명함을 데이터화 하는 시도 중 주소가 문제가 생겼다. 주소라고 함은,
우편번호 + 도로명 주소(지번 주소) + 상세주소 + 회사명(가끔) 으로 구성되어 있는데, 이걸 어떻게 나누지? 라는 고민이 생겼다.
정규식으로 나누자니 지번이 문제였다.
영동대로 85길 34 (대치동 944-21) 처럼 도로명 주소와 지번주소가 혼재한 경우, 이를 구분할 수 있는지.
등 여러 상황을 고려해야 했었다.
이에 다른 방법을 고안하던 중 정부 공식 API를 확인하였다.
실제 실무에서도 사용가능한 API로 내가 원하던 주소를 시, 행정동, 도로명주소 등으로 구분해줌과 동시에 영문명도 원활히 번역해준다..!
그러나 상세주소가 보존이 안되는 문제가 있었음.
상세주소를 보존하기 위해 LG에서 만든 오픈llm인 exaone3.5:32b를 사용하기로 함. 입력받은 주소를 도로명주소, 상세주소 부분으로 나눈 뒤에 도로명 주소만 API에 넣어 분류 받기로 함.
도로명 주소 API를 이용
https://business.juso.go.kr/addrlink/main.do?cPath=99MM
영문주소 검색 API 샘플: https://business.juso.go.kr/addrlink/addrEngApi.do?currentPage=1&countPerPage=10&keyword=강서로7길&confmKey=TESTJUSOGOKR&resultType=json
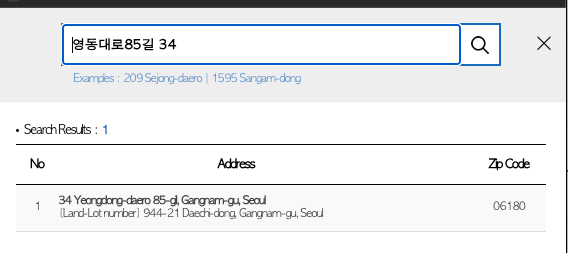
한글, 영어 주소 모두 지원함
일 호출 제한: 미정
제한사항: 상세주소가 날라감 (예: 스파크플러스 10층)
추후 구현: 지도 API를 활용하여 좌표도 넣을 수 있을 것으로 판단됨
영문 주소를 영문주소 검색 API에 넣어 파싱함.

이런식으로 한국어로 된 주소가 최종적으로 영어로 번역된 후 파싱이 되는 것을 확인할 수 있음.
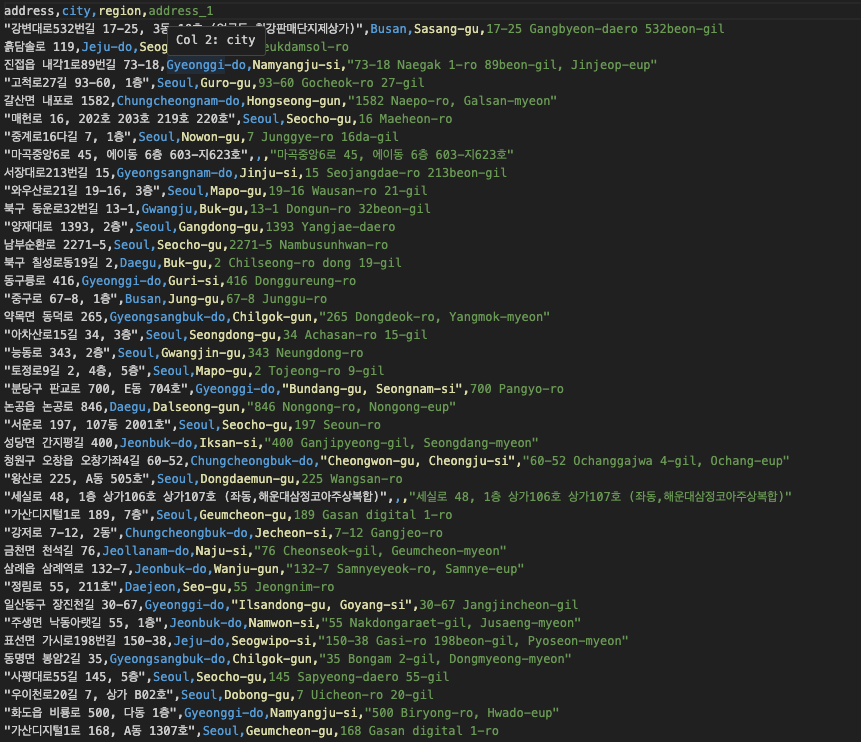
속도도 즉시 되고, 빠른 것을 확인할 수 있음. 다만 상세주소가 빠져 있음.
