잇토리는 실시간 릴레이 형식으로 그림 편지를 작성하는 서비스입니다!
사건의 발단
- 어느 날 디스코드에서 기획자분께서 반복 횟수 설정 시 다음 단계로 넘어가지 않는 현상이 발생한다고 제보하셨다.
- 대부분은 정상적으로 작동하지만, 간혹 한 번씩 이러한 문제가 발생한다고 말씀하셨다.
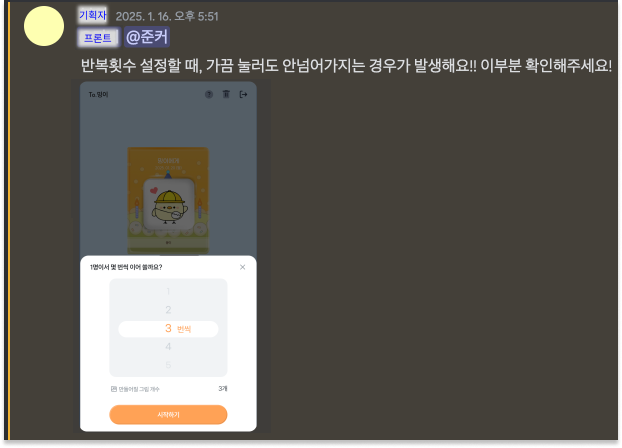
이 이야기를 듣고 DB의 편지 테이블을 확인하던 중, 다음과 같은 특징을 발견했다.
 -> 단 몇 분 차이로 동일한 내용의 받는 사람 이름과 편지 제목을 가진 편지들이 생성된 흔적이 몇몇 있었다.
-> 단 몇 분 차이로 동일한 내용의 받는 사람 이름과 편지 제목을 가진 편지들이 생성된 흔적이 몇몇 있었다.
문제 탐색 및 정의
0. 문제 분석
해당 부분과 관련된, 편지 작성 직전까지의 플로우는 다음과 같았다.
편지 정보 입력 -> 편지 꾸미기 -> 작성자 초대 -> 반복 횟수 설정 -> 작성 시작
여기서 작성 반복 횟수를 설정하는 단계에서, 편지를 구성하는 요소들이 DB에 생성된다.
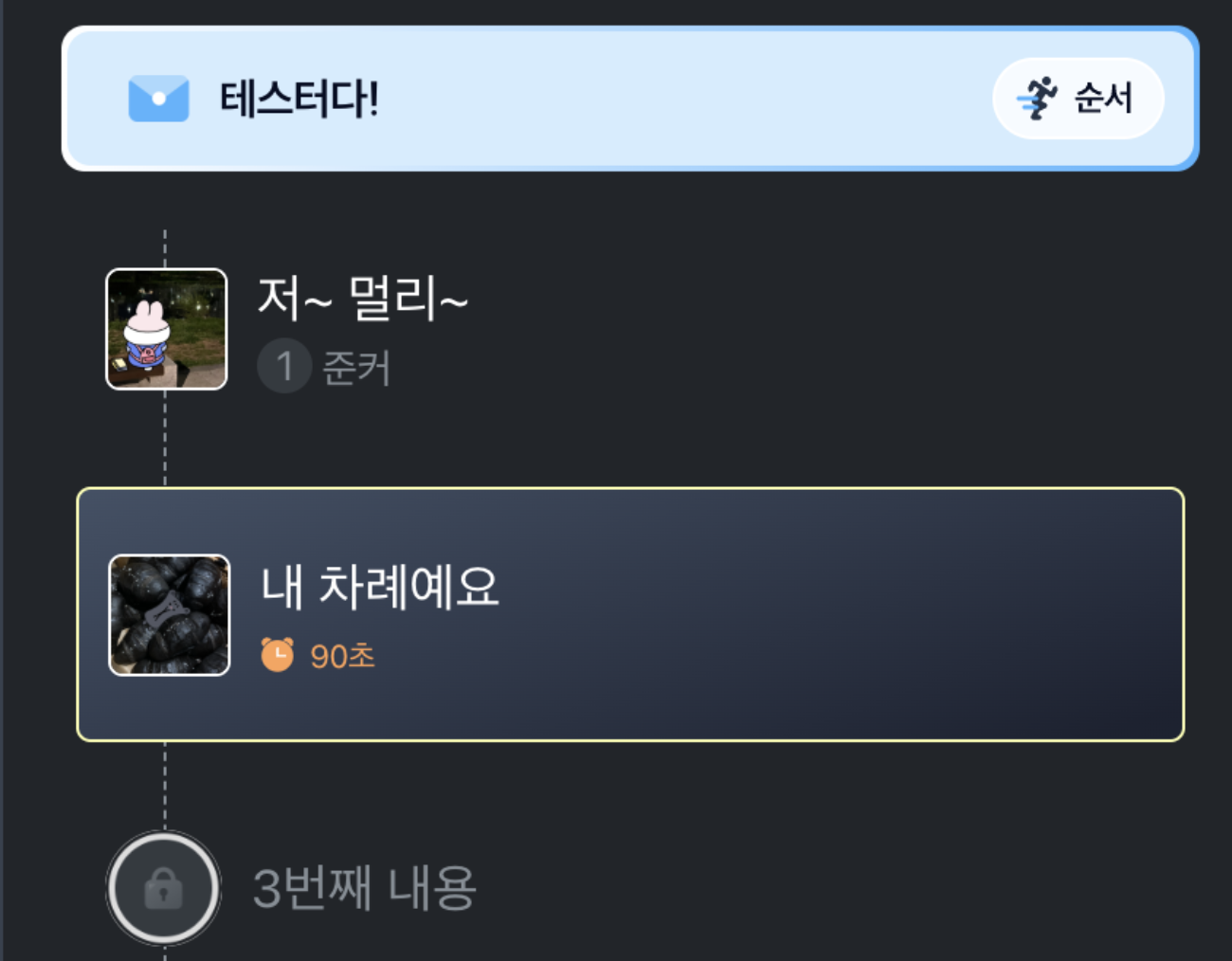
나는 편지의 요소가 생성되는 과정에서 문제가 있다고 판단했고, 그 부분을 중점으로 알아보기로 결정했다.
1. 서버 로그 확인
가장 먼저 한 행동은 서버 로그를 확인하는 것이었다. 편지의 요소가 추가되는 과정에서 에러가 발생한 것은 아닐까?
-> 그러나 서버에는 에러 로그가 기록되어 있지 않았다.
2. DB 편지요소 테이블 확인
