📝오늘 배운 것
💡 네이버 요일별 웹툰을 크롤링하여 csv 파일로 저장하기
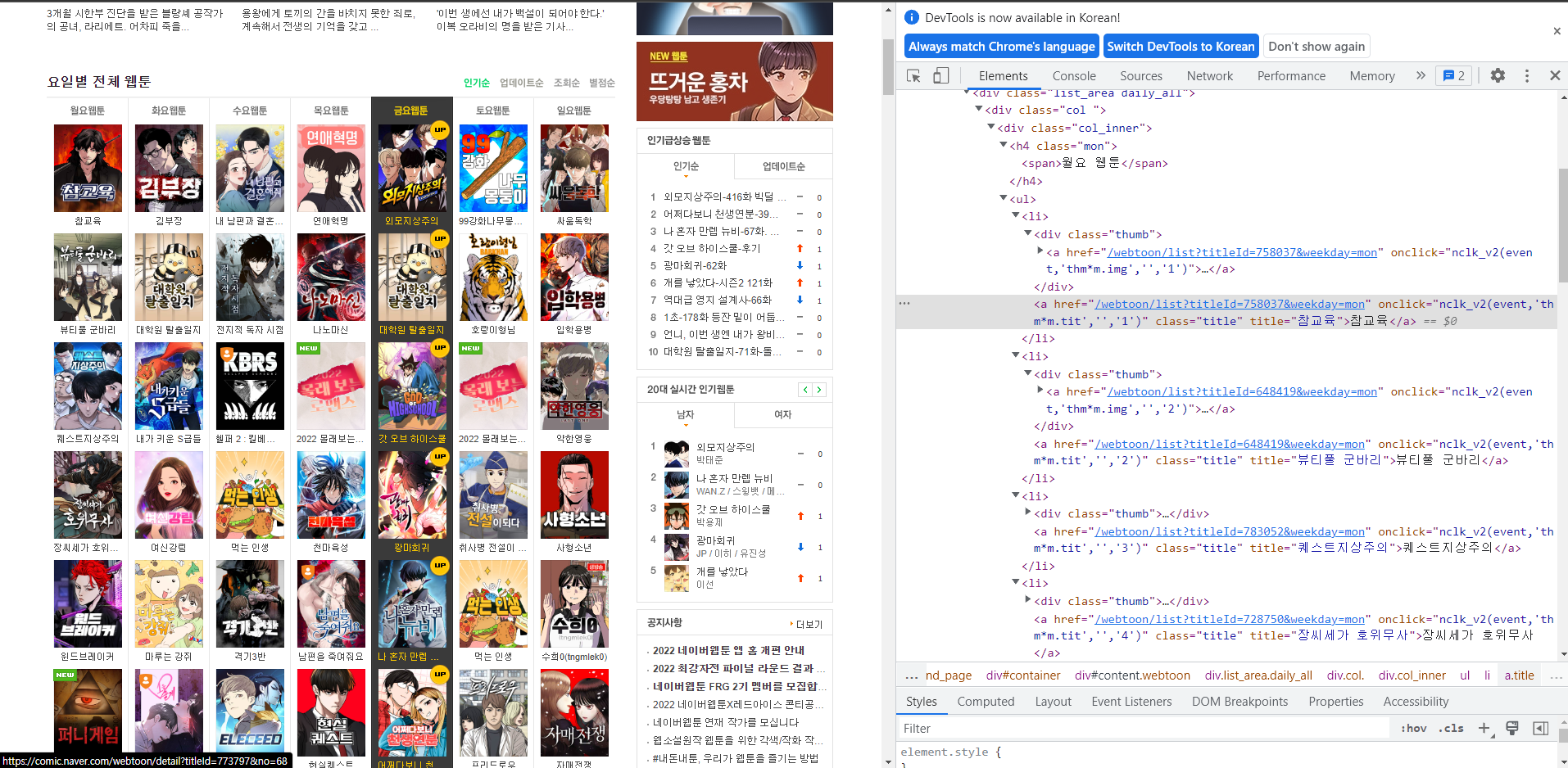
처음에는 selenium을 사용하지 않고 requests와 BeautifulSoup으로 크롤링을 처음 시도하면서 해당 페이지의 이미지, 요일, 타이틀만 가져오다가 문득 필요한 정보가 웹툰의 상세 정보에 있다는 것을 자각하고 동적인 웹페이지의 정보들을 어떻게 하나하나 가져올지 고민에 빠졌다.
