프로젝트 배경
2년 차 데이터 엔지니어로서, 명함 OCR 결과 데이터를 처리하는 파이프라인을 개선하는 프로젝트를 수행했습니다. 하루 약 5만 건의 명함 OCR 결과(이름, 회사명, 연락처 등의 텍스트 데이터)가 생성되는데, 초기에는 Python 기반의 전처리 스크립트로 이 데이터를 처리했습니다. 하지만 데이터량이 꾸준히 증가하고 파이프라인 복잡도가 높아지면서, 보다 효율적이고 확장 가능한 처리 방식이 필요해졌습니다. 이에 따라 기존 Python 단일 노드 처리에서 Apache Spark 기반의 분산 처리로 마이그레이션하고, Apache Airflow를 도입하여 DAG 형태로 작업을 자동화 및 관리하게 되었습니다. 이번 포스팅에서는 Spark와 Airflow로 파이프라인을 재구축한 동기와 장점, 전체 아키텍처 구조, 구현 과정에서의 경험, 그리고 확장성을 고려한 설계와 어려움 및 개선 과정을 공유합니다.
Spark 도입 배경과 장점
기존 파이프라인은 Pandas 등을 활용한 Python 스크립트로 구현되어 있어 단일 프로세스 환경에서 작동했습니다. 이러한 방식은 초기 데이터량에서는 문제가 없었지만, 점차 데이터 규모가 커지거나 추가적인 복잡한 연산이 필요해질 경우 처리 지연이나 메모리 한계에 부딪칠 우려가 있었습니다. Apache Spark를 도입한 주요 동기는 대용량 데이터에 대한 분산 병렬 처리와 성능 향상이었습니다 (왜 Spark를 써야할까). Spark의 장점을 정리하면 다음과 같습니다:
- 빠른 처리 속도: Spark는 데이터를 메모리에 캐시하면서 처리하는 최적화된 엔진을 갖추고 있어, MapReduce 등 전통적인 방식보다 10~100배 빠른 처리 성능을 보입니다. (왜 Spark를 써야할까) 대량의 데이터를 반복 연산하거나 집계할 때도 빠르게 결과를 도출할 수 있습니다.
- 분산 및 병렬 처리: 여러 노드에 작업을 분산하고 병렬 처리함으로써 데이터량이 증가해도 수평 확장이 가능합니다. 클러스터 규모를 유연하게 조절하여 하루 5만 건보다 훨씬 많은 데이터도 처리할 수 있는 여력을 확보했습니다.
- 고수준 API 및 유연성: PySpark를 통해 Python으로 친숙한 DataFrame API를 사용할 수 있어서 기존 Python 전처리 로직을 비교적 손쉽게 이식할 수 있었습니다. 또한 Spark는 SQL 형태의 쿼리나 머신러닝 라이브러리 등 다양한 작업을 동일 플랫폼에서 수행할 수 있어 추후 기능 추가에도 유연합니다.
이러한 이점 덕분에 Spark로의 마이그레이션은 처리 성능과 확장성 측면에서 미래에 발생할지 모르는 병목을 미리 해소하고, 대규모 데이터 처리에 대한 대비를 가능하게 했습니다.
Airflow 도입 및 파이프라인 구성
Spark로 데이터 처리 엔진을 교체하는 것과 함께, Apache Airflow를 도입하여 전체 파이프라인의 워크플로우 관리를 구현했습니다. Airflow는 작업들을 DAG로 정의하고 스케줄링 함으로써 복잡한 데이터 파이프라인의 중추적인 오케스트레이션 역할을 담당합니다 (데이터 엔지니어링 핵심 도구 ‘Apache Airflow’ 개념 정리 | 요즘IT). 배치 처리 환경에서 업계 표준이라 할 만큼 널리 쓰이는 도구이며, 의존성 관리, 스케줄링, 모니터링에 강점을 지니고 있습니다. 이를 통해 명함 OCR 파이프라인을 일 배치(batch)로 자동 실행하고, 실패 시 재시도나 알림 설정 등을 체계적으로 관리할 수 있게 되었습니다. (데이터 엔지니어링 핵심 도구 ‘Apache Airflow’ 개념 정리 | 요즘IT).