에러 로그에 문제가 있는 것은 아닐까 싶어 편지 요소 테이블을 확인했다.
만약 DB에 요소가 생성되지 않았다면 로그 오류일 가능성이 있지만, 그렇지 않다면 다른 원인을 찾아야 한다.
결과적으로, 편지 요소 테이블에는 데이터가 정상적으로 생성되어 있었다.
3. 쿼리 로그 찍어보기
마지막으로, 로컬 환경에서 해당 API를 단독으로 호출하여 테스트해보았다.
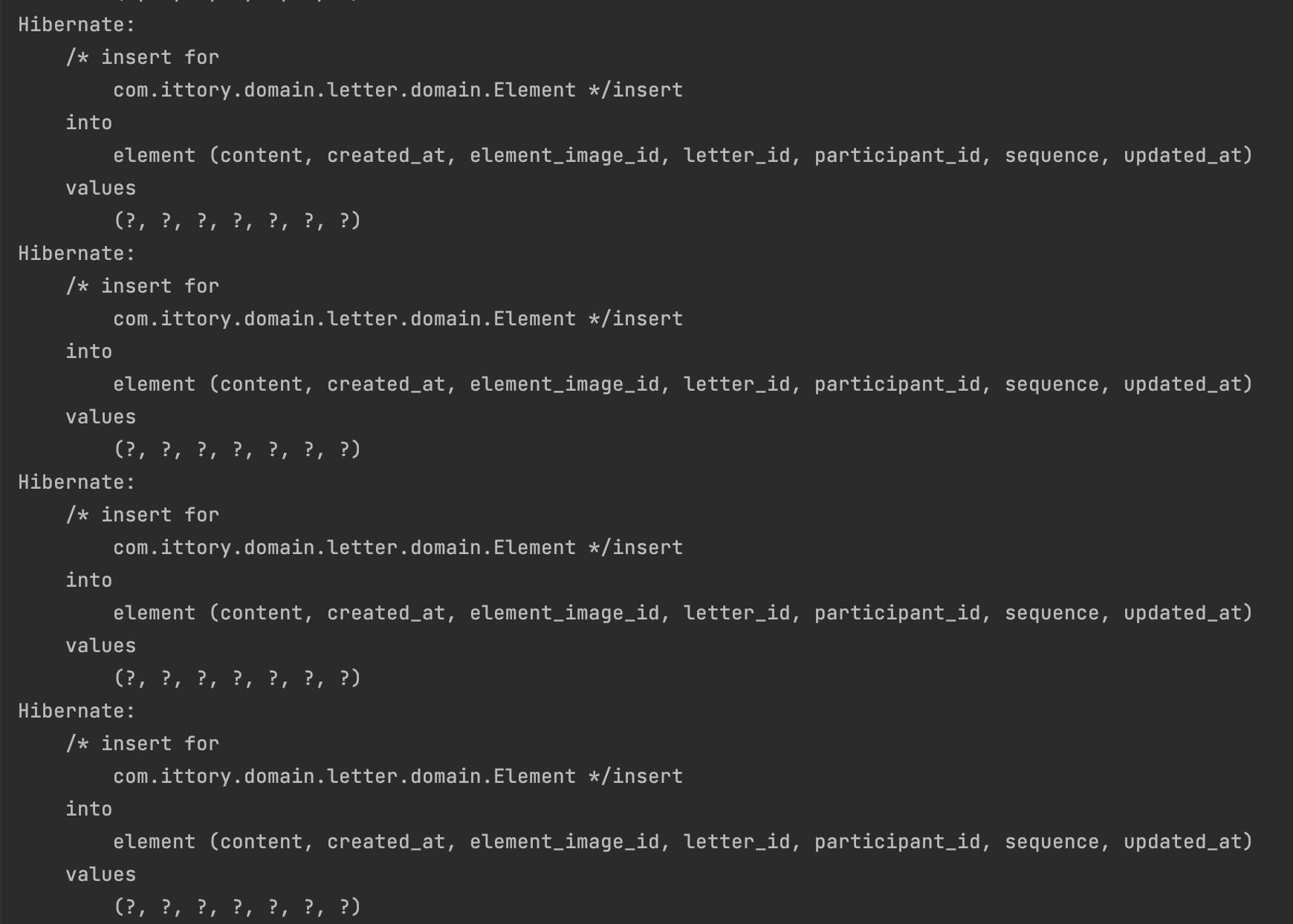
이런이런... 생성되어야 할 편지 요소의 개수만큼 INSERT 쿼리가 발생하는 것을 확인했다.
이로 인해, 편지 1개가 생성될 때마다 편지 요소와 관련된 INSERT 쿼리가 최대 50개까지 발생할 수 있었다. 동시에 여러 편지가 생성되는 상황에서는 성능 저하가 발생하여, 반복 횟수 설정 후 다음 화면으로 넘어가지 않는 문제가 나타났다. (정확히는, 모든 INSERT 쿼리가 완료되기 전까지 화면 전환이 이루어지지 않았다.)
추후 서비스가 확장되면서 편지당 최대 요소의 수가 증가하면, 그에 따라 INSERT 쿼리의 발생 빈도도 크게 늘어날 것이다. 이로 인해 성능 문제가 더욱 심각해질 가능성이 있어, 반드시 해결해야 할 문제로 판단했다.
개선 전 성능 체크
응답시간 계측
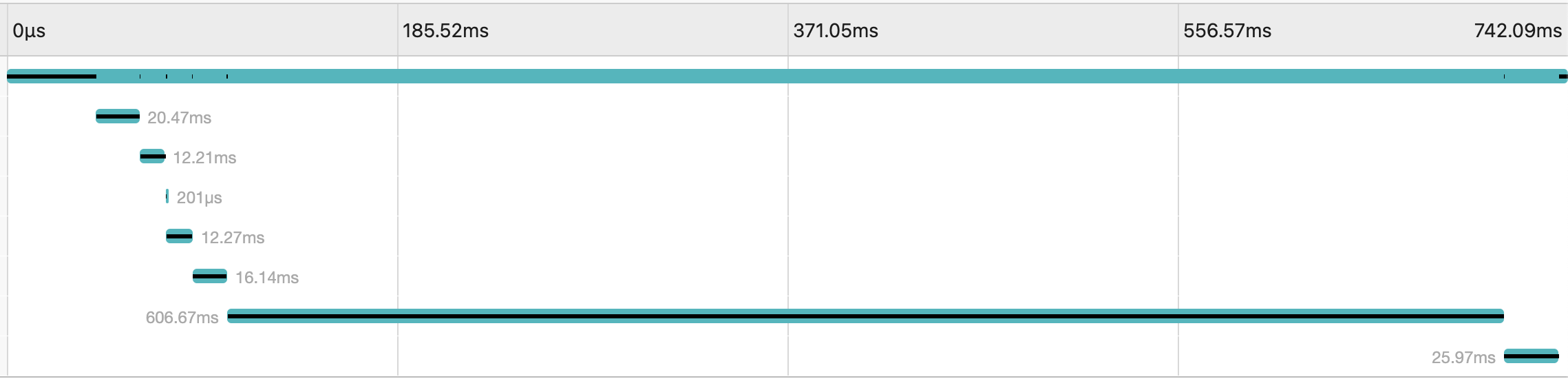
JAEGER UI를 통해서 해당 API의 응답시간을 계측해보았다.
예상대로 편지 요소를 생성하는 기능이 전체 API 응답 시간(742.09ms) 중 606.67ms로, 전체의 81.8%를 차지하고 있었다.

