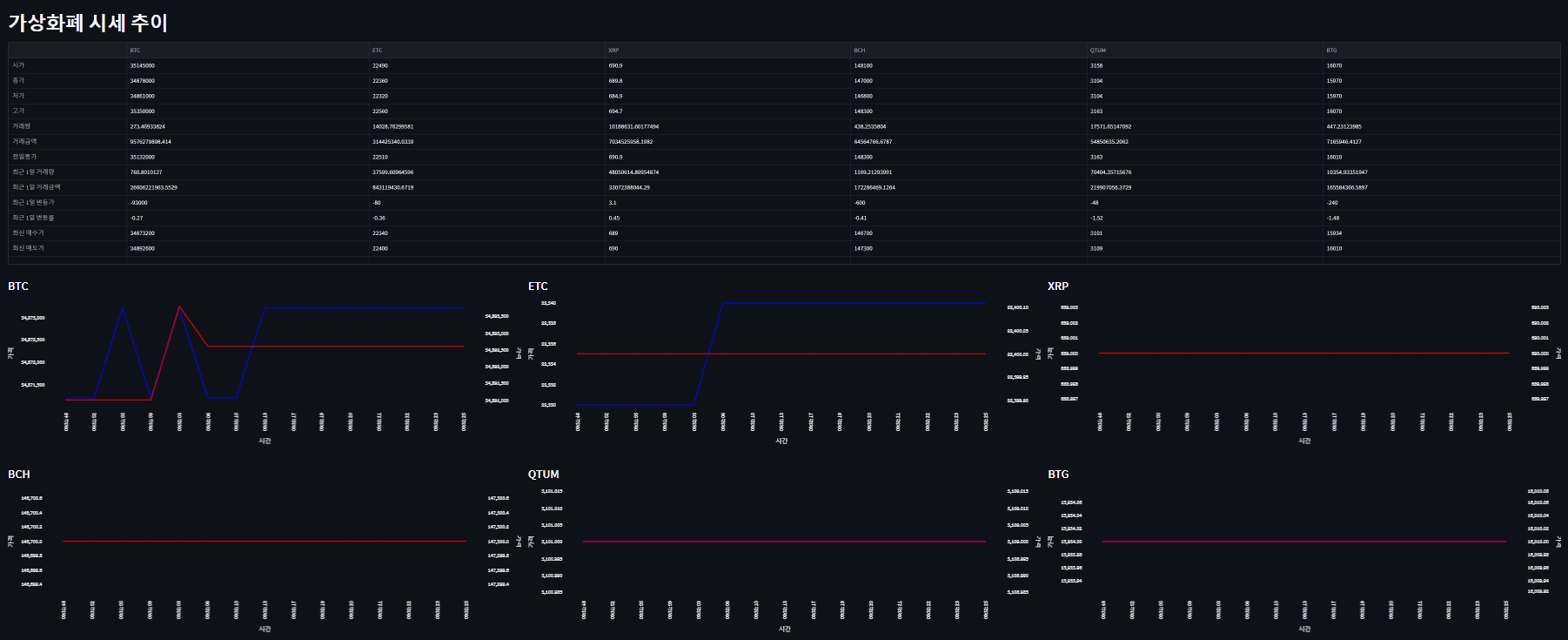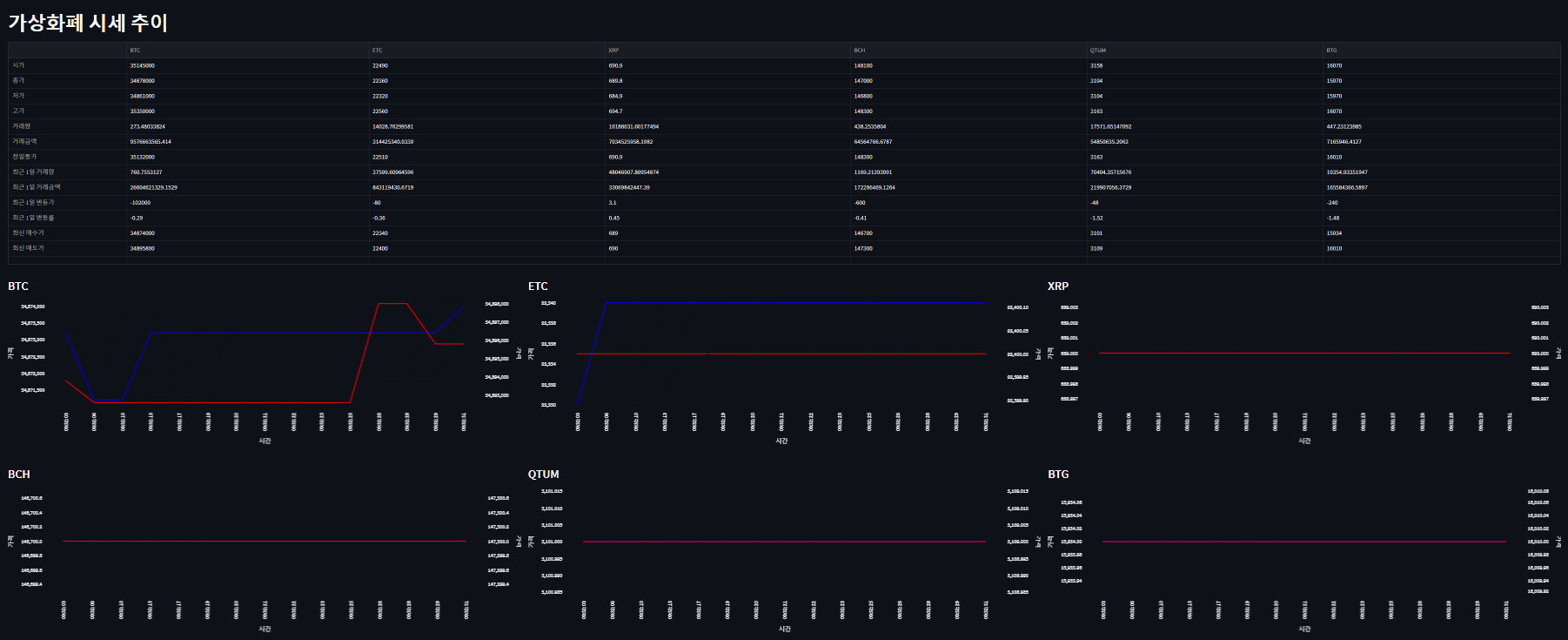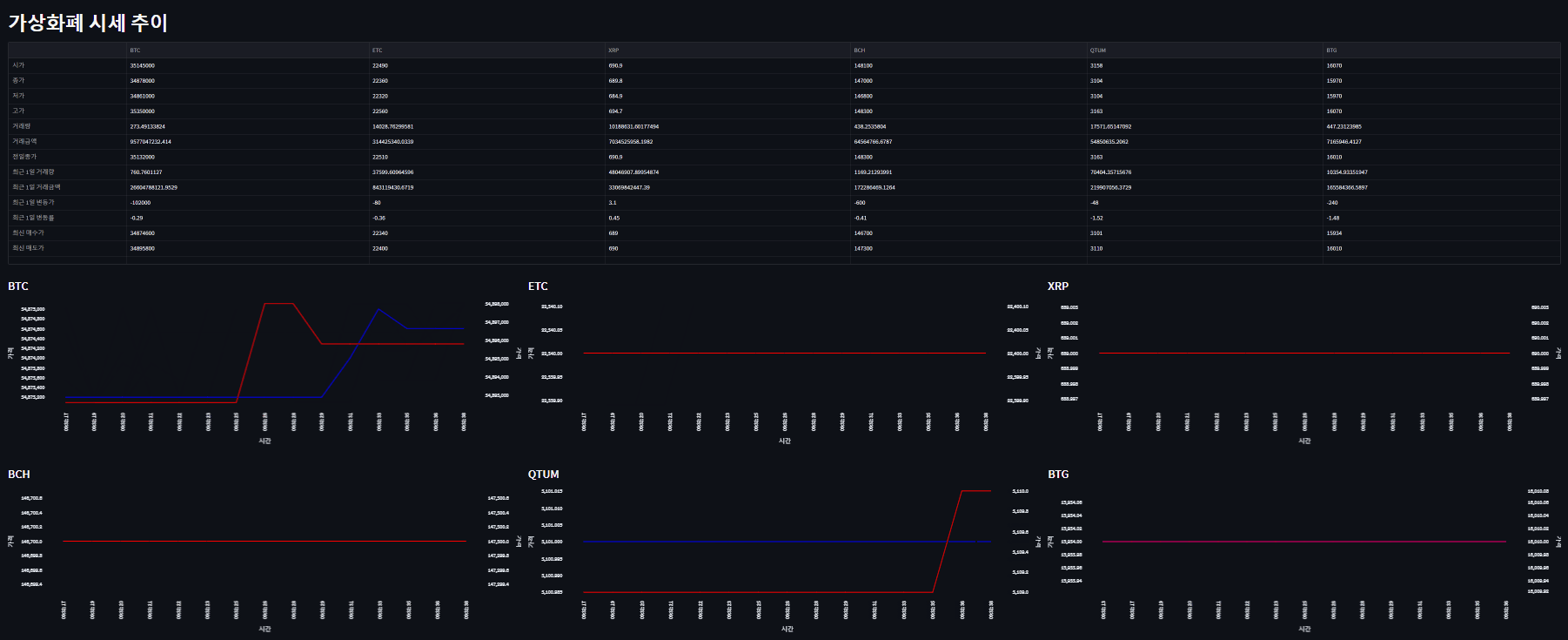