1. CPU 심화
1-1. 스케쥴링 소개
- CPU는 한정된 자원 -> 최대한 성능 이끌어내기 위해 적절하고 효율적으로 사용해야 함.
- 공통 배정 조건 : 오버헤드 ↓ / 사용률 ↑ / 기아 현상 ↓
- 오버헤드 : 프로세스가 필요한 자원보다 더 많이 사용하지 않도록- 사용률 : 프로세스가 최대한 자원을 많이 받고 빨리 처리하도록
- 기아 현상 : 프로세스가 자원 할당을 못 받은 상태로 대기하지 않도록
- 목표에 따란 배정조건
- 배치 시스템 : 가능하면 많은 일을 수행. 시간보다 처리량이 중요.- 대화형 시스템 : 빠른 응답 시간.
- 실시간 시스템 : 최소 응답 시간.
스케쥴링 단위
- 프로세스 실행 : CPU 실행, 입/출력 대기의 반복
- CPU Burst : 실제 CPU를 사용하는 스케쥴링 단위.
- I/O Burst : 프로세스 실행 중 I/O 작업이 끝날 때까지 Block되는 구간.
1-2. 스케쥴링 종류
선점 스케쥴링
1) 우선 순위 스케쥴링
- 정적/동적으로 우선 순위를 부여하여 우선 순위가 높은 순서대로 처리.
- 우선 순위가 낮은 프로세스가 무한정 기다리는 기아 현상 발생 가능 -> Aging 방법으로 해결 가능.