부하 테스트
부하 조건을 1, 10, 50, 100으로 나누어 총 4가지 시나리오로 진행했다.
(현재 MAU 기준으로 동시에 100개의 요청이 발생할 가능성은 낮아, 100을 최대 값으로 설정하였다.)
테스트 도구로는 기존에 사용 경험이 있는 Apache JMeter를 활용하였고, 서버는 로컬인 내 맥북 M2 Pro에 켜뒀다.
(실제 배포서버는 내 맥북보다 성능이 좋지 않으므로 더 낮게 나올 것이라 생각된다)
1명

10명

50명

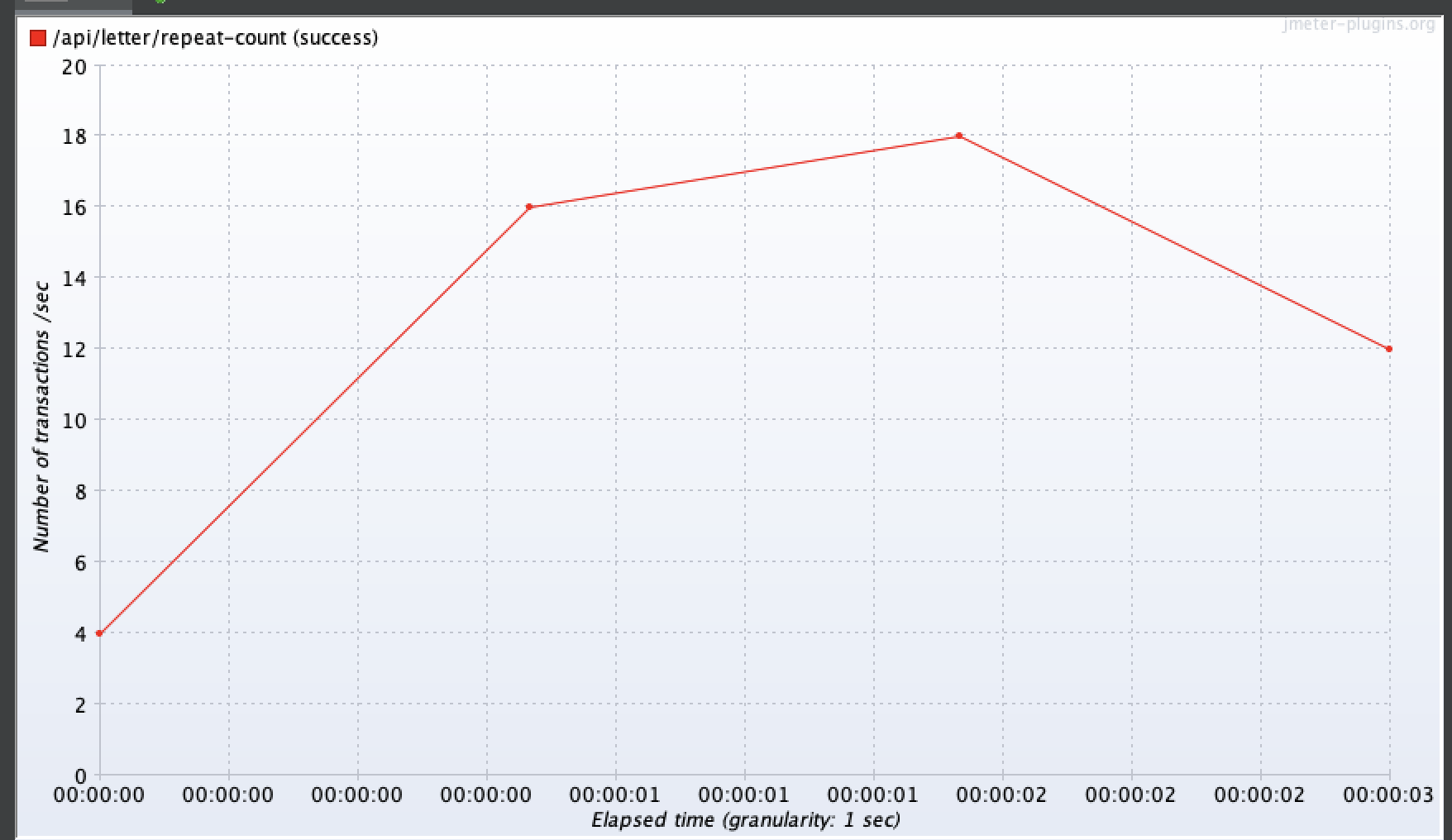
100명

100명 기준으로 평균 3.25초, 최대 약 5.8초가 걸렸다.
TPS는 최대 20까지 나타냈다.
개선
개선 방법 선정
개선 방법은 크게 세 가지로 나누어 고민했다.
- JPA 배치 INSERT: 다수의 데이터를 한 번에 처리하여 쿼리 호출 횟수를 줄이는 방식.
- JDBC Bulk 연산: JDBC의 대량 처리 기능을 활용하여 효율적으로 데이터를 삽입하는 방법.
- 편지 요소의 DB 타입을 JSON 형태로 변경: 편지 요소 데이터를 JSON 형태로 저장하여, 한 번의 쿼리로 전체 데이터를 삽입하도록 변경.
현재 문제의 핵심은 편지 요소 1개당 1개의 INSERT 쿼리가 발생하는 점이므로, 편지 요소의 개수와 상관없이 편지 요소를 생성하는 쿼리를 단 1개로 줄이는 것이 목표였다.
1. JPA 배치 insert
가장 먼저 떠올린 방법은 JPA에서 배치 INSERT를 사용하는 것이었다. 잇토리는 기본적으로 Spring Data JPA + QueryDSL을 사용하고 있었고, 테스트 코드를 작성할 때마다 deleteAllInBatch()를 사용해 DB를 비워주는 작업을 했었기 때문에, 자연스럽게 saveAllInBatch() 같은 기능도 존재할 것이라 생각했다.
그러나, 그런 기능은 존재하지 않았다.
이후 자료를 찾아보니, batchSize를 조정하면 JPA에서 배치 INSERT를 사용할 수 있다는 것을 알게 되었다. 하지만, JPA Batch INSERT는 쓰기 지연을 이용해 동작하기 때문에, ID 생성 전략으로 IDENTITY 전략을 사용할 수 없다는 제약이 있었다.
결국, IDENTITY 전략을 포기하고 JPA 배치 INSERT를 사용할 것인지, 아니면 다른 방법을 모색할 것인지에 대한 고민이 필요했다.
2. JDBC Bulk 연산
그다음으로 고려한 방법은 JDBC의 Bulk 연산을 통한 INSERT 쿼리였다.
하지만 이미 DB와 관련하여 Spring Data JPA와 QueryDSL을 사용 중이었기 때문에, 새로운 기술을 도입하면 복잡성이 증가하고 혼란스러워질 우려가 있었다.
또한, 이 방법을 적용하기 위해서는 추가적인 학습이 필요했다.
3. 편지 요소의 DB 타입을 json 형태로 변경
다음으로 고려한 방법은, 편지 요소 1개당 DB 테이블의 1개의 row로 저장하는 대신, JSON 형식으로 저장하여 한 번에 조회하는 방식이었다.
이 방식은 쿼리 호출 횟수를 크게 줄일 수 있다는 장점이 있었지만, 기존 DB 구조와 서버 코드를 대대적으로 변경해야 한다는 단점이 있었다.
최종 선택
최종적으로 2번 방식인 JDBC Bulk 연산을 통해 개선하기로 결정했다. 그 이유는 다음과 같다.
-
JPA Batch Insert의 제약
1번 방식은 ID 생성 전략을 IDENTITY에서 다른 방식으로 변경해야 한다는 점이 가장 큰 걸림돌이었다.
이로 인해 DB 구조의 수정이 필요했으며, 이러한 변경은 엄청난 오버헤드를 유발할 것으로 예상되어 선택하지 않았다. -
