
이번 모듈에서는 하나의 API 호출로 여러 아이템을 검색하는 방법에 대해서 알아보고, secondary index(보조 인덱스)를 활용하여 multiple data에 access하는 방법에 대해 알아볼 것이다.
Application use cases
지난 모듈에서는 GetItem API 호출을 이용하여 DynamoDB에서 데이터 하나를 검색하는 방법을 알아보았다.
이러한 접근 패턴은 매우 유용하지만, 우리의 application에서는 한번의 호출로 여러 개의 데이터를 가져오는 접근 패턴도 필요하다. 예를 들어, John Grisham 이 쓴 책을 모두 검색해서 얻은 결과를 유저에게 보여주는 등의 작업을 해야 할 때가 있기 때문이다.
이 모듈의 STEP 1 부분에서는 Query API를 이용하여 특정 작가가 쓴 모든 책을 검색해오는 실습을 할 것이다.
하나의 데이터를 가져오는 GetItem API와 여러개의 데이터를 가져오는 Query API 모두 검색할 테이블의 PK 정보를 필요로 한다.
그런데, PK를 통한 검색 말고도 PK가 아닌 attribute, 예를 들어 특정 Category 를 가진 책의 데이터들을 검색하고 싶을 수도 있다. Category 는 테이블의 PK가 아니긴 하지만, secondary index(보조 인덱스)를 생성하여 추가적인 데이터 접근 패턴을 만들 수 있다.
secondary index를 만드는 방법과 이를 통한 데이터의 query는 이 모듈의 STEP 2와 STEP 3에서 다룰 것이다.
STEP 1. Retrieve multiple items with a query
테이블이 복합 PK를 사용하는 경우, Query API를 이용하면 동일한 hash key를 가진 모든 아이템을 검색할 수 있다.
우리의 application을 예로 들어보면, hash key인 Author 가 동일한 모든 책들을 검색해 올 수 있다는 뜻이다.
이 예제는 query_items.py 스크립트를 이용한다.
query_items.py 뜯어보기
import boto3
from boto3.dynamodb.conditions import Key
# boto3 is the AWS SDK library for Python.
# The "resources" interface allows for a higher-level abstraction than the low-level client interface.
# For more details, go to http://boto3.readthedocs.io/en/latest/guide/resources.html
dynamodb = boto3.resource('dynamodb', region_name='ap-northeast-2')
table = dynamodb.Table('Books')
# When making a Query API call, we use the KeyConditionExpression parameter to specify the hash key on which we want to query.
# We're using the Key object from the Boto3 library to specify that we want the attribute name ("Author")
# to equal "John Grisham" by using the ".eq()" method.
resp = table.query(KeyConditionExpression=Key('Author').eq('John Grisham'))
print("The query returned the following items:")
for item in resp['Items']:
print(item)
스크립트를 살펴보면, boto3.resources().dynamodb.Table().query(KeyConditionExpression = ~~) 이라는 Query API를 이용한다.
Query API를 호출할 때는 KeyConditionExpression이라는 파라미터가 필요한데, 이것은 내가 query하고자 하는 키가 무엇인지를 지정하는 것이다.
우리는 Author 가 John Grisham인 모든 책을 필요로 하기 때문에, 사용하는 Key AttributeName은 Author 이므로 Key('Author), Author의 값이 John Grisham과 동일한 것을 가져올 것이므로 Key('Author).eq('John Grisham')을 파라미터로 넣는다.
query_items.py 실행하기
다음과 같이 스크립트를 실행하면 John Grisham의 모든 책이 검색됨을 알 수 있다.

STEP 2. Creating a secondary index
DynamoDB는 테이블에 대한 추가적인 데이터 검색 패턴을 할당하기 위한 secondary index들의 생성을 허용한다. secondary index는 DynamoDB 테이블에서의 유연한 query를 하게 해 주는 강력한 도구이다.
