학습 주제
시각화로 결과 요약하기
학습내용
질문 주제 빈도를 보여주는 시각화를 진행해본다.
스크래핑
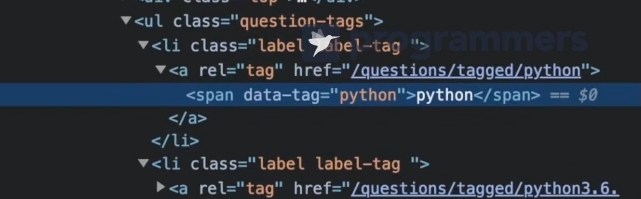
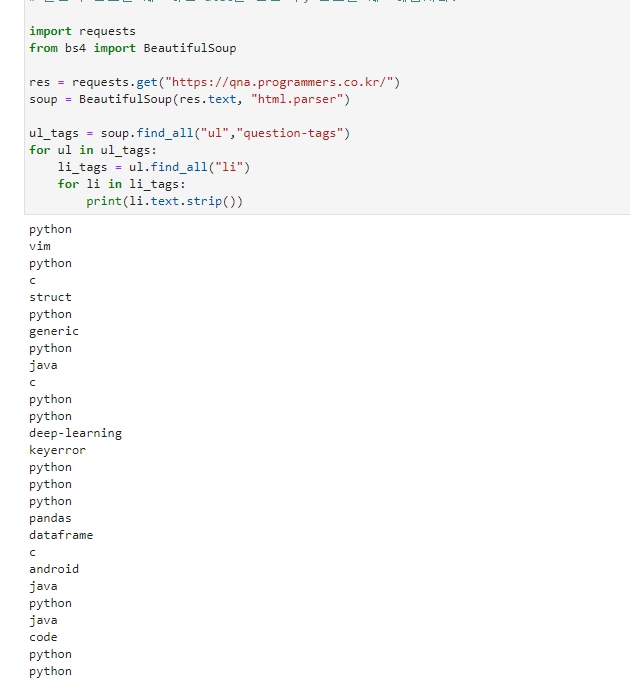
1. 먼저 ul 태크에 class="question-tags"를 갖고 모두 찾을 예정.
2. 1번 안에 있는 li 태그의 text를 추출
find() 대신 find_all()을 사용한 이유는. ul 안에 li가 없을 경우, (즉 태그를 달지 않았을 경우) 오류가 나기때문에 find_all()을 하여 비어있으면 넘어가는 식으로 진행한다.
빈칸을 제거하기 위해 .strip()을 적용
현재까지는 한 페이지에 대한 스크래핑이었다. 대부분의 웹사이트는 페이지네이션을 지원하고 있고, 페이지 주소 위에 숫자인 쿼리형식으로 주소를 알려주고 있기 때문에, 이를 이용한다.
그리고 횟수를 저장하는 변수 frequency를 dict형으로 생성해준다. 이전 알고리즘 수업때 배웠던 .get()을 이용한 초기화를 사용하거나, for문을 사용한다.
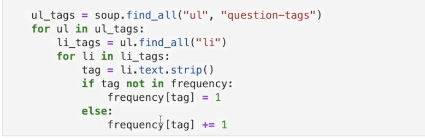
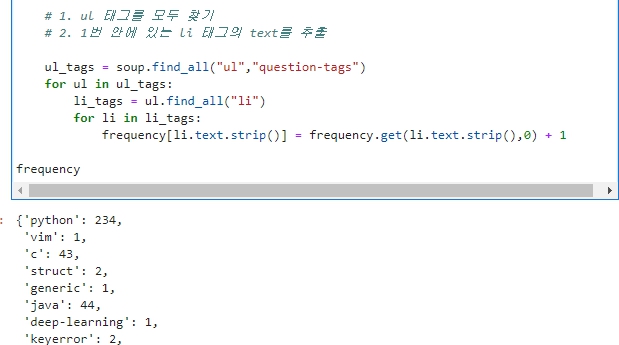
.get()의 두번째 인자는 만일 1번째 인자로 넣은 키값이 존재하지 않을 경우 0을 반환한다는 뜻이다. 있을 경우는 그 키값에 해당하는 값을 리턴한다.
페이지네이션을 통한 이동은 한순간에 이뤄지므로, 양이 많을 경우 서버에 부하가 걸린다. 따라서 인위적으로 time.sleep(0.5)를 걸어준다.