추가 구현)
현재 코드로는 상세주소가 제외되어 있음. 예시로,
-
A동 404호
-
2동
-
1층
-
(좌동, 해운대삼정코아주상복합)
-
에이동 6층 603-지623호
ollama로 주소 분류 작동 시
model: exaone3.5:32b
https://ollama.com/library/exaone3.5:32b
주소의 경우 서울특별시/서울/서울시 등 입력이 다양하게 들어올 수 있고, 이를 경우의 수로 나누기엔 수가 많아 한국어-영어 특화모델은 exaone3.5를 이용하기로 함. 기존 야놀자 보다 우수한 성능을 갖고 있으며 정확도도 높음.

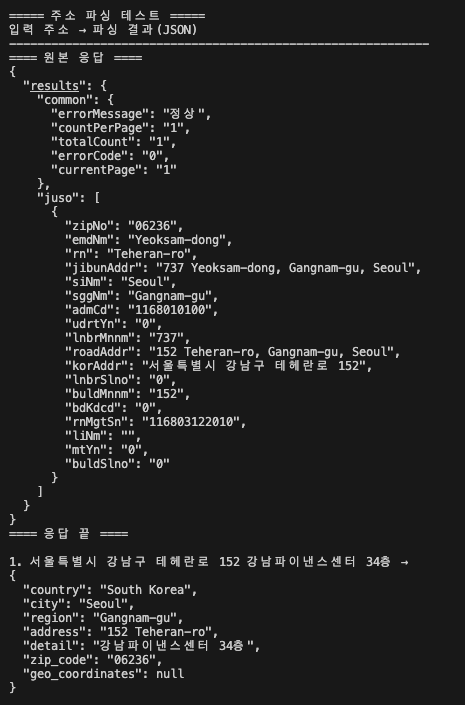
ollama로 분류 작동하지 않을 때.
주소 분리 기능
extract_detail_address 함수는 전체 주소를 도로명 주소와 상세주소 두 부분으로 분리.
def extract_detail_address(full_address):
"""
전체 주소에서 도로명 주소와 상세주소를 분리합니다.
Args:
full_address (str): 전체 주소 문자열
Returns:
tuple: (도로명 주소, 상세주소)
"""이 함수는 다양한 알고리즘과 정규식 패턴을 사용하여 정확한 분리를 보장.
도로명 주소 패턴 인식
행정구역 인식
행정구역명은 주소의 중요한 구성요소로, 다음과 같은 패턴으로 인식:
-
시, 도, 군, 구, 읍, 면, 동 등의 행정구역 키워드
-
행정구역명 추출 정규식: ((?:\S+)?(?:시|도|군|구|읍|면|동)(?:\s+|$))
도로명 주소 패턴
한국 도로명 주소는 다음과 같은 다양한 형태로 존재:
-
기본 도로명: XX로, XX길, XX대로
-
번길 형태: XX로XX번길, XX길XX번길
-
행정구역 포함: 북구 XX로, 분당구 XX로
-
건물번호 포함: XX로 123, XX길 45-67
이러한 다양한 패턴을 정교하게 인식하기 위해 6개의 주요 정규식 패턴을 적용:
road_patterns = [
# 1. [행정구역] [도로명][번길] [번호] 패턴 (예: 북구 칠성로동19길 2)
r'((?:\S+)?(?:시|도|군|구|읍|면|동)\s+\S+(?:로|길|대로)(?:\S+)?(?:번길|번로)?\s+\d+(?:-\d+)?)',
# 2. [도로명][번길] [번호] 패턴 (예: 칠성로동19길 2, 가시로198번길 150-38)
r'(\S+(?:로|길|대로)(?:\S+)?(?:번길|번로)?\s+\d+(?:-\d+)?)',
# 추가 패턴들...
]상세주소 추출 알고리즘
상세주소 추출은 다음과 같은 순서로 이루어짐:
-
쉼표 분리: 쉼표(,)로 구분된 주소 처리 (예: "고척로27길 93-60, 1층")
-
괄호 처리: 괄호가 포함된 주소 처리 (예: "강변대로532번길 17-25 (엄궁동)")
-
도로명 패턴 인식: 정규식을 통한 도로명 주소 패턴 인식
-
키워드 기반 분리: 특정 키워드(동, 층, 호 등)를 기준으로 한 분리
-
공백 기준 분리: 번지 형태를 찾아 공백을 기준으로 분리
-
숫자 기준 분리: 첫 번째 숫자 뒤로 분리
각 단계는 이전 단계에서 분리에 실패했을 경우에 시도.
처리 가능한 주소 패턴
이 파서는 다음과 같은 다양한 주소 패턴을 처리할 수 있음:
- 쉼표로 구분된 상세주소
-
예: "고척로27길 93-60, 1층"
-
결과: "고척로27길 93-60" + "1층"
- 괄호가 포함된 주소
-
예: "강변대로532번길 17-25 (엄궁동,철강판매단지제상가)"
-
결과: "강변대로532번길 17-25" + "(엄궁동,철강판매단지제상가)"
- 행정구역이 포함된 주소
-
예: "북구 동운로32번길 13-1"
-
결과: "북구 동운로32번길 13-1" + ""
- 복합 행정구역 주소
-
예: "청원구 오창읍 오창가좌4길 60-52"
-
결과: "청원구 오창읍 오창가좌4길 60-52" + ""
- 번길/번로가 포함된 주소
-
예: "표선면 가시로198번길 150-38"
-
결과: "표선면 가시로198번길 150-38" + ""
- 동/층/호 정보가 포함된 주소
-
예: "양재대로 1393, 2층"
-
결과: "양재대로 1393" + "2층"
- 복합 상세주소
-
예: "토정로9길 2, 4층, 5층"
-
결과: "토정로9길 2" + "4층, 5층"
주소 배열 처리
주소 데이터는 다음과 같이 처리됨:
- 데이터 구조: 모든 주소는 배열(List[Dict]) 형태로 관리됨. 각 주소는 중첩 JSON 구조로 저장됨:
# 주소 정보 구조
location_info = {
"country": "South Korea",
"city": juso_eng.get('siNm', ''),
"region": juso_eng.get('sggNm', ''),
"address": address, # 도로명+건물번호 조합
"detail": detail_addr_eng, # 분리된 상세 주소
"zip_code": zip_code,
"geo_coordinates": None
}- 처리 파이프라인:
process_address_parsing함수에서 구현됨:
# 영어 주소와 한글 주소를 모두 처리하여 단일 location 필드로 통합
def process_address_parsing(df: pd.DataFrame) -> pd.DataFrame:
results = [] # 모든 처리 결과를 저장할 리스트
eng_indices = {} # address_eng 결과의 인덱스를 저장
nat_indices = {} # address_nat 결과의 인덱스를 저장
# 1. 영어 주소 처리
if 'address_eng' in df.columns and df['address_eng'].notna().any():
eng_addresses = df['address_eng'].dropna().tolist()
# 영어 주소 파싱 로직...
# 2. 한글 주소 처리
if 'address_nat' in df.columns:
addresses = df['address_nat'].dropna().tolist()
# 한글 주소 파싱 로직...
# 3. 결과를 데이터프레임에 매핑
df_result = df.copy()
df_result['location'] = None
# location 필드에 결과 배열 할당...API 호출 및 주소 분리
주소는 다음과 같이 API를 통해 파싱됨:
도로명/상세주소 분리 (LLM 활용)
def extract_detail_address(address_text, is_korean=False):
# 원본 주소 정리
original_address = address_text.strip()
# Ollama API를 사용하여 도로명 주소와 상세 주소 분리
try:
if is_korean:
road_address, detail_address = call_ollama_for_korean_address_split(original_address)
else:
road_address, detail_address = call_ollama_for_english_address_split(original_address)
if road_address:
return road_address, detail_address
except Exception as e:
logger.warning(f"Ollama API 주소 분리 실패: {e}, 기본 분리 방식으로 전환합니다.")