DynamoDB에는 global secondary indexes와 local secondary indexes 이렇게 두 가지 종류의 secondary index가 존재한다. 이번에 우리는 Category attribute에 global secondary index를 추가하여 특정 카테고리에 대한 모든 책 검색이 가능하도록 할 것이다.
해당 내용은 add_secondary_index.py 스크립트를 이용한다.
add_secondary_index.py 뜯어보기
Attribute Definitions
try:
resp = client.update_table(
TableName="Books",
# Any attributes used in our new global secondary index must be declared in AttributeDefinitions
AttributeDefinitions=[
{
"AttributeName": "Category",
"AttributeType": "S"
},
],update_table({})을 사용하여 global secondary index를 추가한다.
먼저, 어떠한 attribute를 secondary index로 사용하기 위해서는 해당 attribute가 정의되어 있어야 한다. Category attribute는 아직 정의한 적이 없기 때문에, AttributeDefinitions를 통해 string 타입의 Category attriute를 정의해 준다.
Global Secondary Index Updates
# This is where we add, update, or delete any global secondary indexes on our table.
GlobalSecondaryIndexUpdates=[
{
"Create": {
# You need to name your index and specifically refer to it when using it for queries.
"IndexName": "CategoryIndex",
# Like the table itself, you need to specify the key schema for an index.
# For a global secondary index, you can do a simple or composite key schema.
"KeySchema": [
{
"AttributeName": "Category",
"KeyType": "HASH"
}
],그 다음으로, GlobalSecondaryIndexUpdates를 이용하여 global secondary index를 add, update, delete 할 수 있다. 우리는 Create라는 속성을 통해 global secondary index를 테이블에 추가할 것이다.
Creat 내부의 첫 번째 속성은 IndexName 이다. 이는 앞으로 쿼리에서 사용햘 secondary index의 이름이 되겠다. 두 번째로 KeySchema는 테이블을 생성하며 PK를 정의할 때와 같이 현재 정의되어 있는 attribute들 중 어떤 attribute를 사용할 것이며, key type은 어떤 것으로 할 것인지를 정하고 있다.
ProjectionType
# You can choose to copy only specific attributes from the original item into the index.
# You might want to copy only a few attributes to save space.
"Projection": {
"ProjectionType": "ALL"
},
# Global secondary indexes have read and write capacity separate from the underlying table.
"ProvisionedThroughput": {
"ReadCapacityUnits": 1,
"WriteCapacityUnits": 1,
}
}
}
],
)다음은 Projection 부분에서 ProjectionType을 정하는데, 이는 테이블에서 index로 projection(복사) 되는 속성을 나타낸다.
지금처럼 Category attribute를 hash key로 한 CategoryIndex라는 이름의 secondary index를 생성하는 경우를 생각해 보자. 이 CategoryIndex는 Category 속성을 이용하여 쿼리하는 것이고, 기본 테이블의 기본 키 속성은 언제나 index로 프로젝션 되기 때문에 일단 CategoryIndex는 다음과 같이 구성될 것이다.
| Category | Author | Title |
|---|
이제 여기서 ProjectionType에 의해 CategoryIndex의 구성이 달라지게 될 것인데, ProjectionType은 다음과 같이 세 가지 종류가 있다.
-
KEYS_ONLY
인덱스와 기본 키만 인덱스로 프로젝션됨Category Author Title -
INCLUDE
지정된 테이블 속성만 인덱스로 프로젝션됨. 프로젝션된 속성 목록은 NonKeyAttributes에 있다.만약
Price라는 속성이 현재 테이블에 존재한다고 했을 때, 이 속성을INCLUDE하게 되면 다음과 같은CategoryIndex가 구성된다.Category Author Title Price -
ALL
모든 테이블 속성이 인덱스로 프로젝션된다.Category Author Title Format
우리는 이번 예제에서 ProjectionType : ALL을 선택했으므로 테이블에 있는 모든 속성들이 인덱스로 프로젝션될 것이다. 따라서, CategoryIndex secondary index로 쿼리를 진행해도 테이블의 모든 속성이 나올 것이다.