2) 라운드 로빈 - 정해진 시간 할당량만큼 프로세스를 할당, 작업이 끝난 프로세스는 준비완료 큐의 가장 마지막에 가서 재할당을 기다리는 방법.
- 시간 할당량이 너무 작으면 빈번한 문맥 전환이 발생, 너무 길면 FCFS(선입선출)와 다를 바 없음.
3) 다단계 큐 - 준비완료 큐를 여러 개의 큐로 분류하여 각 큐가 각각 다른 스케쥴링 알고리즘을 가지는 방식.
- 큐와 큐 사이에도 스케쥴링 필요. 우선 순위 방식 or 시분할 방식
비선점 스케쥴링
1) FCFS (First Come, First Serve)
- 먼저 도착한 프로세스를 먼저 처리.
- FIFO 큐를 이용하여 간단하게 구현.
- 호위효과 발생하는데, 긴 처리 시간의 프로세스가 선점되어 버리면 나머지 프로세스들은 끝날 때까지 대기해야 함.
2) SJF (Shorted Job First) - 수행시간이 가장 짧다고 판단되는 작업 먼저 수행.
- 최적이긴 하지만 다음 프로세스의 버스트 시간을 계산하기 어렵다는 단점이 있어 '비슷할 것이다.'라고 추측을 통해 진행하기도 함.
3) HRN (Highest Response-ratio Next) - 우선 순위를 계산하여 점유 불평등 보완(SJF 단점 보완)
1-3. 스케쥴링 동작시점
프로세스의 상태변화와 스케쥴링
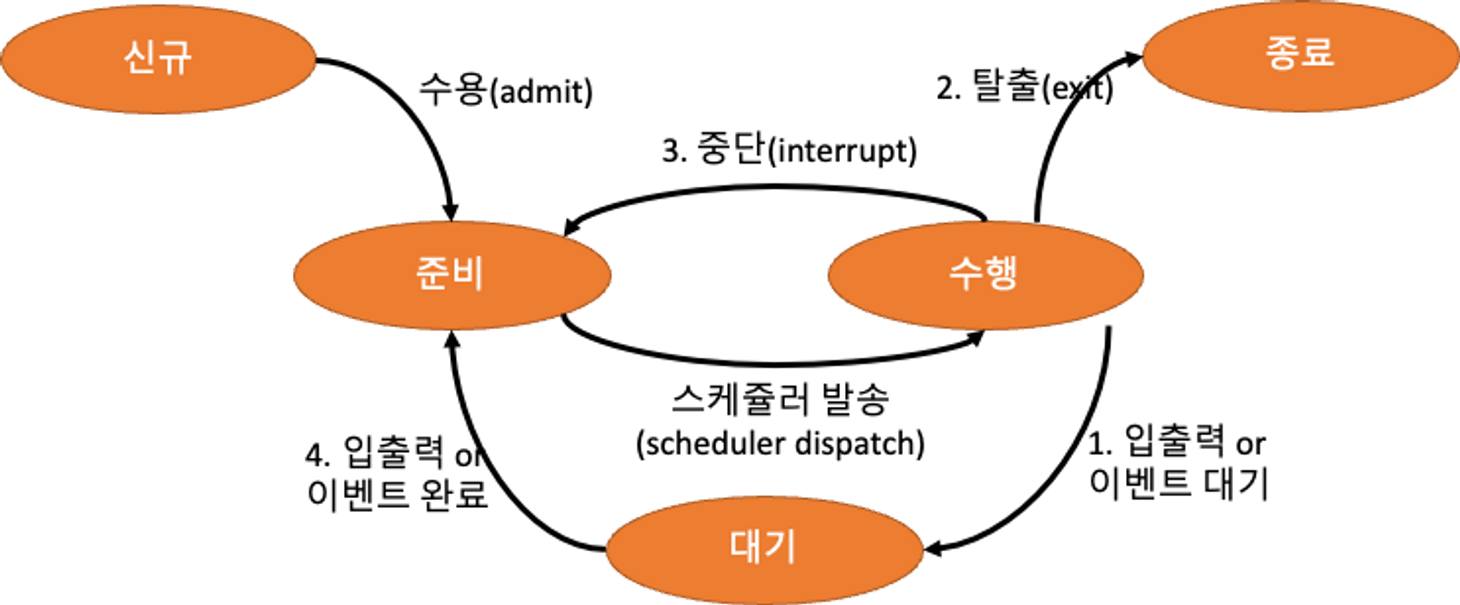