# API 실패시 백업 로직: 구분자 기반 분리
if is_korean:
separators = ["번지", "층", "호", "#", "동 ", "호 ", "빌딩", "건물", "아파트", "오피스텔"]
else:
separators = ["Floor", "F", "#", "Unit", "Building", "Bldg", "Suite", "Apt", "Room"]
# 구분자를 기준으로 상세 주소 분리
# ...한글 주소 API 호출
def get_korean_address_info(address):
url = 'https://business.juso.go.kr/addrlink/addrLinkApi.do'
params = {
'currentPage': '1',
'countPerPage': '10',
'keyword': address,
'confmKey': JUSO_API_KEY,
'resultType': 'json'
}
try:
response = requests.get(url, params=params)
response.raise_for_status()
return response.json()
except Exception as e:
logger.error(f"한국어 주소 API 호출 오류: {e}")
return None영문 주소 API 호출
def get_english_address_info(address):
url = 'https://business.juso.go.kr/addrlink/addrEngApi.do'
params = {
'currentPage': '1',
'countPerPage': '1',
'keyword': address,
'confmKey': JUSO_ENG_API_KEY,
'resultType': 'json'
}
# API 호출 및 응답 처리...중복 주소 판단 및 처리
중복 주소는 다음과 같은 코드로 식별하고 처리함:
# 영어 주소의 korAddr 값 저장
eng_road_addr = eng_result.get('korAddr', '')
# 한글 주소의 roadAddrPart1 값과 비교
nat_road_addr = nat_result.get('roadAddrPart1', '')
# 중복 검사: 영문 주소의 korAddr과 한글 주소의 roadAddrPart1 비교
is_duplicate = False
if eng_road_addr and nat_road_addr:
# 문자열 정규화 후 비교 (공백, 특수문자 등 제거)
norm_eng = ''.join(c for c in eng_road_addr if c.isalnum())
norm_nat = ''.join(c for c in nat_road_addr if c.isalnum())
is_duplicate = norm_eng == norm_nat
# 중복이 아닌 경우에만 한글 주소 정보 추가
if not is_duplicate:
addresses_info.append(nat_result.get('location_info', {}))LLM 프롬프트 최적화
언어별로 다른 프롬프트를 사용하여 주소 분리의 정확도를 높임:
한글 주소용 프롬프트
def call_ollama_for_korean_address_split(full_address):
prompt = f"""You are a specialized Korean address parsing expert. Your task is to separate a Korean address into two parts:
1. Basic address (도로명 주소): the official road name address part
2. Detail address (상세 주소): the specific building, floor, unit, or other details
Given the following Korean address, return ONLY the two separated parts in the format:
BASIC_ADDRESS|DETAIL_ADDRESS
- If there is no detail address, return just the basic address followed by a pipe symbol.
- Do not provide any explanations or additional text.
- Ensure the combination of both parts is equivalent to the original address.
- RESPOND IN KOREAN. Keep both parts in Korean.
Address to parse: {full_address}"""
data = {
"model": "exaone3.5:32b",
"prompt": prompt,
"stream": False
}
# API 호출 및 응답 처리...영문 주소용 프롬프트
def call_ollama_for_english_address_split(full_address):
prompt = f"""You are a specialized address parsing expert for English-written Korean addresses. Your task is to separate the address into two parts:
1. Basic address: the official road name address part (street name, number)
2. Detail address: the specific building, floor, unit, or other details
Given the following English-written Korean address, return ONLY the two separated parts in the format:
BASIC_ADDRESS|DETAIL_ADDRESS
- If there is no detail address, return just the basic address followed by a pipe symbol.
- Do not provide any explanations or additional text.
- Ensure the combination of both parts is equivalent to the original address.
- RESPOND IN ENGLISH. Keep both parts in English.
Address to parse: {full_address}"""
# 이하 API 호출 코드...최종 결과 저장
모든 주소 정보는 데이터프레임의 location 필드에 JSON 배열로 저장됨:
# 주소 정보가 있는 경우에만 location 필드 설정
if addresses_info:
# 주소 정보의 개수에 상관없이 항상 배열로 저장
df_result.loc[idx, 'location'] = json.dumps(addresses_info, ensure_ascii=False)