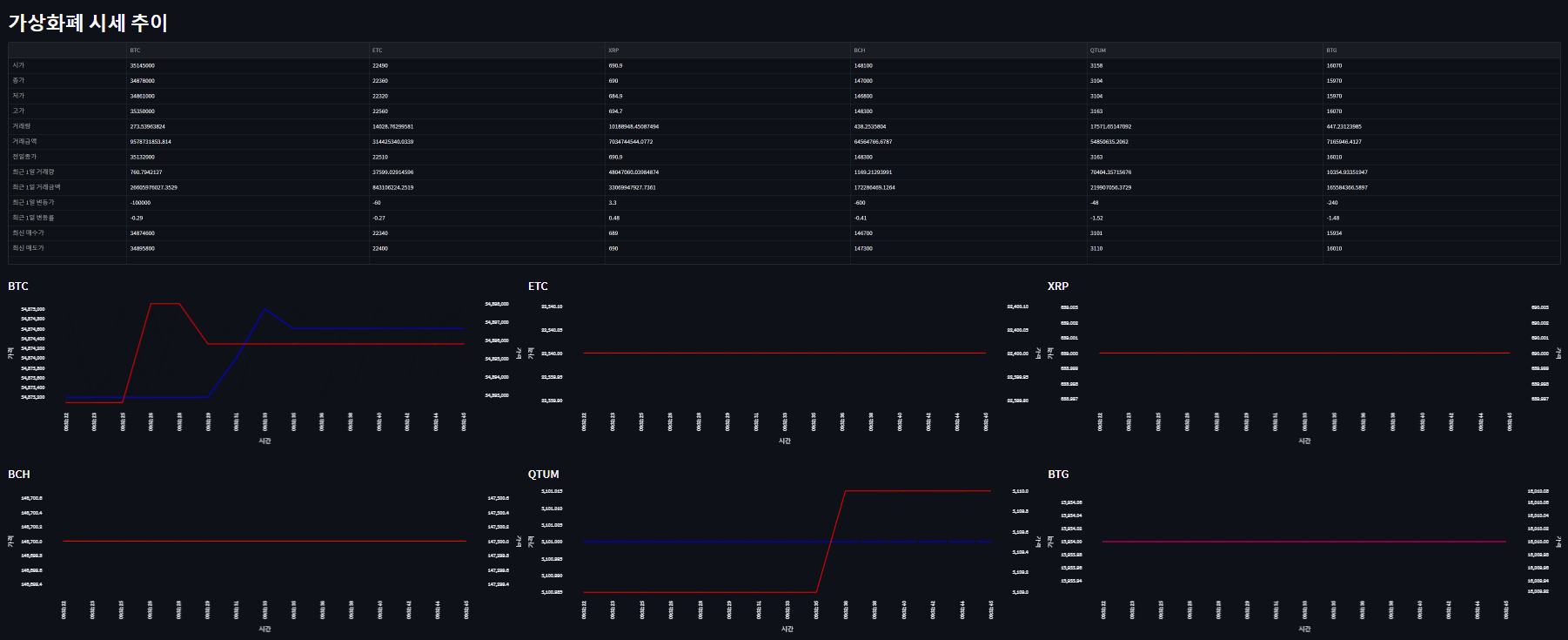
Github : https://github.com/ScrewlessKingjo/CoinPrice_Dashboard

Redis와 Streamlit을 이용해 사이드 프로젝트를 진행하였다. 프로젝트에 대한 개요는 Github에 나와있으니, 진행하며 생겼던 문제점, 앞으로의 보완 방향에 대해서 생각해보면 좋을 것 같다.