파이프라인 전체 구조는 다음과 같습니다: 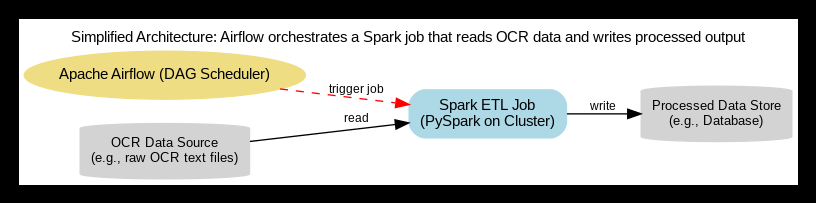
Spark와 Airflow 기반 명함 OCR 파이프라인 아키텍처 개요. 명함 OCR 결과 데이터가 데이터 소스(예: 파일 또는 원시 데이터베이스)에 저장되면, Airflow의 DAG 스케줄러가 Spark 작업을 스케줄링(빨간 실선)합니다. Spark 드라이버/익스큐터로 구성된 분산 엔진이 데이터 소스로부터 원천 데이터를 병렬로 읽어들인 후(검은 화살표) 정제 및 가공을 수행합니다. 처리 완료된 데이터는 최종 데이터 저장소(예: 정형 데이터베이스나 데이터 웨어하우스)에 저장(검은 화살표)됩니다. Airflow는 Spark 작업의 시작부터 완료까지 전체 과정을 모니터링하며, 다운스트림 작업이나 후속 알림 등을 관리합니다.
위 구성에서 사용된 기술 스택을 정리하면:
- 데이터 소스: 명함 OCR 원본 데이터 (예: OCR 엔진에서 출력한 JSON/CSV 파일, S3 버킷 또는 RDB 테이블 등)
- 데이터 처리 엔진: Apache Spark (PySpark 사용) – 분산 데이터 처리 및 ETL 변환
- 워크플로우 오케스트레이션: Apache Airflow – DAG 스케줄링, 의존성 관리, 모니터링
- 인프라 환경: AWS EKS (쿠버네티스) 상에서 운영 계획. 현재는 Spark 클러스터를 독립적으로 사용 중이며, 추후 Spark Operator를 통한 k8s 연동을 고려
- 데이터 저장소: 처리 완료된 명함 데이터가 적재될 장소 (예: PostgreSQL 등의 관계형 DB, 데이터 웨어하우스, 또는 Data Lake의 Parquet 파일)
Airflow 도입으로 얻은 즉각적인 효과는 파이프라인의 가시성 향상과 운영 편의성입니다. Web UI에서 DAG의 실행 상태를 한눈에 모니터링하고, 각 Task의 로그를 추적할 수 있어 문제 발생 시 신속한 디버깅이 가능합니다. 또한 DAG 스케줄을 통해 매일 정해진 시간에 파이프라인이 자동 실행되므로, 사람이 일일이 스크립트를 실행하거나 크론(cron)을 관리하던 번거로움도 없어졌습니다.
구현 상세: Spark 전처리 및 Airflow DAG 구성
이제 실제로 Python 기반 코드를 Spark와 Airflow 환경으로 옮긴 방법에 대해 조금 더 상세히 설명하겠습니다. 크게 Spark 전처리 작업 구현과 Airflow DAG 작성 두 부분으로 나눌 수 있습니다.
-
PySpark 전처리 코드 작성: 기존 Python 전처리 로직을 PySpark로 이식하였습니다. 예를 들어 명함 OCR 결과 데이터는 이름, 회사명, 주소, 전화번호 등의 필드가 문자열로 존재했는데, Spark의 DataFrame을 활용하여 필드별 정규화 및 정제를 수행했습니다. 구체적으로는 잘못 인식된 문자 교정, 불필요한 공백 제거, 연락처 형식 통일 등의 전처리를 했습니다. Pandas에서 하던 작업을 Spark로 옮기는 과정에서 map, filter와 같은 RDD 변환이나 Spark SQL을 활용하여 대량의 데이터를 한꺼번에 처리하도록 구현했습니다. PySpark는 lazy evaluation(지연 실행) 특성이 있으므로, 액션(
collect(),write등)을 호출하여 최종 결과를 저장하면 그제서야 전체 파이프라인이 실행되어 모든 데이터가 처리됩니다. 최종 산출물은 Spark에서 Parquet 파일로 저장하거나 JDBC를 통해 데이터베이스 테이블에 저장하여, 이후 분석 시스템이나 운영 DB에서 활용할 수 있게 했습니다. -