JSON 형태 저장의 단점
3번 방식은 편지 요소를 JSON 형태로 저장하는 과정에서, 특정 요소만 조회해야 하는 경우에도 해당 편지의 모든 요소가 함께 조회된다는 문제가 있었다.
이는 불필요한 데이터 전송과 처리로 이어질 가능성이 높아 비효율적이라고 판단했다.
특히, 잇토리에서는 요소를 작성할 때 해당 요소의 정보를 개별적으로 조회하는 작업이 빈번했기 때문에, JSON 형태 저장 방식은 적합하지 않았다.
이러한 이유들로 기술이 하나 추가되고, 추가적인 학습이 필요하더라도 2번 방식인 JDBC Bulk 연산을 선택했다.
(사실 JSON 형식으로 저장하는 방식도 별도의 학습이 필요했기 때문에, 학습량 면에서는 큰 차이가 없었다.ㅎㅎ)
개선 과정
JDBC Bulk 연산을 통한 INSER를 사용해보지 않았기 때문에 공부가 필요했다.
구글에 많은 레퍼런스들이 있었고, 방법 또한 간단했다.
나는 QueryDSL을 사용할 때와 마찬가지로, RepositoryCustom과 RepositoryImpl을 생성한 뒤, RepositoryImpl 클래스에서 JdbcTemplate을 활용해 Bulk Insert를 구현하였다.
개선 코드
/* LetterService.class */
@Service
@RequiredArgsConstructor
public class LetterDomainService {
private final LetterElementRepository letterElementRepository;
@Transactional
public void createLetterElements(Letter letter, int repeatCount) {
/* 관련 로직 */
//letterElementRepository.saveAll(elements); // 기존 코드
letterElementRepository.saveAllInBatch(elements);
}
}/* LetterElementRepositoryImpl.class */
@RequiredArgsConstructor
public class LetterElementRepositoryImpl implements LetterElementRepositoryCustom {
private final JdbcTemplate jdbcTemplate;
@Override
public void saveAllInBatch(List<Element> elements) {
String sqlQuery = "INSERT INTO element (letter_id, element_image_id, sequence, created_at, updated_at)" +
" VALUES (?, ?, ?, NOW(), NOW())";
jdbcTemplate.batchUpdate(sqlQuery, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Element element = elements.get(i);
ps.setLong(1, element.getLetter().getId());
ps.setLong(2, element.getElementImage().getId());
ps.setInt(3, element.getSequence());
}
@Override
public int getBatchSize() {
return elements.size();
}
});
}
}개선 후 성능 체크
응답시간 계측