해답을 찾기 위해 구글링을 하다가 selenium의 webdriver를 실행해서 url을 설정하고, 대상 url에서 class 이름이 title(클릭했을 때 상세페이지로 이동하는 객체)를 for roof로 반복하여 추출하고자 하는 빈 리스트에 담아 pandas로
csv 파일을 생성할 수 있었다.
정적인 웹페이지에서만 크롤링해보다가 동적인 웹페이지를 크롤링해보니 엄청 신기했다.
내 느낌상 크롤링은 나중에도 많이 쓰일 것 같아 동적인 웹페이지를 크롤링하여 csv 파일로 저장하는 방법을 많이 연습해서 익혀둬야 할 것 같다.
from selenium import webdriver
from bs4 import BeautifulSoup as bs
from time import sleep
from selenium.webdriver.common.by import By
import pandas as pd
import os
def get_naver_webtoon_info():
# chromedriver로 웹툰 페이지 열기
url = 'https://comic.naver.com/webtoon/weekday'
driver_url = 'C:/Users/규현/Desktop/crawlling-test/chromedriver'
driver = webdriver.Chrome(driver_url)
driver.get(url)
# 클릭이 가능한 웹툰의 제목 리스트 가져오기
titles = driver.find_elements(By.CLASS_NAME, 'title')
# 필요한 정보의 빈 리스트 만들어 놓기
id_list = []
title_list = []
day_list = []
genre_list = []
story_list = []
webtoon_url_list = []
thumbnail_url_list = []
webtoon_id = 0
for i in range(len(titles)):
# i(현재 진행 상황)와 titles(전체 개수)를 print해서 진행상황을 process로 출력
print("\rprocess: " + str(i + 1) + " / " + str(len(titles)), end="")
sleep(0.5) # 웹페이지가 로딩되기도 전에 코드가 실행되는 것을 방지하기 위한 기다림
# 0번째 웹툰, 즉 월요일 첫번재 웹툰부터 클릭해서 해당 페이지로 이동하기
titles = driver.find_elements(By.CLASS_NAME, "title")
titles[i].click()
# 이동한 페이지의 html 코드 가져오기
html = driver.page_source
soup = bs(html, 'html.parser')
# 제목 정보 가져오기
title = soup.find('span', {'class': 'title'}).text
# 요일 정보 가져오기
day = soup.find('ul', {'class': 'category_tab'})
day = day.find('li', {'class': 'on'}).text[0:1]
# 만약 연재 요일이 2개 이상이라서 이미 저장했던 웹툰이라면 요일만 추가하고 넘어가기
if title in title_list:
day_list[title_list.index(title)] += ', ' + day
driver.back()
continue
# 나머지 정보 수집하기(장르, 스토리, 썸네일)
genre = soup.find('span', {'class': 'genre'}).text.split(", ")[1]
story = soup.find('div', {'class': 'detail'}).find('p').text
thumbnail_url = soup.find('div', {'class': 'thumb'}).find('a').find('img')['src']
# 정보들을 리스트에 담기
id_list.append(webtoon_id)
title_list.append(title)
day_list.append(day)
genre_list.append(genre)
story_list.append(story)
webtoon_url_list.append(driver.current_url)
thumbnail_url_list.append(thumbnail_url)
# 뒤로 가기
driver.back()
webtoon_id += 1
sleep(0.5)
total_data = pd.DataFrame()
total_data['id'] = id_list
total_data['title'] = title_list
total_data['day'] = day_list
total_data['genre'] = genre_list
total_data['story'] = story_list
total_data['webtoon_url'] = webtoon_url_list
total_data['thumbnail_url'] = thumbnail_url_list
# 따로 인덱스를 생성하지 않고 id를 인덱스로 정하기
total_data.set_index('id', inplace=True)
# CSV 파일로 저장하기
total_data.to_csv("naver_webtoon.csv", encoding='utf-8-sig')
naver_webtoon_filename = "naver_webtoon.csv"
if os.path.isfile(naver_webtoon_filename):
# 파일이 있다면 웹 크롤링 하지 않고 읽어오기
total_data = pd.read_csv(naver_webtoon_filename, encoding='utf-8-sig')
else:
# 파일이 없다면 웹 크롤링 하기
total_data = get_naver_webtoon_info()
# CSV 파일로 저장하기
total_data.to_csv("naver_webtoon.csv", encoding='utf-8-sig')
웹개발 회고록