Airflow DAG 구성 및 SparkSubmit 연동: Spark 전처리 코드가 준비되면, 이를 Airflow에서 주기적으로 실행하기 위해 DAG을 작성했습니다. DAG 파일은 Python으로 작성되었으며, SparkSubmitOperator를 활용해 Spark 잡을 제출(submit)하는 Task를 정의했습니다. 예를 들어 DAG 내에
spark_submit_task = SparkSubmitOperator(...)를 구성하여, 배치 스케줄 (매일 새벽 등)에 따라 Spark 작업이 트리거되도록 했습니다. 이 Operator를 사용할 때application경로로 PySpark 스크립트 파일 경로를 지정하고,conf나application_args를 통해 Spark 실행에 필요한 파라미터(예: 입력 데이터 경로, 출력 경로, Spark 설정)를 전달했습니다. Airflow는 이 SparkSubmit Task를 실행하면서 Spark 드라이버를 클러스터에 띄우고, 클러스터 모드로 작업이 수행되도록 했습니다. 의존성이 더 있는 경우 (예: 전처리 후 후속 데이터 적재 작업), 여러 Task를 DAG에서 정의하고 >> 연산자로 의존성을 설정하여 순차 실행되게 구성했습니다. 하지만 우리 파이프라인의 핵심은 하나의 Spark ETL 작업이므로 DAG에서는 단일 Task로 Spark 작업만 수행하고, 완료 후 성공 여부를 모니터링하는 정도로 단순화했습니다. -
테스트 및 최적화: 구현 초기에는 개발 환경에서 소규모 데이터로 Spark 코드와 DAG를 테스트했습니다. Spark 환경 설정 중 메모리 및 코어 할당을 적절히 조정하여 (예:
--executor-memory,--num-executors등) 클러스터 리소스 활용을 최적화했습니다. 명함 5만 건 정도는 Spark 한 대의 드라이버에서도 처리 가능하지만, 향후를 대비해 2~3대의 워커 노드로도 분산 실행해 보며 성능을 점검했습니다. Airflow DAG의 스케줄도 운영 상황에 맞게 설정하여, 업스트림 OCR 시스템에서 하루치 데이터가 준비된 후에 실행되도록 조정했습니다 (예: 매일 0시에 OCR 데이터 적재 완료 -> 1시경 DAG 트리거). 운영 배포 후에는 Airflow 웹 UI와 Spark의 로그/웹 UI(Spark History Server 등)를 통해 잡 수행 시간을 모니터링했고, 초기 Python 스크립트 대비 처리 속도가 크게 개선된 것을 확인했습니다. 또한 Airflow로 전환함에 따라 일별 파이프라인 성공/실패 내역이 기록으로 남아 운영 신뢰성이 높아졌습니다.
확장성과 향후 계획
파이프라인을 설계하면서 특히 확장성(Scalability)을 염두에 두었습니다. 현재는 하루 5만 건 처리 수준이지만, 앞으로 데이터량이 몇 배로 증가할 가능성도 있습니다. Spark 기반으로 전환한 것은 이러한 상황에서도 수평적으로 노드를 추가하는 것만으로 처리량을 감당할 수 있는 구조를 얻기 위해서입니다. Spark의 분산 처리 특성상 데이터 양에 비례하여 클러스터 자원을 늘리면 선형적으로 처리 성능을 향상시킬 수 있으므로, 파이프라인 규모 확장에 유연하게 대응할 수 있습니다. 또한 명함 OCR 데이터 이외에 추가 데이터 소스가 생기거나, 더 복잡한 변환 로직이 추가되더라도 Spark의 다양한 라이브러리 지원으로 일관된 아키텍처 내에서 통합할 수 있습니다. Airflow를 사용한 것도 향후 여러 배치 작업을 중앙에서 관리할 수 있기 때문입니다. 새로운 데이터 파이프라인이 생기면 동일한 Airflow 인스턴스에서 DAG로 관리하여 한 곳에서 모든 배치 작업의 일정을 조율할 수 있습니다.
