Decoding 은 주어진 input 문장에 대해 translation을 생성하는 과정이다. Training 과정에서 보통 한번에 한 단어씩 예측하게 된다. 모델의 확률 분포로 주어진 선택할 수 있는 단어가 많기 때문에 가능한 output sequence의 space가 지수적으로 크다. (= 너무 크다) Best sequence 를 찾기 위해 어떻게 search problem을 다루는지 살펴보자.
- Beam Search
- Ensemble Decoding
- Reranking
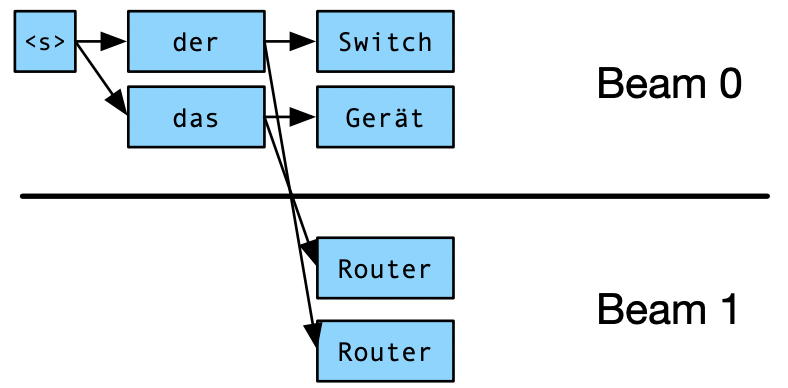
1. Beam Search
2. Ensemble Decoding
Ensemble 은 주어진 task에 대해 하나의 시스템만 만드는 것이 아니라, 여러개를 만들고 모두 combine하는 것이다. 기계번역에 ensemble을 적용하기 위해서는 두가지 sub-problem 을 해결해야 하는데, (1) alternate system을 만드는 것과 (2) output을 합치는 것이다.
(1) Generating Alternative Systems
NMT (Neural Machine Translation) 모델을 훈련할 때, 멈추는 기준에 도달할 때까지 반복한다. 이때 여러 모델을 훈련하기 위한 두가지 방법이 있는데, 다른 random initialization을 사용하는 Multirun Ensemble 과 다른 checkpoint 의 model을 선택하는 Checkpoint Ensemble 이다.
-
Multirun Ensemble: weight에 다른 random initailization 을 줌으로써 다른 local optima 를 찾도록 한다.

-
Checkpoint Ensemble: training 할 때 다른 checkpoint의 모델들을 선택한다.

(2) Combining System Output
combination은 output word의 확률 분포 prediction의 평균을 사용한다. Averaged distribution이 output word를 선택하는 기준이 된다.
3. Reranking
(1) Reranking with Right-to-Left Decoding
ensemble 방법을 확장해서, 서로 다른 random initialization 을 사용하는 대신 하나의 system 을 만들고 output sentence 의 순서를 거꾸로 한 system 도 만든다. 여기서 두번쨰로 거꾸로 만든 system 을 right-to-left system 이라고 한다. 이 두개의 left-to-right (L2R) 와 right-to-left (R2L) system 을 합치기 위해서 reranking 해야한다. Right to Left Reranking 방법은 다음과 같다.
(1) L2R 과 R2L 모델을 둘다 train 시킨다.
(2) 둘 다에 대해서 sentence에 score를 매긴다.
(3) 각 candidate에 대해서 다른 모델들의 score를 합친다 (simple average); 각 input sentence에 대해 best score 선택
(2) Reranking with Reverse Models
전통적인 통계적 기계번역은 Bayse rule을 사용했다.
- Language Model
- trained on monolingual target side data
- can already be added to ensemble decoding
- Reverse Translation Model
- train a system in the reverse language direction
- used in reranking
(3) Increasing Diversity of the n-Best List
NMT 모델에 Beam Search 를 사용할 때 beam size를 5~20 정도로 작게 사용하는 경우가 많기 때문에, 생성된 n-best list 가 보통 작다. 게다가 n-best list 가 서로 비슷하다. 따라서 선택할 수 있는 다양한 translation set 을 만드는 것이 중요하다. 다양한 n-best list를 만들기 위한 여러 시도들을 설명한다.
- Monte Carlo Decoding
- beam size = 1 로, beam 을 확장해서 단어를 선택할 때 확률에 따라 단어를 랜덤하게 선택한다.
- Adding a Diversity Bias Term
- second best, third best, 등등에 panelty를 적용하는 방법이다.
- 단어 선택의 rank에 따라 cost 를 더해주는 방법으로, 가장 가능성있는 단어에는 cost가 없고, 두번째로 가장 가능성있는 단어에는 cost = c, 세번째로 가능성있는 단어에는 cost = 2c, ... 이런식으로 cost를 준다.
- 다른 hypotheses 에도 확장할 수 있게 해주기 위한 방법이다.
(4) Learning a Diversity Bias Term
-
Minimum error rate training (MERT)
- 모든 weight에 대해서 한번에 하나의 weight만 optimize하고 나머지 weight는 고정해놓는다. targeted weight에 작은 변화는 큰 차이를 만들지 않는다.(?)
-
Pairwise Ranked Optimization (PRO)
- n-best list 로 부터 두개의 후보를 선택해서 component score, quality score에 따라 어떤 번역이 더 좋은지 알 수 있다. 이를 사용해서 classification task 를 할 수 있도록 linear classifier를 학습하면 이렇게 얻은 weight를 reranker 에 쓸 수 있다.
Reranking 방법은 NMT 에서 자주 쓰이지는 않다. reranking은 SMT 에서 더 잘 쓰인다.
4. Constraint Decoding
rule-based translation of dates, quantities, interactive translation prediction 또는 특정하게 단어 순서를 따르는 상황과 같이 decoding decision을 override 하고 싶은 경우가 있다. 이런 경우에 대해 살펴본다.
- XML Schema
-
위에서 말한 constraint sms XML markup language에 적용해줄 수 있다.

-
위 XML 코드의 의미는
- router 는 Router 로 번역해야,
- The router is 는 나머지 뒷 부분보다 먼저 번역되어야,
- Psy X500 Pro 는 하나의 unit으로 번역되어야 한다는 의미다.
-
XML tag를 쓰면 해당하는 부분은 항상 override된다.
-
- Grid Search
- NMT decoding에서 translation constraint 를 통합하기 위한 방법이다.
- decoding constraint 를 만족한 것들을 기반으로 여러 beam을 사용한 것이다.
[Reference]
Machine Translation Lecture of Johns Hopkins University https://youtu.be/0DsWLXNIxeA