부하 테스트
1명

10명

50명

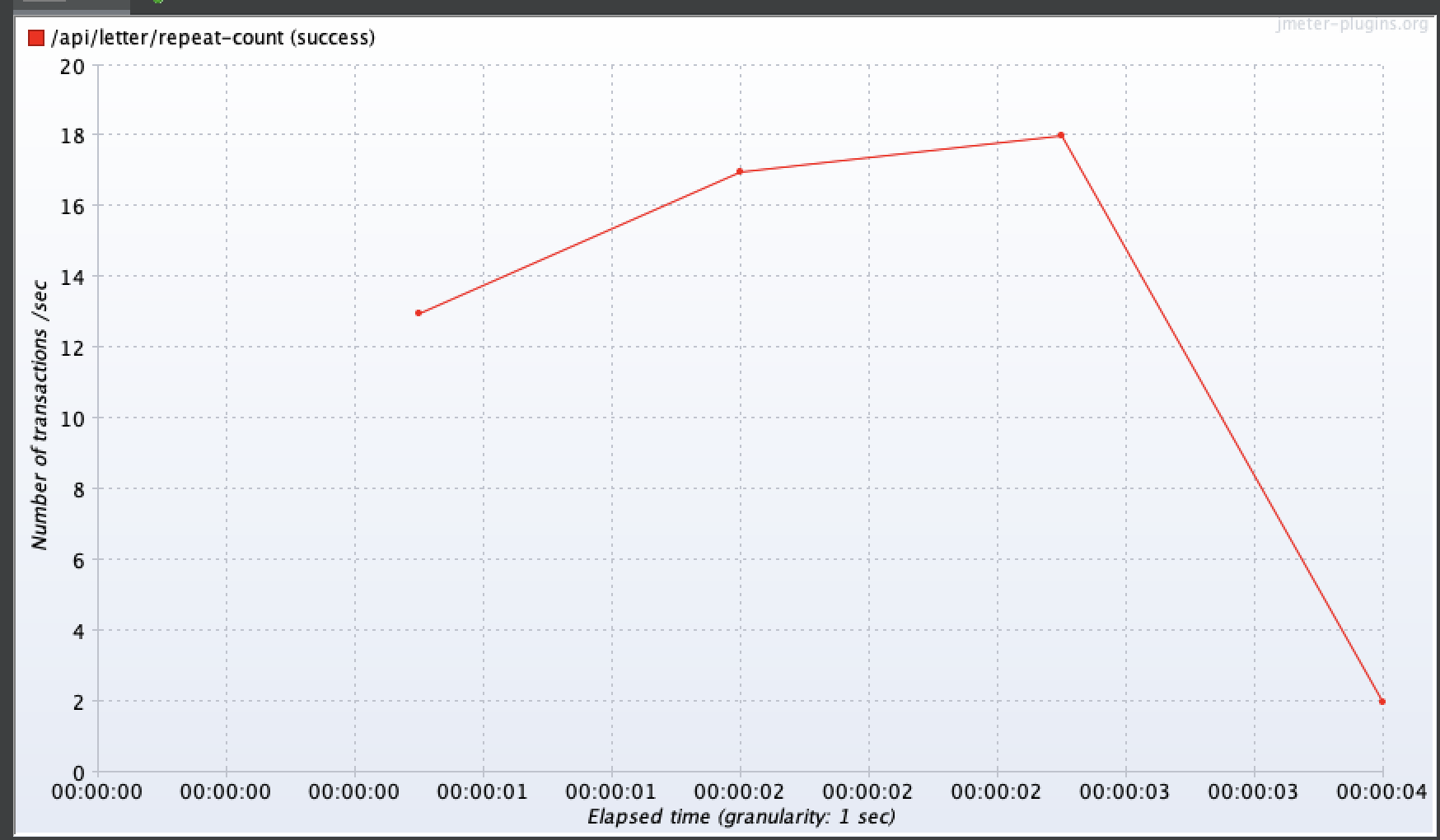
100명

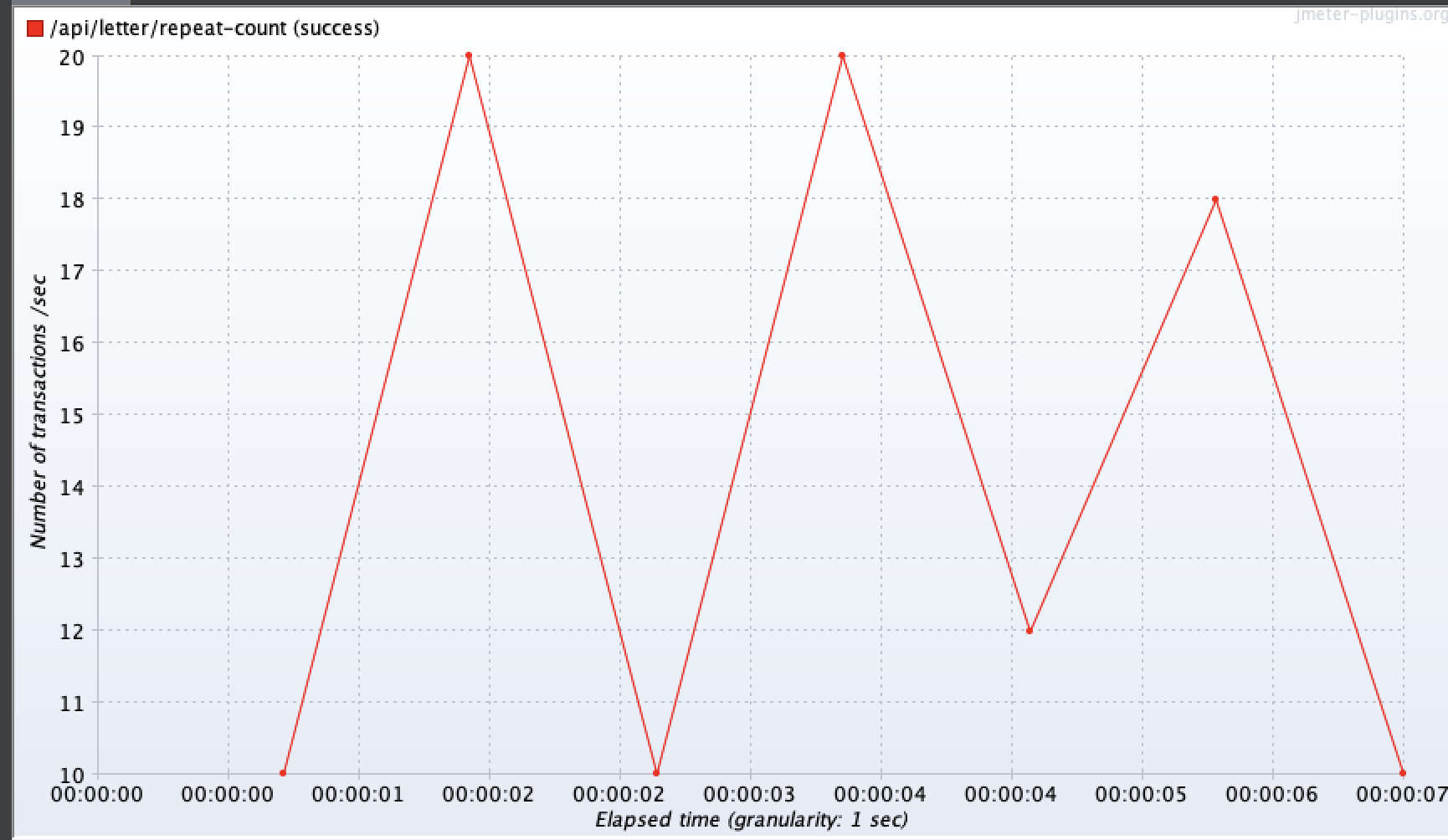
오잉..?!
개선 후 성능을 확인한 결과, 1명, 10명, 50명, 100명일 때 모두 크게 달라지지 않았거나, 오히려 느려지는 현상이 발생했다... 계측 그래프를 보면 편지 요소 생성시간도 그대로인 걸 확인할 수 있었다.
원인이 뭐지...?
다른 사람들이 JDBC Bulk INSERT를 어떻게 사용하는지 찾아본 결과, 설정파일에 JDBC DataSource를 지정하고, rewriteBatchedStatements=true 옵션을 추가해야 성능 개선 효과를 제대로 볼 수 있다는 점을 발견했다.
