
DML
- tuple 삽입 (insert)
INSERT INTO 테이블명(column1, column2,,) VALUES(tuple1, tuple2,,,);
++참고로, foreign key가 있을 때, parent relation에 먼저 데이터 넣어야 함.- tuple 수정 (update)
UPDATE 테이블명 SET attr1=val1, attr2=val2,,, WHERE 조건
- tuple 삭제 (delete)
DELETE FROM 테이블명 WHERE 조건
- tuple 가져오기 (select)
++DISTINCT : 중복 없이 한번씩만
++<>는 !=임
++WHERE에 조건 여러개를 AND, OR, NOT 사용해서 넣을 수 있음
++WHERE의 LIKE 사용법--A로 시작하는 문자를 찾기-- SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE 'A%' // --A로 끝나는 문자 찾기-- SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE '%A' // --A를 포함하는 문자 찾기-- SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE '%A%' // --A로 시작하는 두글자 문자 찾기-- SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE 'A_' // --첫번째 문자가 'A''가 아닌 모든 문자열 찾기-- SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE'[^A]' // --첫번째 문자가 'A'또는'B'또는'C'인 문자열 찾기-- SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE '[ABC]' SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE '[A-C]'++WHERE의 IN(데이터1, 데이터2,,,) 해당되는 데이터의 tuple
++AS는 attribute의 별칭을 지정할 때 사용한다.
++ 몇 가지 함수들을 통해서 데이터를 조작하여 보여줄 수 있다.




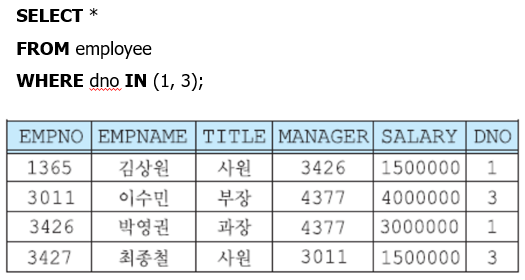
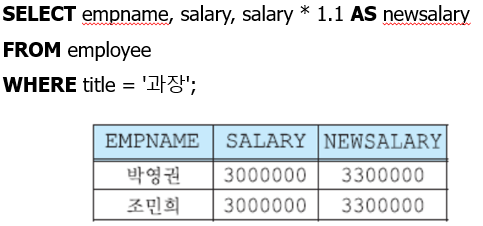


GROUP BY
어떤 attribute에 같은 값을 가진 tuple들을 그룹으로 묶을 때 사용된다.
GROUP BY는 보통 COUNT, SUM, AVG, MAX, MIN의 aggregation 함수와 함께 사용된다.
- 예제)
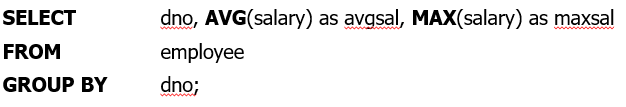
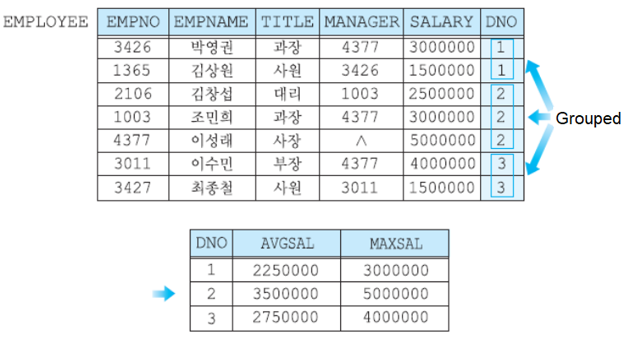
HAVING
GROUP BY로 그룹화 된 데이터에 조건을 걸 때 사용된다.
- 예제)
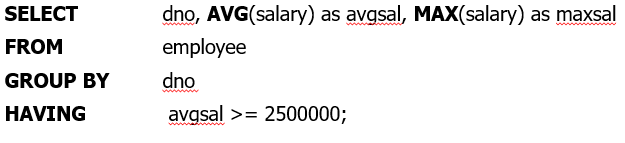

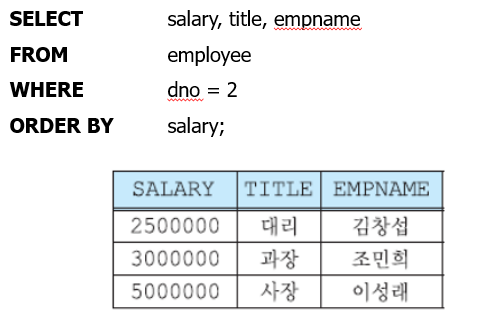
ORDER BY
데이터를 오름차순(ASC), 내림차순(DESC)으로 정렬하고 싶을 때 사용된다. 오름차순이 디폴트 값. ++NULL은 오름차순에서 가장 먼저 나옴. (가장 작은 값)
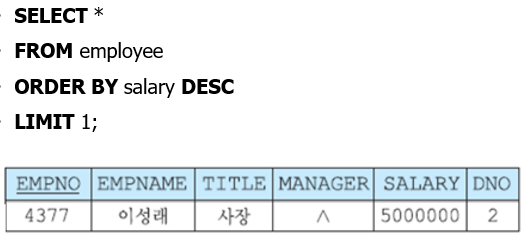
LIMIT
데이터의 갯수를 측정할 때 사용된다. tuple 수가 많을 때 효과적이다.

Record What I Learned