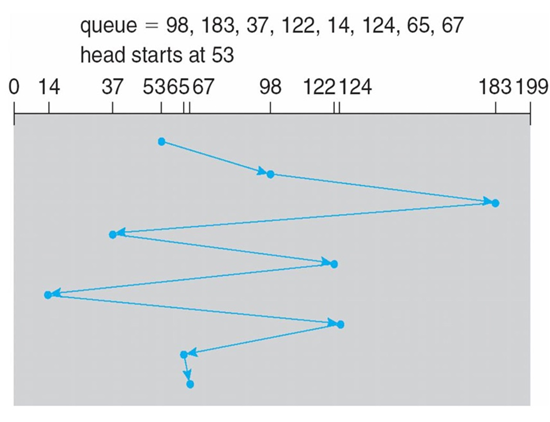
헤드의 현재 위치로부터 가장 가까운 섹터(seek time이 가장 짧은 섹터)의 요청을 먼저 처리하는 방법으로, arm의 움직임을 최소화하여 seek time을 최소화 하여 request rate를 최대화 하지만, 중간 블록이 가까우니 선호하여 중간쪽에 몰려있는 섹터만 unfair하게 지속적으로 읽을 수 있고, 현재 헤드 위치로부터 가까운 곳에서 지속적인 요청이 들어왔을 때, 헤드에서 멀리 떨어진 요청은 무한히 기다려야 하는 starvation이 생길 수 있다.
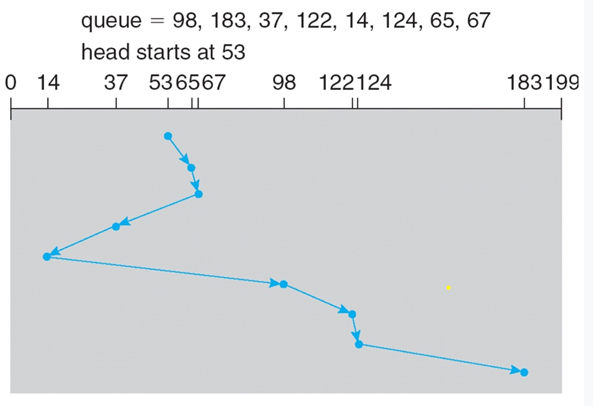
SCAN(엘리베이터 알고리즘)
헤드가 원판의 안쪽 실린더와 바깥쪽 실린더를 반복해서 이동하며 길목에 있는 요청을 모두 처리하는 방법으로, 엘리베이터가 1층부터 꼭대기층까지 오가며 사람들을 태우고 내리는 것으로 비유할 수 있는 알고리즘이다. 불필요한 헤드의 움직임이나 일부 요청에 지나치게 오래 기다리는 현상이 없지만, 완전히 fair하다고 할 수 없다. 헤드가 양 끝을 오갈 때, 가운데 위치가 양 끝보다 기다리는 waiting time이 절반이기 때문이다. (0-100까지 있다고 하면 0-50-100-50-0을 반복.)
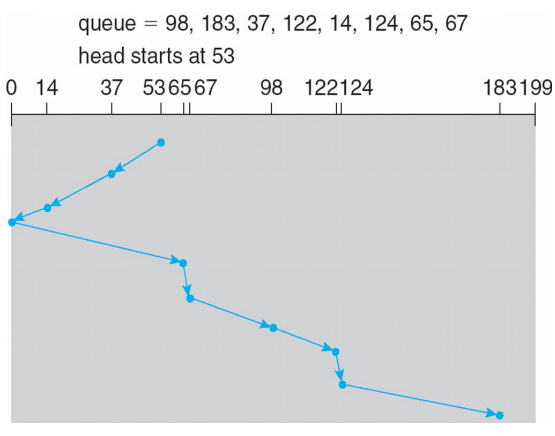
C-SCAN
SCAN처럼 헤드가 한쪽 끝에서 다른쪽 끝으로 이동하며 가는 길목에 있는 요청을 처리하지만, 다른쪽 끝에 도달하면, 방향을 바꾸어 요청을 처리하지 않으면서 바로 다른쪽 끝으로 돌아오는 방법으로, SCAN보다 이동거리는 약간 늘어나지만, waiting time의 편차를 줄일 수 있다.