따라서 다음과 같이 옵션을 추가했다.
/* application.yml */
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
# rewriteBatchedStatements=true 추가
url: jdbc:mysql://${DB_ADDRESS}:${DB_PORT}/${DB_SCHEMA}?rewriteBatchedStatements=true
username: ${DB_USERNAME}
password: ${DB_PASSWORD}다시 성능 체크!
응답 시간 계측
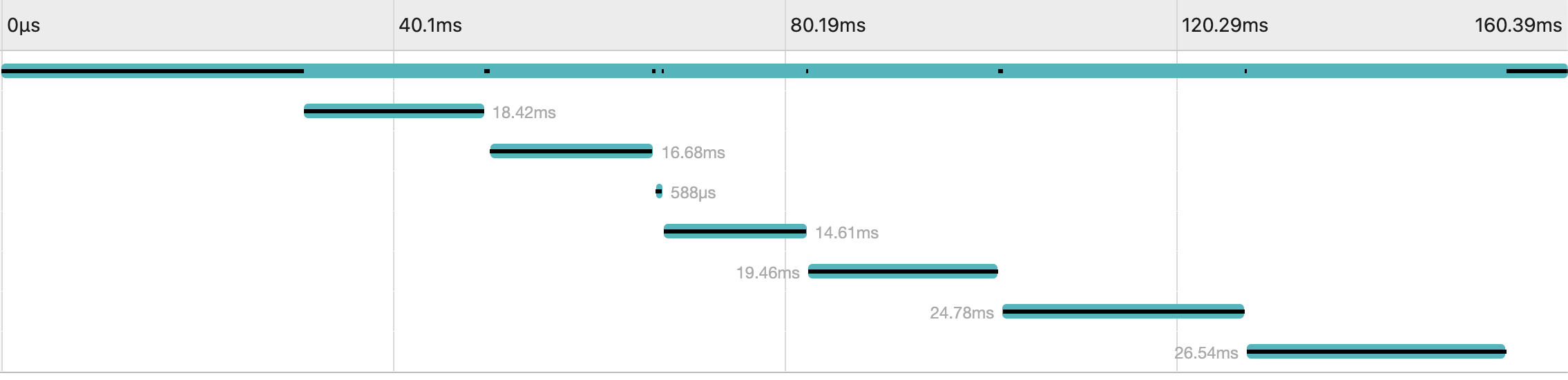