특히, 향후 계획 중 하나는 쿠버네티스 환경(EKS)에서 Spark 작업을 운영하는 것입니다. 현재는 Spark를 전통적인 방식(예: 독립 Spark 클러스터 또는 EMR 클러스터 등)으로 구동하고 있지만, Spark Operator를 통해 쿠버네티스 상에서 Spark 잡을 관리하는 방안을 검토 중입니다. Spark Operator를 사용하면 쿠버네티스 CRD로 Spark 애플리케이션 정의(SparkApplication)를 제출하여, 필요 시마다 임시 Spark 클러스터(드라이버/익스큐터 Pod들)를 생성하고 작업 완료 후 리소스를 반납하는 형태로 운영할 수 있습니다. 이는 컨테이너화된 Spark 환경을 제공하여 환경 설정을 일관성 있게 만들어 주고, 쿠버네티스의 오토스케일러와 결합하여 필요한 만큼만 리소스를 사용하는 효율적인 운영을 가능하게 합니다. 예를 들어, 한동안 처리량이 낮다면 굳이 많은 Spark 노드를 띄워둘 필요 없이, 잡 실행시에만 Pod를 생성하고 끝나면 자원을 해제함으로써 비용 절감 효과도 얻을 수 있습니다. 현재 Spark Operator 도입은 실험 단계이며, 연동을 위한 Helm 차트 배포와 권한 설정, 그리고 Airflow에서 쿠버네티스 Operator 등을 활용해 DAG에서 SparkApplication을 생성하는 방법 등을 검토하고 있습니다. 완전히 운영 환경에 적용되면, 우리 파이프라인은 쿠버네티스 네이티브하게 동작하여 다른 마이크로서비스 인프라와도 더 밀접하게 통합되고 관리 용이성이 높아질 것으로 기대합니다.
요약하면, 확장성 면에서의 설계 의도는 "데이터나 처리 요구가 증가하더라도 아키텍처 변경 없이 손쉽게 스케일 아웃할 수 있을 것"이었습니다. Spark와 Airflow 조합은 이러한 요구에 부합하도록 선택되었고, 초기 마이그레이션 이후에도 지속적으로 인프라 현대화(예: EKS 활용) 방향으로 발전시켜 나가고 있습니다.
어려웠던 점과 배운 교훈
프로젝트를 진행하면서 몇 가지 도전과제가 있었습니다. 새로운 기술 스택(Spark, Airflow)을 도입하는 과정에서 겪었던 어려움과 해결 방안을 정리하면 다음과 같습니다:
-
Spark API 및 분산 개념 습득: 처음에는 Pandas로 짜여 있던 코드를 Spark의 DataFrame으로 바꾸면서 지연 평가, 변환(transformation)과 액션(action)의 구분 등 Spark만의 개념에 익숙해지는 데 어려움이 있었습니다. 예를 들어,
df.filter().map()등을 호출해도 바로 실행되지 않고, 최종write단계에서 한꺼번에 실행되는 동작 방식 때문에 중간에 의도한 대로 처리됐는지 파악하기가 힘들었죠. 이를 해결하기 위해 Spark UI와 로그를 활용해 각 스테이지별 실행 계획을 확인하고, 작은 샘플 데이터로 반복 테스트하면서 Spark의 실행 흐름을 이해하게 되었습니다. 덕분에 분산 처리에 대한 개념적 이해를 높이고, 코드 최적화 시 어디를 손봐야 할지도 감을 잡을 수 있었습니다. -
환경 설정 및 의존성 관리: Spark 작업과 Airflow가 서로 다른 환경에서 동작하다 보니 라이브러리 의존성 맞추는 것이 이슈가 되었습니다. PySpark 버전과 Airflow 환경의 Python 버전 호환성, Spark 잡에서 사용하는 추가 Python 패키지들을 클러스터 노드에 미리 설치하거나
--py-files옵션으로 배포해야 하는 등의 작업이 필요했습니다. 또한 Airflow의 SparkSubmitOperator를 사용할 때 해당 Operator 플러그인을 설치하고, Spark 클러스터의 마스터 URL, deploy mode 등의 설정을 정확히 지정해야 했습니다. 초기에는 설정 누락으로 잡 제출이 실패하거나, AWS 상에서 권한 문제(IAM Role 등)로 S3에 접근이 안 되는 문제도 발생했습니다. 이런 문제들은 공식 문서와 커뮤니티 자료를 참고하고, 설정을 하나씩 점검하며 해결했습니다. 이를 통해 배포 환경에서의 세심한 설정 관리와 DevOps적인 관점의 경험도 쌓을 수 있었습니다. -
성능 튜닝: Spark로 이전하고 나서도 처음에는 생각보다 속도가 느리게 나오거나 task 분배가 고르지 않게 이루어지는 문제가 발견되었습니다. 원인을 보니 기본 설정으로 실행하면서 파티션 수 조정 등이 최적화되지 않아서 발생한 일이었습니다. 전체 데이터가 5만 건 정도라 작은 편이지만, OCR 결과마다 레코드 크기가 제각각이라 데이터 스큐가 약간 발생하기도 했습니다. 이 문제를 완화하기 위해 입력 데이터를 적절히 repartition하여 작업 부하를 고르게 나누고, 특정 컬럼 기준으로 조인/그룹할 때 salting 기법을 사용하는 등 튜닝을 진행했습니다. (왜 Spark를 써야할까). 그리고 로컬 모드보다 클러스터 모드가 유리한 지점(데이터 양이 클 때)을 파악해 배포 환경에서는 반드시 cluster 모드로 실행하도록 했습니다. 성능 튜닝 과정에서 Spark의 다양한 설정(executor 메모리, 코어 수, 병렬도 등)에 익숙해졌고, 작은 데이터라도 분산 처리 설정에 따라 성능 차이가 있을 수 있음을 배웠습니다.