1. 수행 -> 대기 (Running->Waiting) : I/O요청이 발생하거나, 자식 프로세스가 종료 대기를 할 때
2. 수행 -> 종료 (Running -> Terminate) : 프로세스를 종료시켯을때
3. 수행 -> 준비 (Running-> Ready) : 인터럽트가 발생했을때
4. 대기 -> 준비 (Waiting -> Ready) : I/O가 완료되었을때
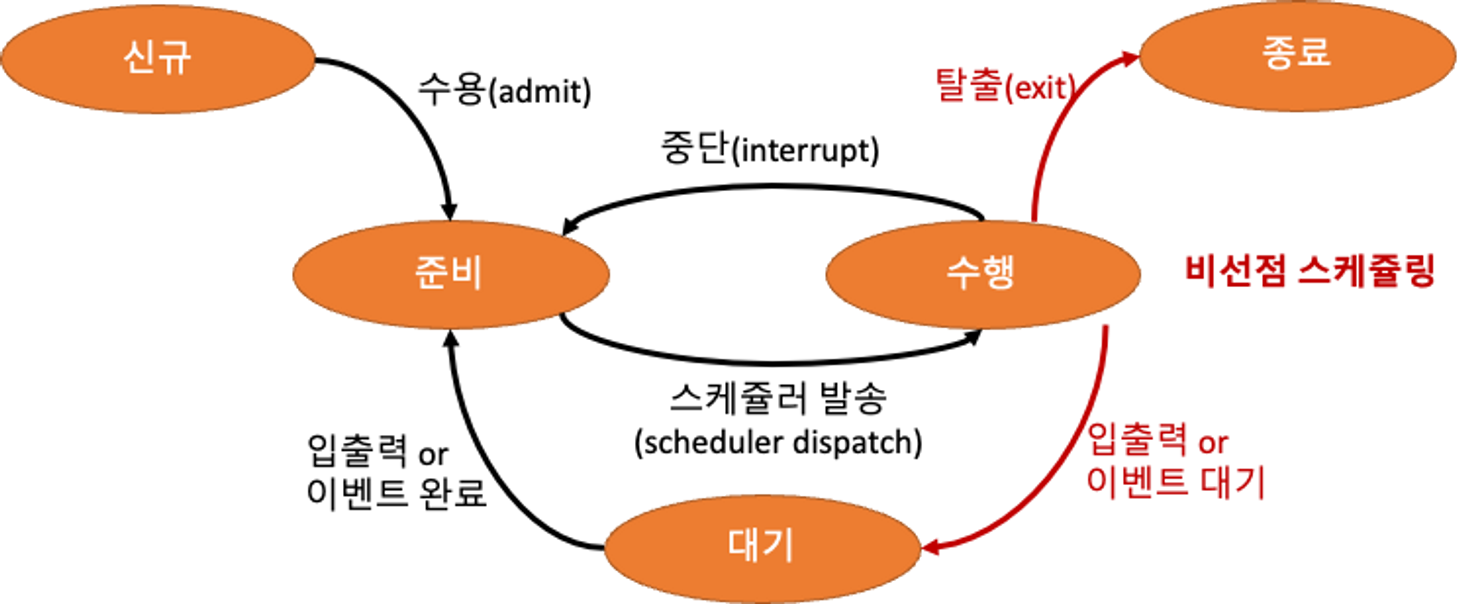
- 1,2은 프로세스가 스스로 CPU를 반환하기에 비선점 스케쥴링이 발생
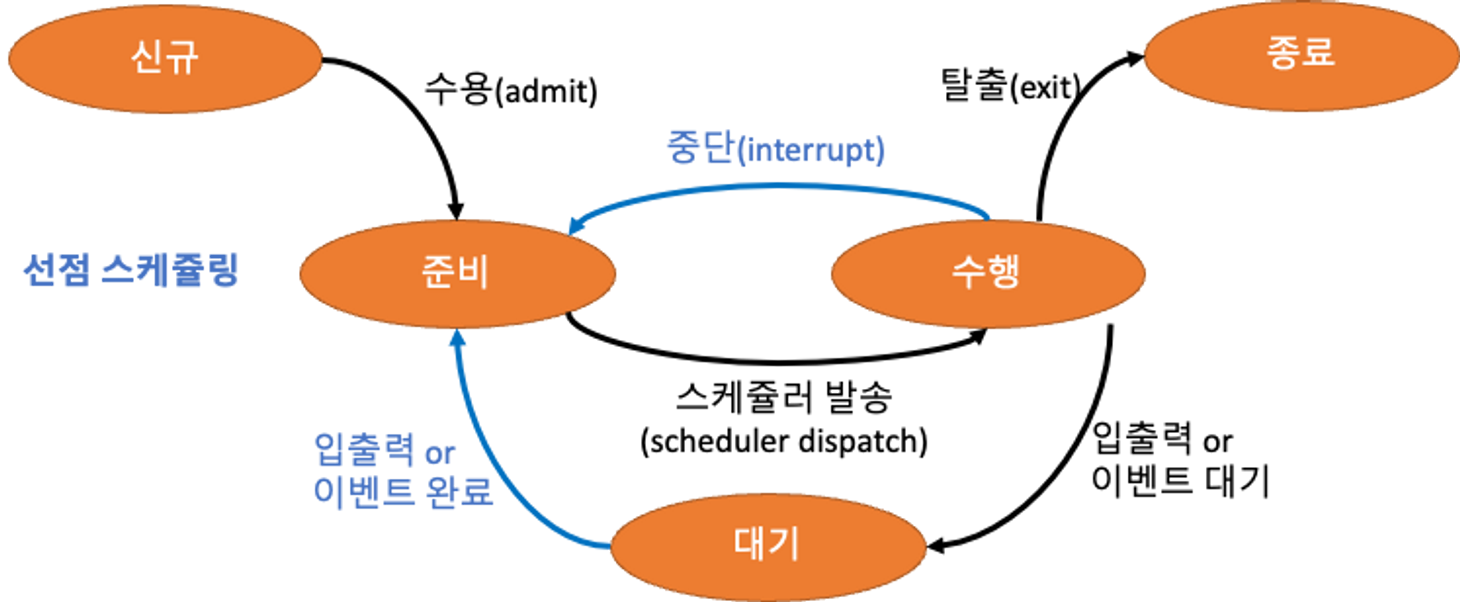
- 3,4은 프로세스에서 CPU를 강제로 할당(회수)해야 하므로 선점 스케쥴링 이 발생
2. 메모리 심화
2-1. 캐시란?
- 캐시는 데이터를 미리 복사해놓은 임시 저장소
- 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리.
지역성의 원리
- 지역성 : 자주 사용되는 데이터의 특성.
- 시간 지역성 : 최근 사용한 데이터에 다시 접근하려는 특성.
- 공간 지역성 : 최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성.