부하 테스트
1명

10명

50명

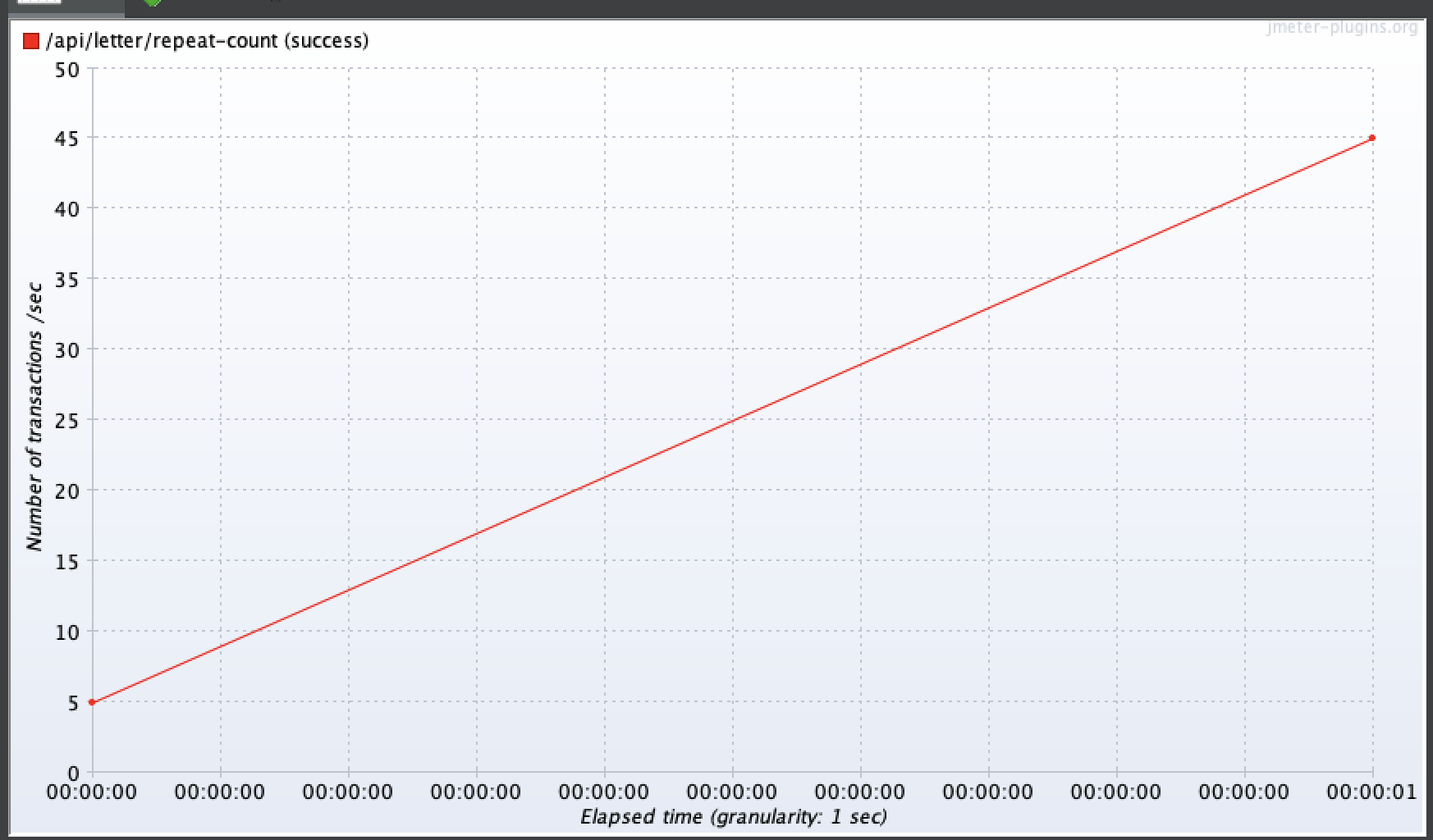
100명

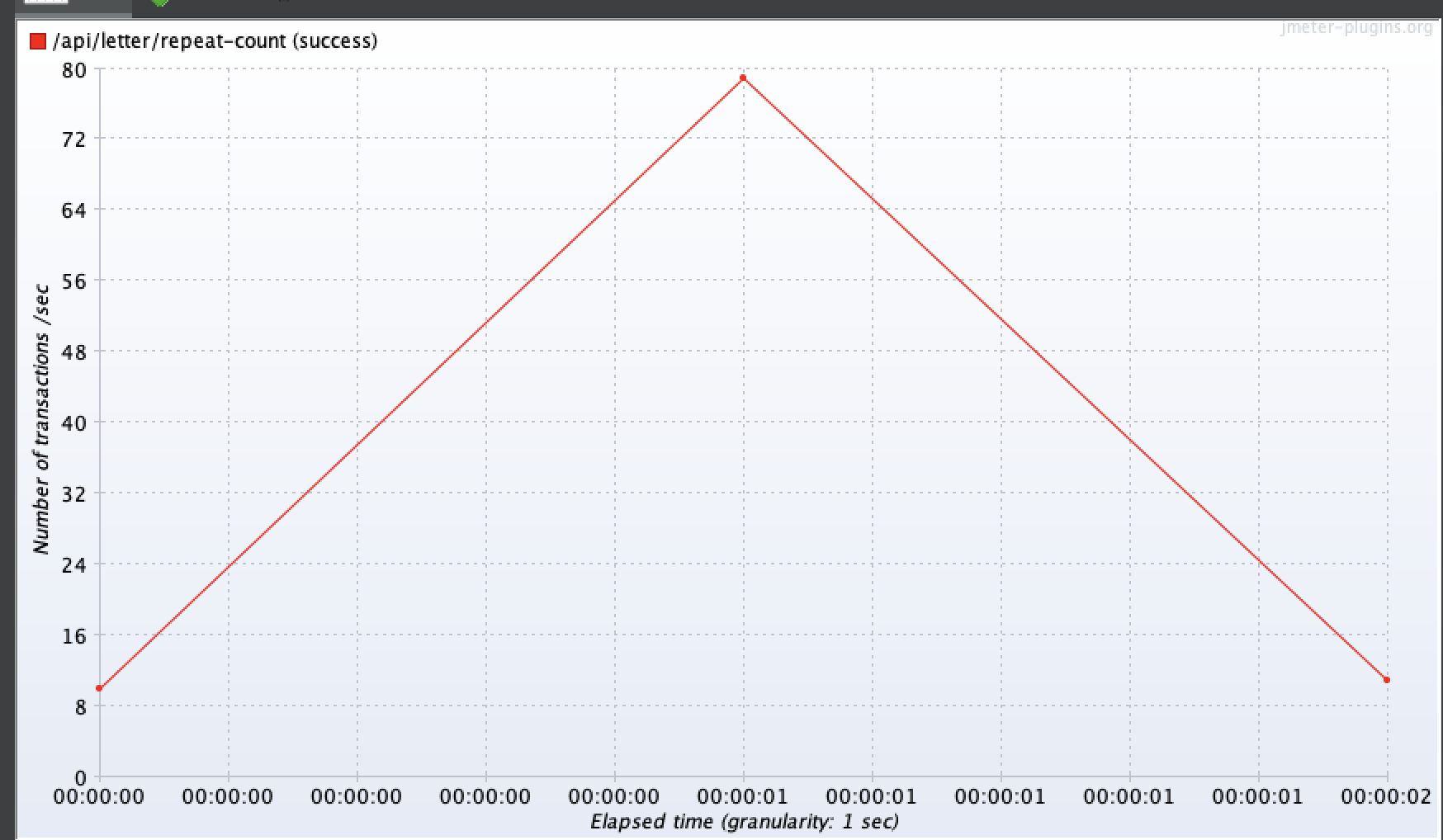
개선 결과, 1명, 10명, 50명, 100명에서 모두 성능 차이가 크게 나타났다.
계측 결과 총 응답시간(160.39ms) 중 24.78ms로, 전체의 15.4%를 차지하는 것을 확인할 수 있었다.
100명 기준 평균 응답시간 0.24초 최대 응답시간 0.34초로 개선되었고, TPS는 최대 80으로 개선된 것을 확인할 수 있었다.
정리
| 기준 | as-is | to-be | 향상치 |
|---|---|---|---|
| 편지요소 생성시간 | 606.67ms | 24.78ms | 24.5배(2350%) |
| 편지요소 생성 시간이 전체 중 차지하는 비중 | 81.8% | 15.4% | 5.3배(430%) |
| 평균 응답시간 (100명 기준) | 3.25초 | 0.24초 | 13.5배(1250%) |
| 최대 응답시간 (100명 기준) | 5.80초 | 0.34초 | 17.1배(1601%) |
| TPS (100명 기준) | 20 | 80 | 4배(300%) |
추가학습
rewriteBatchedStatements=true는 무슨 역할을 할까?
스택 오버플로우를 참조해서 자세히 알 수 있었다.
https://stackoverflow.com/questions/26307760/mysql-and-jdbc-with-rewritebatchedstatements-true
간단히 말하면, rewriteBatchedStatements=true 옵션은 여러 개의 쿼리를 하나로 압축해주는 역할을 한다고 한다.
이 옵션이 없을 경우, 여전히 각 쿼리가 개별적으로 전송되므로, 대량 데이터를 처리할 때 여전히 성능 저하가 발생할 수 있다.
참고 문헌
https://hyos-dev-log.tistory.com/1
https://velog.io/@dongvelop/Spring-Data-JPA-Batch-Insert로-한번에-데이터-삽입하기
https://stackoverflow.com/questions/26307760/mysql-and-jdbc-with-rewritebatchedstatements-true