-
Airflow 운영 및 모니터링: Airflow 도입 후 DAG를 운영하면서 스케줄 관리와 에러 핸들링 측면의 학습곡선도 있었습니다. 예를 들어 처음엔 DAG 스케줄이 의도와 다르게 동작하여 실행 간격이 어긋나는 문제를 겪었는데, 이는 Airflow의 시간대(timezone) 설정과 실행 간격(interval) 개념을 혼동해서 생긴 일이었습니다. 이를 바로잡기 위해 Airflow 문서를 읽고 DAG 정의 시
schedule_interval과start_date를 올바르게 설정했습니다. 또 하나 배운 점은 Task의 원자성과 재실행에 대한 처리였습니다. Spark 작업 중간에 일부 실패가 났을 때, 해당 Task를 재시도하면 데이터 일부분이 두 번 처리될 수 있는 문제를 인지하고, idempotent(멱등)하게 동작하도록 Spark job을 개선했습니다. 예를 들면, 출력 결과를 덮어쓰지 않고 분할 처리 후 커밋하거나, 처리 전에 대상 날짜의 기존 데이터를 지우는 방식으로 재실행 시 중복 결과가 없도록 했습니다. Airflow를 통해 이런 운영 상황을 빠르게 발견하고 대처할 수 있었고, 데이터 품질과 신뢰성을 높이는데 주의를 기울이게 되었습니다.
이러한 어려움을 겪고 해결하는 과정을 통해 Spark와 Airflow에 대한 실무 역량이 많이 향상되었습니다. 초기에는 새 기술 스택으로의 전환이라 시행착오가 있었지만, 결과적으로 문제 해결을 통해 얻은 지식들이 앞으로 유사한 데이터 파이프라인을 구축하거나 확장할 때 큰 자산이 될 것입니다.
마치며
이번 프로젝트를 통해 Python 기반의 단순 파이프라인을 Spark 기반의 분산 데이터 처리 파이프라인으로 성장시킬 수 있었습니다. 명함 OCR 데이터 파이프라인은 이제 하루 5만 건의 데이터를 안정적으로 처리하고 있으며, Airflow 도입으로 운영의 효율성과 가시성도 크게 향상되었습니다. Spark 덕분에 향후 데이터량 증가에도 무리 없이 대응할 수 있는 기반을 마련했고, Airflow를 통해 배치 작업의 자동화/스케줄링 및 모니터링 체계를 갖추게 되었습니다. 아직 EKS 상의 Spark Operator 도입과 같은 과제가 남아있지만, 현재까지의 마이그레이션 경험은 추후 더욱 큰 규모의 데이터나 복잡한 워크플로우를 다룰 때도 도움이 될 값진 교훈이 되리라 생각합니다.
데이터 엔지니어링 초급~중급 수준에서 Spark와 Airflow를 다루는 일은 도전적이지만, 한번 구축해 두니 확장성, 유연성, 안정성 측면에서 얻는 이득이 매우 컸습니다. 처음 이 둘을 함께 사용하는 분이라도 작은 데이터셋으로부터 시작해보며 점진적으로 적용해 보면 좋겠습니다. 제 포트폴리오 사례가 비슷한 상황에 계신 분들께 참고가 되었기를 바랍니다. 앞으로도 얻은 경험을 바탕으로 더욱 발전된 데이터 파이프라인을 구현해나갈 예정입니다. (Apache Airflow vs Spark: Which One Wins? - RisingWave: Open-Source Streaming Database) (데이터 엔지니어링 핵심 도구 ‘Apache Airflow’ 개념 정리 | 요즘IT)