Provisioned Throughput
기본 테이블에도 ReadCapacityUnits와 WriteCapacityUnits가 정해져 있듯이, secondary index에도 w/r throughput이 정해져 있다. 하지만, secondary index의 throughput은 기본 테이블의 throughput과 별개로 동작한다.
add_secondary_index.py 실행하기
다음과 같이 스크립트가 문제 없이 실행되면 인덱스가 추가되었다는 로그가 뜬다.

해당 인덱스는 aws console에서도 확인할 수 있다.

STEP 3. Querying a secondary index
이제 CategoryIndex 를 생성했으니, 특정 카테고리의 모든 책을 검색할 수 있게 되었다. secondary index를 이용하여 쿼리를 진행하는 방법은 Query API를 이용하는 방법과 비슷하다. 이전에 하던 것과 같이 Query API를 호출하되, 인덱스 이름을 추가하면 된다.
존재하는 테이블에 global secondary index를 추가하게 되면, DynamoDB는 비동기적으로 테이블에 현존하는 아이템들을 index에 추가하게 된다(backfill). 생성된 index는 이미 존재하던 모든 아이템들이 채워지고 난 뒤에 이용이 가능하다. 테이블에 존재해 있던 과거 데이터들을 채워넣는데 걸리는 시간은 기본 테이블의 크기에 따라 달라진다.
이번 단계에서는 query_with_index.py 스크립트를 이용할 것이다.
query_with_index.py 뜯어보기
global secondary index 상태 확인하기
# When adding a global secondary index to an existing table, you cannot query the index until it has been backfilled.
# This portion of the script waits until the index is in the “ACTIVE” status, indicating it is ready to be queried.
while True:
if not table.global_secondary_indexes or table.global_secondary_indexes[0]['IndexStatus'] != 'ACTIVE':
print('Waiting for index to backfill...')
time.sleep(5)
table.reload()
else:
break위에서 secondary index는 backfill 과정이 존재하기 때문에 backfill 과정이 모두 끝난 후에야 secondary index를 사용할 수 있다고 했다. 이 과정 때문에 STEP 2의 aws console에서의 결과 사진에서 상태가 생성중임을 확인할 수 있다.
secondary index의 status가 ACTIVE가 아니면 아직 index를 생성중이기 때문에 사용이 불가능하다. 따라서, 위와 같은 로직을 통해 secondary index의 상태가 ACTIVE가 될 때까지 기다렸다가 이를 확인하고 다음 로직으로 넘어가도록 한다.
query 요청하기
# When making a Query call, we use the KeyConditionExpression parameter to specify the hash key on which we want to query.
# If we want to use a specific index, we also need to pass the IndexName in our API call.
resp = table.query(
# Add the name of the index you want to use in your query.
IndexName="CategoryIndex",
KeyConditionExpression=Key('Category').eq('Suspense'),
)아까 Query API를 이용하여 특정 작가의 책을 불러오는 것과 비슷하지만, IndexName 속성이 추가되었다. 이 IndexName에 secondary index name을 주면 되고, KeyConditionExpression의 Key에는 secondary index의 key를, .eq를 통해 찾고자 하는 Category 이름을 넣으면 된다.
query_with_index.py 실행하기
스크립트를 실행하면 다음과 같은 결과를 뱉어낸다.
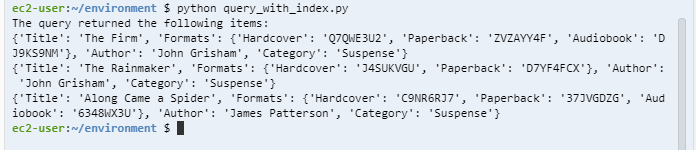
ProjectionType에서 ALL을 선택했기 때문에 기존 테이블에 있던 모든 속성들이 함께 나옴을 알 수 있다. 카테고리가 Suspense 인 여러 작가들의 책이 검색됨을 알 수 있다.
다음 모듈에서는 UpdateItem API를 이용하여 테이블에 존재하는 아이템의 attribute들을 update하는 방법을 알아볼 것이다.
