학습주제
웹 브라우저 자동화
- Selenium -
학습내용
동적 웹페이지를 다루기 위해 웹 자동화 프레임워크 Selenium 사용
터미널에서 pip3 install selenium 하였음. 만일 셀레니움이 작동하지 않는다면 버전 업그레이드까지 마무리하기.

Web Driver 설치.
웹 브라우저와 직접적인 연결을 담당
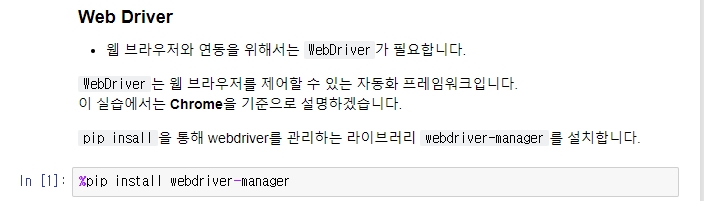
시작하기

Service 크롬 객체 만들 때 인자로 넣어줌.
CromeDriverManager 동일 버전 싱크를 위해 불러움.
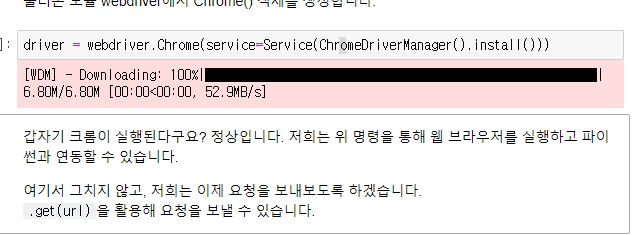
앞으로 이런 형태로 진행할 예정.
크롬 창 생성. 드라이버 객체 생성하고, 크롬 브라우저를 띄우라는 명령을 함.

마찬가지로 드라이버 메서드 get을 활용하여 우리는 웹사이트에 요청을 보낼 수 있다.
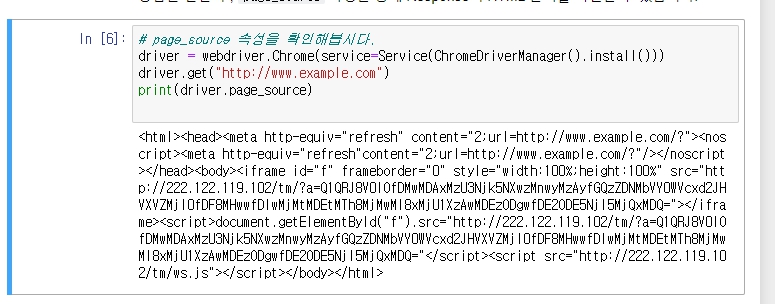
page_source속성에는 지난번 requests의 .text처럼 전체 html 코드가 저장되어 있다. 왜인지는 모르겠으나 코드가 깔끔하게 정리되어 있지 않고, 한줄로 연결되어 있다.
드라이버 객체를 만들게 되면, 이 객체가 소멸될 때까지 크롬 브라우저는 종료되지 않는다.
코드로도 종료할 수 있는데,
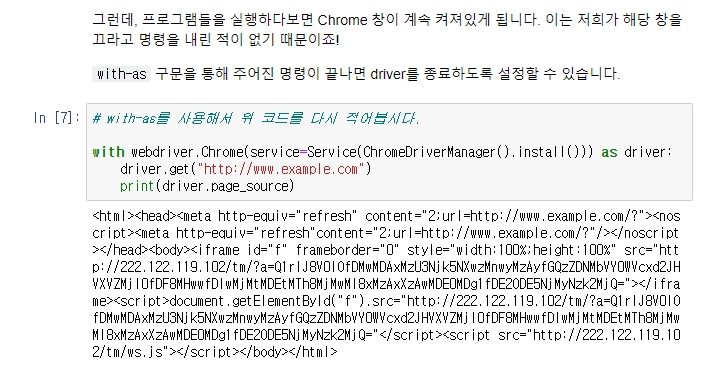
보면 급박하게 꺼지는데, 요청에 의한 렌더링을 하기도 전에 원하는 요소를 얻고 종료한 모습이다.

Selenium은 스크래핑도 지원한다.
- by?
- https://yeko90.tistory.com/entry/%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EA%B8%B0%EC%B4%88-NoSuchElementException-ElementNotVisibleException-%EC%97%90%EB%9F%AC-%ED%95%B4%EA%B2%B0-%EB%B0%A9%EB%B2%95
NoSuchElementException 오류가 발생했다. 코드를 그대로 쳤는데도 안됐는데, 이는 렌더링 되기도 전에 요소를 찾으려고 하면 자주 발생한다고 한다. 이에
driver.implicitly.wait(5)라는 암시적대기를 사용하였다. 암시적대기는 웹페이지 전체의 렌더링이 3초가 걸렸을 경우 남은 2초를 더 기다리지 않고, 바로 다음 요청을 수행한다. 그 외에 명시적대기(explicit wait)은 내가 정한 특정 요소가 준비되면 바로 동작한다.
이번 수업 진행을 위해 암시적 대기만 사용한다.

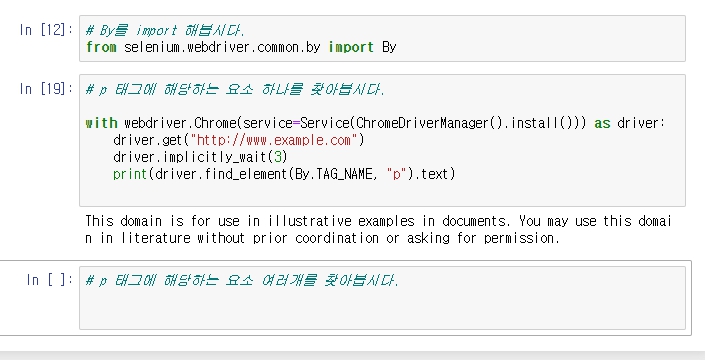
코드 간결화를 위해 selenium에서 원하는 모듈, 메서드만 추출하는 모습이다. 이번에는 By를 추출해서 사용한다.
그렇다면, p 태그를 갖는 여러 요소들을 동시에 찾으려면?
find_elements를 사용한다.
뒤에 s만 붙였더니
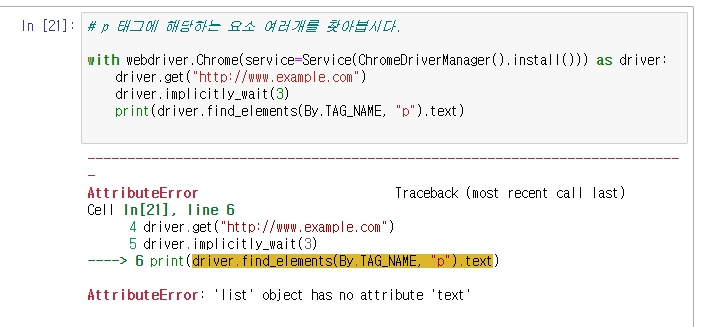
다음과 같은 오류가 뜬다. 이는 elements는 리스트 형식이기 때문에 .text에 바로 접근할 수가 없다.
따라서, for문으로 각 element에 접근한 후 .text를 사용해준다.

여기까진 BeautifulSoup과 큰 차이를 느낄 수 없다.
