
요즘에 대규모 트래픽을 다루는 어플리케이션들이 많아지는 추세이다. 많게는 초당 10000건의 트래픽 또는 그 이상의 트래픽을 처리해야하는 시대가 온 것이다. 그러면 사용자와 커넥션을 맺을 때 마다 쓰레드를 생성하게 되면 많은 비용(Context Switching 혹은 Thread 생성하는 Cost)이 들 것이다. 그래서 어떻게 하면 효율적으로 처리가 가능한지 알아보는 도중에 Non-Blocking 이라는 개념이 많이 나와서 실제로 어떻게 동작하는지 궁금해서 어떻게 동작하는지 알아보고자 이 글을 작성하게 되었다. 어플리케이션 영역에서 Thread로 우리가 작업해야할 흐름을 제어하게 되는데 이러한 작업 흐름을 운영하는 방식을 Blocking ,Non-Blocking 두가지 방식으로 볼 수 있다. 일단 Blocking과 Non-Blocking에 대한 개념부터 알아 보도록 하자
Blocking
Blocking은 사전적 의미로 막다라는 의미를 가지고 있는데 어플리케이션관점으로 보자면 한 작업흐름이 실행되었을 때 중간에 어떤 작업이 실행이 되었을 때 해당 작업 흐름을 실행된 작업이 끝날때 까지 기다리는 것이다. 즉 쓰레드를 Blocking 시키는 것이다.
Blocking으로 처리하는 작업은 두가지로 나뉜다.
- Cpu-Bound-Blocking
- Io-Bound-Blocking
Cpu-Bound-Blocking 부터 알아보자면 Cpu-Bound는 Cpu를 주로 사용하는 작업들을 말한다. 복잡한 수학적인 연산, 3D 모델 렌더링 같은 작업을 뜻한다. 그러면 어떤식으로 Blocking을 시키는지 그림으로 알아보자
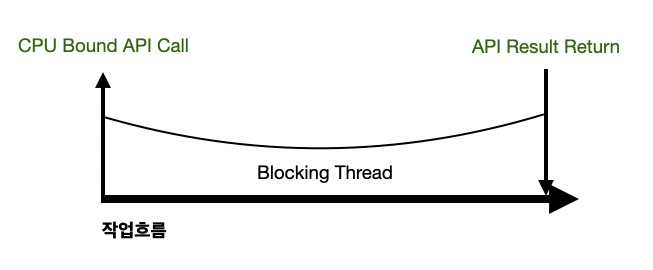
CPU Bound Api를 호출하게 되면 Api에서 결과를 전달 받을 때까지 작업흐름이 Blocking 되는걸 알 수 있다. 이때 쓰레드는 CPU에 의해 능동적으로 작업되기 때문에 프로세서에 의해 해당 쓰레드가 Blocking 되는 것이다.
IO-Bound 작업은 Network IO 작업, File IO 작업 등등 여러 IO 작업 들을 뜻한다. 이 때 어떻게 Blocking 되는지 아래 그림으로 알아 보도록 하자
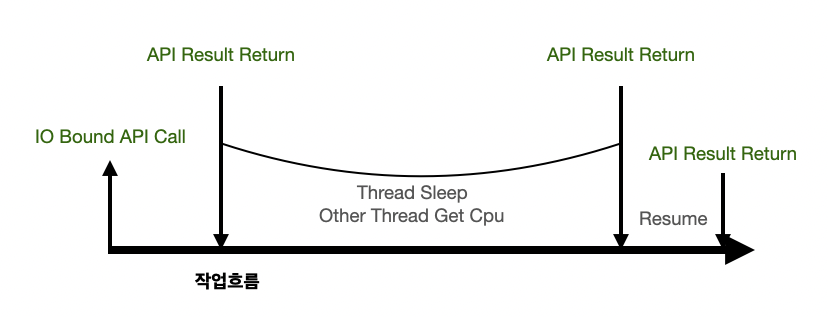
IO Bound Api를 호출하게 되면 커널 으로 부터 현재 바로 처리 될수 없으니 Thread Sleep 상태로 전환 되어 해당 쓰레드는 중지 상태가 된다. 그리고 해당 쓰레드는 중지 되었기 때문에 다른 Thread가 Cpu를 얻을 수 있는 상태가 된다. 그리고 IO 요청에 대한 결과를 받고 나서 다시 Thread가 재개 상태가 되어 작업을 이어간다 즉 프로세서에 의해 Blocking 되는 것이 아니라 커널에 의해 Blocking으로 처리되는걸 볼 수 있다.
Blocking에 대해 알아 보았는데 많은 요청이 들어왔을 때는 그 요청 만큼 Thread가 생성 되기 때문에 많이 비효율적이 라는 생각이 든다.
Non-Blocking
그럼 Non-Blocking은 뭐냐고 생각이 들게 된다. 사실 Blocking과는 크게 다르지 않다 Thread를 통해 작업을 하는 것도 그렇고 다만 Thread를 효율적으로 생성하고 이용하는 방식이라고 보면 될 것같다. 즉 모든 요청에 대해 하나씩 쓰레드를 생성하는게 아닌 작업량에 맞게 효율적으로 Thread를 생성하는 방식이라 보면 될 것 같다. 대표적으로 코루틴이 Non-Blocking 매커니즘을 사용한 예 이다.Non-Blocking이 어떻게 동작하는지 알아보도록 하자
일단 Non-Blocking의 핵심 개념에 대해서 알아보자면 어떤 요청을 보냈을 때 그 작업이 제대로 처리되었는지 처리되지 않았는지 여부를 따지지 않고 바로 값을 return 시키는 방식으로 해당요청이 완료될 때 까지 기다리지 않고(Blocking) 하지 않고 해당 작업흐름을 그대로 유지할 수 있다. 그러면 요청에 대한 결과값이 준비가 되었다고 알려줄 방법이 있어야하는데 그 방식은 Event Loop, HardWare Interrupt 이 두 방식이 있다. Event Loop는 쉽게 말하면 While(true) 이렇게 계속 돌면서 완료되었냐? 이렇게 체킹 하는것이고 HardWare Interrupt는 특정 작업이 완료되면 물리적인 인터럽트를 일으켜 작업이 완료되었다고 전달 할 수 있다. 하지만 HardWare Interrupt는 많은 유저가 사용하는 어플리케이션에는 적합하지 않다. 왜냐면 interrupt가 일어나면 프로세스가 멈추기 때문이다. 그래서 보통 Event Loop 방식을 사용한다.
그래서 요청마다 쓰레드를 생성할 필요가 없어지게 되는 것이다. 그래서 Blocking 방식보다 효율적일 수 있다고 볼 수 있다. 물론 요청마다 Event Loop에 추가 되어 계속 돌게 되면 효율이 떨어지지 않느냐 라고 생각 할 수 있는데 이걸 보완해서 Event가 존재하지 않으면 더 이상 돌지않게 하는 등 여러가지 효율적인 방식들이 있다. 이것에 대해서는 직접 찾아보는게 좋을 것 같다.