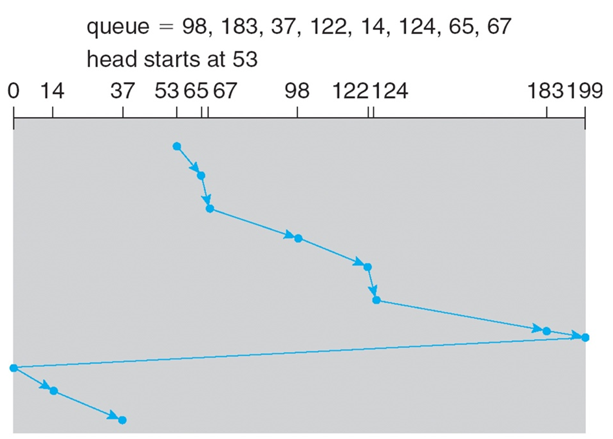
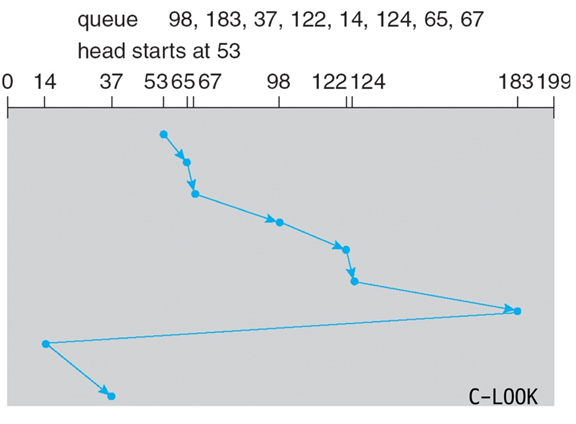
LOOK/C-LOOK
헤드가 한쪽 끝으로 이동하다가 그 방향에 더이상 대기중인 요청이 없으면 방향을 바꾸어 이동하며 요청을 처리하는 방법이다.
어떤 스케쥴링을 고를 것인가?
- SSTF는 흔하고 가장 많이 쓰인다.
- 입출력 요청이 많은 경우 SCAN/C-SCAN이 좋다.
- SSTF나 LOOK이 보통은 합리적인 선택이다.
- 결국 성능은 요청의 개수와 유형에 달려있다.
- 입출력 요청은 file allocation method에 영향을 받는다.
- 현대 디스크들은 스스로 스케쥴링을 한다. 디스크는 운영체제보다 자신의 레이아웃에 대해 잘 안다. 그렇게 때문에 최적화를 잘 할수 있어서 운영체제에서 보낸 스케쥴링 정보를 무시하고 알잘딱 한다.
I/O Scheduler가 해야할 일
- 입출력 요청을 줄이기 위해 요청을 병합하고 디스크 seek time을 줄이고자 요청의 순서를 바꾸거나 정렬함으로써 전반적인 디스크 throughput을 향상시켜야 한다.
- deadline 이전에 요청을 처리함으로써 starvation을 예방해야 한다.
- 프로세스간에 공정하게 요청을 처리해야 한다.
- Quality of Service(QOS)를 보장해야 한다.
플래시 메모리
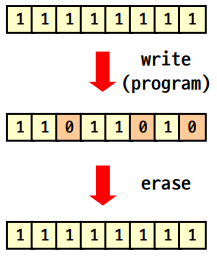
비휘발성, 높은 밀도를 갖는다. 4KB씩 read를 하고 write(set 0)하기 전에 erase(set 1)한다. read가 write/erase보다 빠르다.
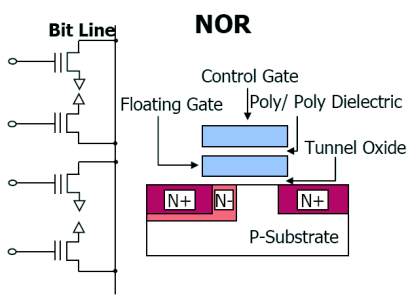
NOR Flash
- 랜덤하고 직접 인터페이스에 엑세스 한다.
- 병렬처리 구조이고 주로 code영역을 저장한다.
NAND Flash
- 직렬처리 구조(Serial structure)이고 cell 사이즈가 작다.
- 비용이 적고 erase 블록의 사이즈가 작고 erase와 write의 성능이 좀 더 좋다.
- 주로 data영역을 저장한다.
**속도 single이 가장 빠름

SSD
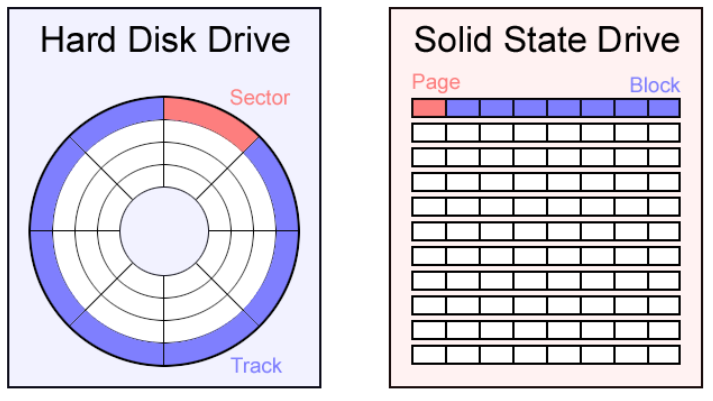
FTL
NAND 플래시가 기존 블록 장치를 완전히 모방하도록 만드는 소프트웨어 계층
