지난 면접에서 나 스스로 인정했듯이, 그간 경험했던 프로젝트에서 나는 'Spark를 사용하여 개발'한 게 아니라, 'Spark가 있는 환경에서 Python을 사용하여 개발'을 하고 있었다.
그만큼 내가 개발을 진행했던 환경(Azure 내의 데이터 서비스들)에서는 Spark를 구성하는 다양한 요소들에 대해 클라우드가 많은 부분을 대신해주고 있었고, 이는 개발 편의성 측면에서 많은 장점이 있겠지만 개발자 본인에게는 약점이 될 수도 있는 부분인 것 같다.
따라서 단순히 'Spark를 본 적이 있다, Spark에서 데이터 처리하는 코드 짤 수 있다' 수준을 넘어서기 위해서는 Spark의 내부 구조를 파악하고, 이를 사용하는 사이드 프로젝트를 진행해보는 것이 현재 단계에서는 필요한 경험이라 생각되었다. 이 문서를 작성하는 이유는, 이 경험의 첫 단계로 Spark를 제대로 공부해보기 위함이다. 분명 언젠가는 도움이 되겠지...
Spark 개요
Apache Spark는 널리 알려진 대로 데이터 분산처리 프레임워크로, 이전의 Hadoop MapReduce의 성능상 한계를 극복하기 위해 만들어진 프레임워크이다.

기존의 Hadoop 기반의 분산처리 시스템과는 다르게, Spark 상에서는 Batch Processing 뿐만 아니라 Streaming도 가능하다. 또한 Scala, R, Python 등 여러 언어로 접근 가능하다는 장점이 있으며, MLlib, GraphX등 다양한 라이브러리의 지원을 받을 수 있다.
또한 Spark의 장점 중 하나는 데이터 처리가 Memory 내에서 이루어지므로 Disk 내에서 처리하는 Hadoop에 비해 월등히 뛰어난 성능을 보장한다는 점이다. 이러한 장점으로 인하여 Hadoop이 차지하고 있던 데이터 분산처리의 기술적 표준을 빠르게 차지하였다.
다만 Spark가 Hadoop을 대체하는 상위호환 개념은 아니다. Spark는 Hadoop Ecosystem 내의 다양한 컴포너트(HBase, Hive 등)과 연동할 수 있으며, 후술할 Cluster Manager로 Hadoop YARN을 사용할 수 있는등 Hadoop과 상호보완적인 프레임워크라고 할 수 있다.
Spark 아키텍처
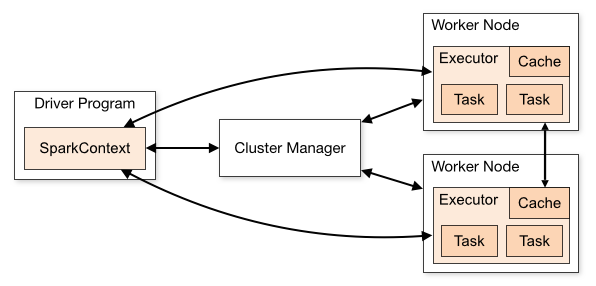
Spark는 Application(Driver, Worker)과 Cluster Manager로 구성된다.
Driver Program : Spark의 메인 프로그램으로, 클러스터 내의 마스터 노드에서 실행된다. 리소스 관리나 Worker node에 대한 작업 스케줄링을 담당한다. SparkContext는 일종의 진입점으로, 클러스터 매니저와의 통신하며 Task를 배포하고, 자원을 관리한다.
Worker Node : Driver로부터 할당받은 Task를 처리하는 노드. 내부에는 Executor라는 프로세스가 있는데, Worker Node는 이 프로세스를 실행하여 Task를 처리한다. Worker Node는 일반적으로 여러 개가 존재하며, 하나만 있을 시 Single Node라고 표현한다.
Cluster Manager : 리소스 관리, 고가용성 보장, 클러스터의 확장 및 축소를 담당한다. 여러 종류의 클러스터 매니저가 있는데, 스파크 내장 Stand-Alone, Apache Mesos, Hadoop YARN, Kubernetes 등이 있다.
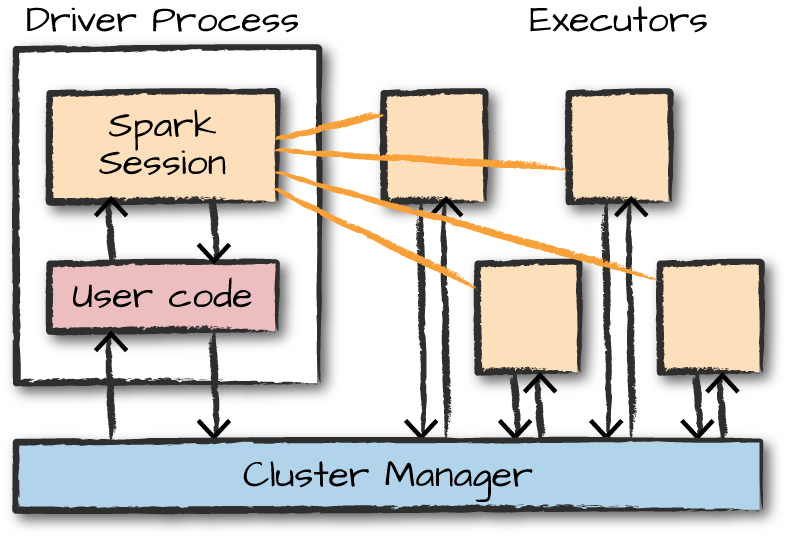
이 그림이 좀 더 직관적인 모습인 것 같다. 그림에서 확인할 수 있듯 SparkSession(2.0 이후, 그 전에는 SparkContext)은 코드와 통신하여 작업을 처리한다.
