학습주제
시각화로 결과 요약하기
- seaborn/Wordcloud
학습내용
해시코드 질문 키워드의 빈도를 시각화 한다.
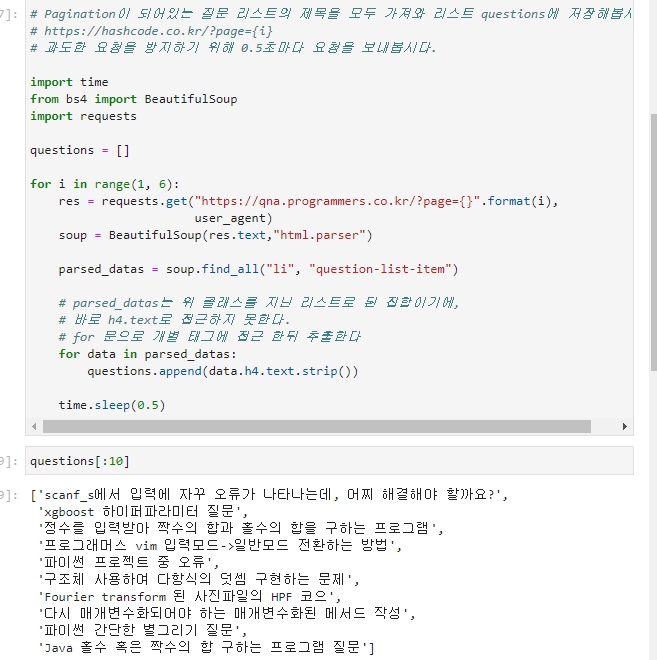
지난 수업 때의 코드를 재사용한다. 1페이지 ~ 5페이지까지 접근하여 텍스트를 얻는다.
-
이제 형태소 분석기에 넣어 명사를 뽑아내고,
-
그 뽑아낸 명사를 딕셔너리에 넣어 빈도를 저장한 뒤,
-
시각화 한다.
-
단계에서 지난번엔 문장 하나는 바로 형태소 분석기인
hananum.nouns("")넣어 그 결과가 바로 출력됐지만, 지금은 문자열을 원소로하는 리스트 집합형태이다. 반복문을 넣어 각기 집어넣는다.
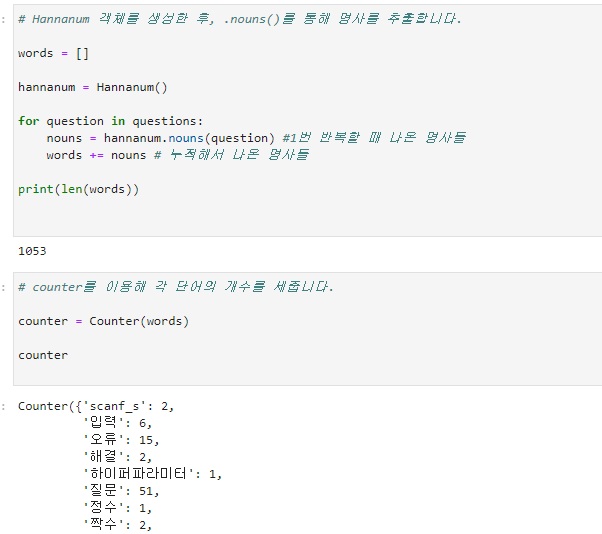
counter를 이용해서 단어, 빈도수를 짝으로 하는 딕셔너리를 얻었다.

앞의 코드를 조합해서 마찬가지로 출력해보았다.
시각적으로 얻은 데이터를 결과를 낼 수 있다는 점에서 상당히 재미있었던 경험이다.
연습
연습으로 다른 커뮤니티의 글 제목 중 명사를 파싱하여, 빈도 수를 시각화하였다.
다만 hashcode 처럼 태그.text가 정확한 제목을 나타냈던 것과 달리. 불필요한 단어가 반복적으로 섞여들어가 데이터에 정확성이 떨어지는 일이 발생했다. 이를 해결하기 위해 find_all() 대신
parsed_datas = soup.select("td.listsubject.sbj")을 사용하여. 좀 더 세부적으로 찾아가도록 했다. decompose()를 사용해보려고 했으나 잘 안되어 실패했다.

반갑습니다 햄스터 좋아합니다