2-2. 캐시히트와 캐시미스
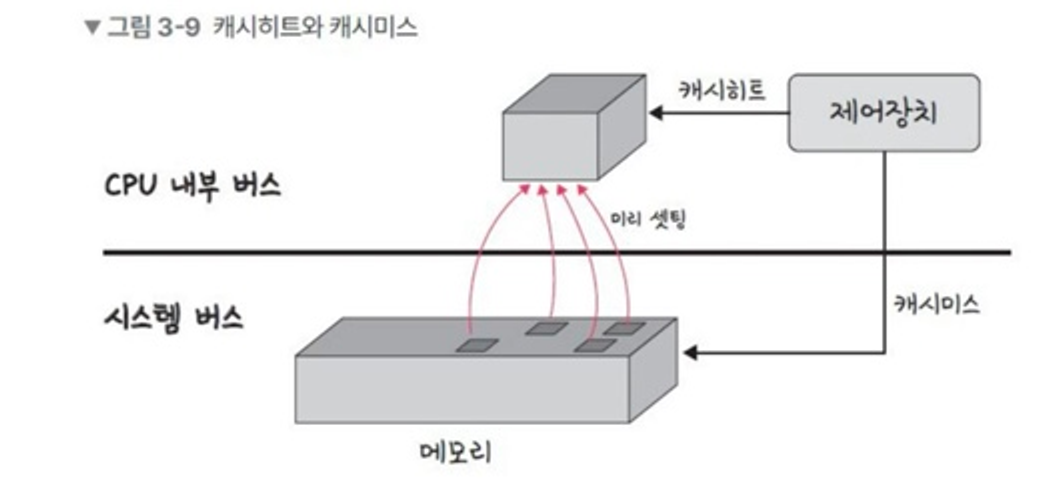
캐시히트
- 위치도 가깝고 CPU 내부버스를 기반으로 작동하여 빠름.
- 해당 데이터를 제어장치를 거쳐 가져오게 함.
캐시미스
- 해당 데이터가 캐시에 없다면 주메모리로 가서 데이터를 찾아오는 것.
- 메모리를 가져올 때 시스템 버스를 기반으로 작동하기 때문에 느림.
캐시 매핑
- 캐시가 히트되기 위해 매핑 되는 방법
- 직접 매핑 : 처리가 빠르지만 충돌 발생이 잦음.
- 연관 매핑 : 순서를 일치하지 않고 관련 있는 캐시와 메모리를 매핑. 충돌은 적지만 모든 블록을 탐색하여 속도가 느림.
- 집한 연관 매핑 : 직접 매핑 + 연관 매핑. 순서는 일치하지만 집합을 둬서 저장하며 블록화 되어 있어 검색이 효율적.
2-3. 메모리 할당
연속 할당
- 고정 분할 방식 : 메모리를 미리 나누어 관리하는 방식.
- 가변 분할 방식 : 프로그램의 크기에 맞게 동적으로 메모리를 나눠 사용.
불연속 할당
- 링크드 리스트 : 불연속 공간에 프로세스를 할당할 때, 할당된 공간의 주소를 연결 리스트에 저장. 할당과 해제가 빠르지만, 공간 낭비 발생할 수 있음.
- 비트맵 : 메모리 공간의 각 블록을 0 또는 1로 표시, 사용 가능과 사용 중 블록을 구분.
- 페이지 테이블 : 가상 메모리 시스템에서 사용. 물리적인 주소 공간을 페이지라는 작은 블록으로 나누어 사용.
1) 페이징 - 동일한 크기의 페이지 단위 나누어 메모리의 서로 다른 위치에 프로세스 할당.
2) 세그멘테이션 - 코드와 데이터 등을 기반으로 나눌 수 있으며, 함수 단위로 나눌 수도 있음.
3) 페이지드 세그멘테이션 - 공유나 보안은 세그먼트로 나누고 물리적 메모리는 페이지로 나누는 방식.
- 페이지 교체 알고리즘
- 오프라인 알고리즘 : 먼 미래에 참조되는 페이지와 현재 할당하는 페이지를 바꾸는 알고리즘- 시간기반 알고리즘
: FIFO (First In First Out) - 가장 먼저 온 페이지를 교체 영역에 가장 먼저 놓는 방법
: LRU(Least Recently Used) - 참조가 가장 오래된 페이지를 교체하는 방법
: NUR(Not Used Recently) - 최근 사용여부를 0,1로 표시하여 교체하는 방법 - 빈도기반 알고리즘
: LFU(Least Frequently Used) - 가장 참조 횟수가 적은 페이지를 교체
- 시간기반 알고리즘

꾸준히 하자