Neural Machine Translation Baseline with HuggingFace
This is step of Machine Translation assignment.
- Clone the Transformers repository and install required libraries if necessary.
git clone https://github.com/huggingface/transformers.git- Read and understand an example script for using the library. The README file will guide you to run the script. Try running a pre-trained MarianMT model (Helsinki-NLP/opus-mt-{src}-{tgt}) model for the language pair of your choice. Run translation on the Tatoeba test sets.
(1) To run translation with Tatoeba test sets, give "--dataset_name" parameter with "Helsinki-NLP/tatoeba_mt". Also modify language pair to my choice.
!python transformers/examples/pytorch/translation/run_translation.py \
--model_name_or_path Helsinki-NLP/opus-mt-ko-en \
--do_predict \
--source_lang ko \
--target_lang en \
--dataset_name Helsinki-NLP/tatoeba_mt \
--dataset_config_name eng-kor \
--output_dir /.../tst-translation \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate(2) Tatoeba 데이터로 돌리려는데 데이터 처리 과정에서 자꾸 에러가 났다. 해당 데이터의 attribute가 본 코드와 맞지 않아서 생긴 문제인 걸로 확인하고 코드를 수정하니, evaluation (--eval), test(--do_predict) 가 돌아갔다.
# tatoeba_mt Dataset feature
Dataset({
features: ['sourceLang', 'targetlang', 'sourceString', 'targetString'],
num_rows: 2399
}) 
(3) test("--do_predict") 로 돌리면 다음과 같이 결과를 확인할 수 있다. 오른쪽은 번역 결과이다.
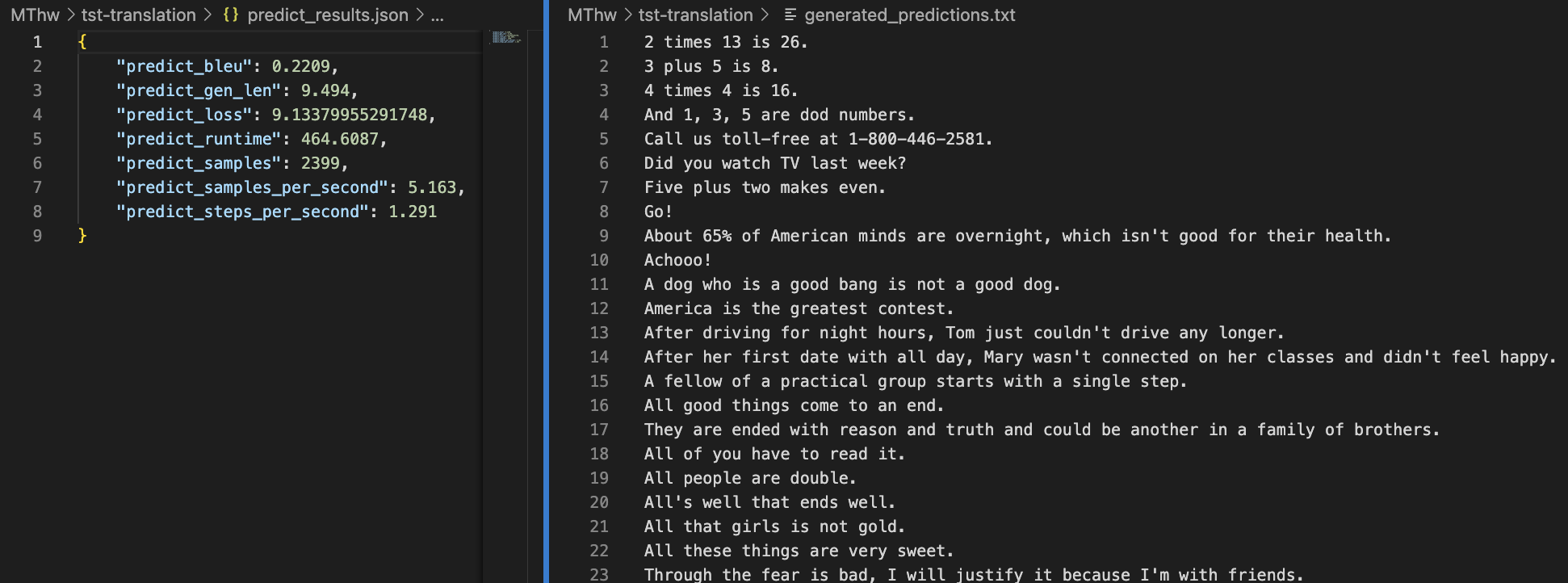
cf. ValueError가 뜨면 맞춰라고 하는대로 config name을 맞춰주면 된다. 예를 들어 영어-한국어면 "--dataset_config_name" parameter를 "eng-kor" 로 해준다.
cf. check_min_version() error 가 뜨면 버전을 확인해주자.
- Prepare data for your language pair. Use the following:
Korean-English: 한국어-영어 번역(병렬) 말뭉치 Link
Korean-German: TED 2020 v1 => Search for ko-de in Link and find “TED 2020 v1”
한국어-영어번역 말뭉치는 엑셀파일, 한국어-독일어 데이터는 tmx 파일로 된 데이터이다. 이 데이터들을 json 으로 바꾸어준다.
cf. tmx 파일 파싱 참고

공부해서 남주자