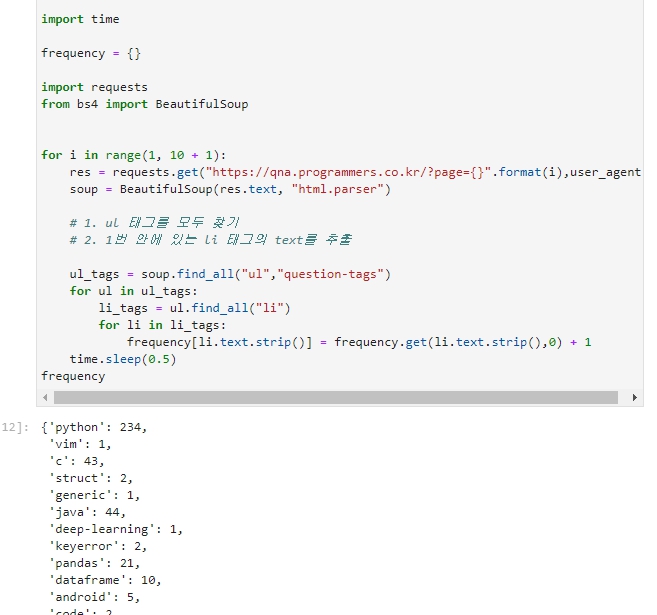
약간의 로딩 후 연속적으로 잘 뜨는 것을 볼 수 있다.
시각화
저장된 딕셔너리를 갖고 상위 10개만 추출한다.
이를 위해 기존 라이브러리 collection.Counter 객체를 이용한다.
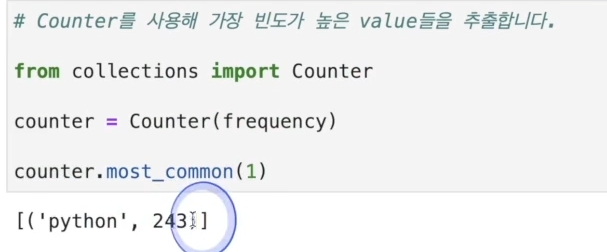
위와 같이 갯수를 이용한 처리가 간편하다.
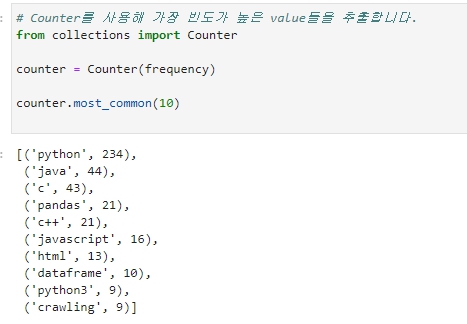
상위 10개의 키워드를 얻은 모습이다.

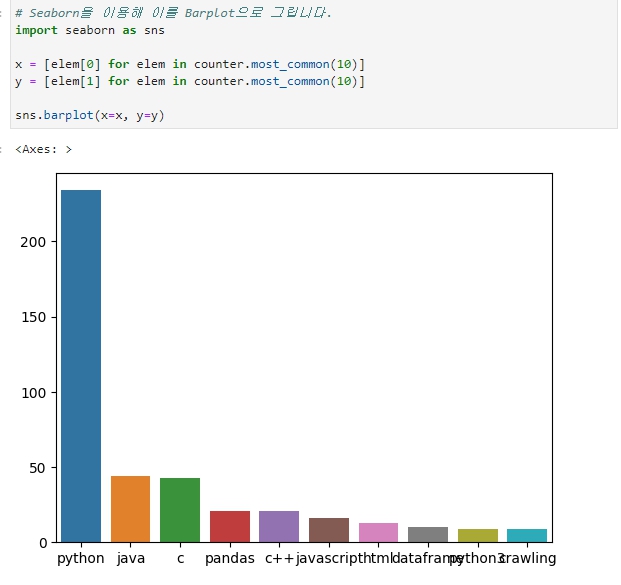
일다 출력이 되었으나, 가로의 넓이가 작아 글자가 겹치는 현상이 일어났다. 이를 해결하기 위해 figsize()를 이용한다.
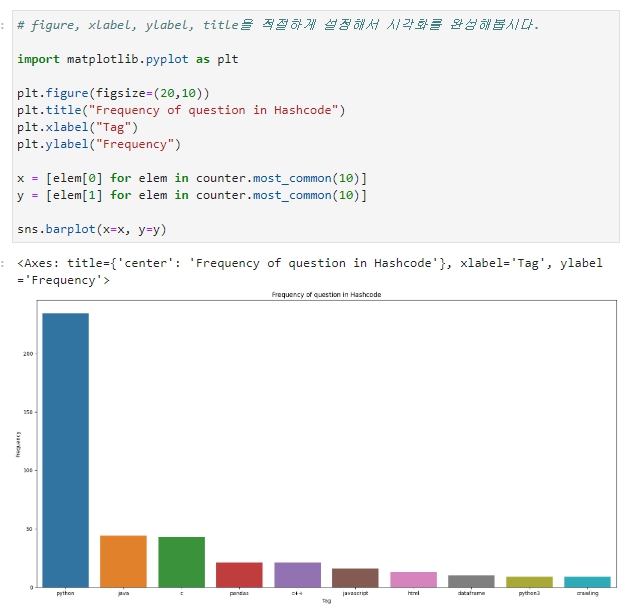
훨씬 깔끔하게 정리된 모습이다.
파이썬이 압도적으로 질문이 많은 것을 알 수 있다.
생각보다 유익한 결과를 낼 수 있어서 재미있었다.
- 부하를 너무 주지 않는다.
- 상업적 침해를 고려한다.
를 유의하며 다른 웹페이지 스크래핑 & 시각화를 시도해봐야겠다.