Library & Framework
Streamlit
Streamlit은 파이썬으로 인터랙티브한 웹 애플리케이션을 빠르고 간편하게 구축할 수 있는 오픈 소스 라이브러리이다.
주요 특장점은 다음과 같다.
-
간단한 구조: Streamlit은 파이썬 스크립트에 직접 코드를 작성하므로 개발자가 추가 프레임워크나 구조에 대해 걱정할 필요가 없다. 간단하고 직관적인 구조로 빠르게 애플리케이션을 작성할 수 있다.
-
실시간 업데이트: Streamlit 애플리케이션은 실시간으로 업데이트되며, 코드를 수정하면 자동으로 브라우저에서 변경 사항이 반영된다. 이를 통해 개발자는 빠른 피드백 루프를 유지하고 시각적인 결과를 실시간으로 확인할 수 있다.
-
다양한 컴포넌트: Streamlit은 다양한 종류의 컴포넌트를 제공하여 텍스트, 이미지, 그래프, 테이블 등 다양한 형태의 데이터를 표시할 수 있다. 또한 사용자 입력을 받아 처리하는 버튼, 슬라이더, 체크박스 등의 컴포넌트도 제공한다.
-
대화형 요소: Streamlit은 사용자와 상호작용할 수 있는 대화형 요소를 제공하여 사용자 입력에 따라 결과를 동적으로 업데이트할 수 있다. 사용자 입력을 통해 데이터를 필터링하거나 파라미터를 조정하여 결과를 실시간으로 확인할 수 있다.
-
배포 및 공유: Streamlit으로 작성한 애플리케이션은 간단한 명령어로 로컬 머신에서 실행할 수 있을 뿐만 아니라, 클라우드 플랫폼에 배포하여 다른 사람과 공유할 수도 있다.
전 직장에서 한번 사용해본 적이 있었는데, 프로젝트가 유야무야되서 사실 '이런 게 있구나' 정도만 경험했었던 것 같다. 데이터나 ML 프로젝트를 하면 이걸 어떤 애플리케이션에 띄울지도 고민 거리인데, 그런 부분에서 간편하게 빌드해서 대시보드를 만들 수 있다는 건 큰 장점인 것 같다.
다만 사용을 해보니 실시간 업데이트를 지원하지 않는 컴포넌트가 좀 많았던 것 같다... matplotlib이나 seaborn 같은 훌륭한 시각화 라이브러리에 익숙해져서 그런지, 컴포넌트에 대한 커스터마이징도 다소 제한적이었던 것 같다. (사실 streamlit 안에서도 이런 시각화 라이브러리들을 import 받아서 사용 가능하다) 그래도 디자인에 영 젬병인 나 같은 개발자도 '그럴싸하게' 대시보드를 만들 수 있다는 건 큰 장점인 것 같다.
Redis
Redis는 인메모리 데이터 스토어로서 오픈 소스 기반의 키-값(key-value) 데이터베이스 시스템이다. Redis는 Remote Dictionary Server의 약자이며, 데이터를 메모리에 저장하고 조회하기 위한 빠른 읽기 및 쓰기 성능을 제공한다.
주요 특장점은 다음과 같다:
속도와 성능: Redis는 데이터를 메모리에 저장하고 처리하기 때문에 매우 빠른 읽기 및 쓰기 성능을 제공한다. 이를 통해 실시간 캐싱, 세션 관리, 메시지 큐 등 다양한 용도로 사용할 수 있다.
다양한 데이터 구조: Redis는 단순한 키-값 저장소뿐만 아니라 다양한 데이터 구조를 지원한다. 문자열, 해시, 리스트, 셋, 정렬된 셋 등의 데이터 구조를 활용하여 다양한 데이터 모델을 구축할 수 있다.
지속성: Redis는 데이터를 메모리에 저장하면서 동시에 디스크에도 저장할 수 있다. 이를 통해 데이터의 지속성을 보장하고 시스템 장애 시에도 데이터를 복구할 수 있다.
분산 시스템 지원: Redis는 클러스터링을 통해 데이터를 여러 노드에 분산하여 저장하고 처리할 수 있다. 이를 통해 확장성과 고가용성을 제공하며 대용량 데이터 처리에 유용하다.
NoSQL의 하위 분류라 할 수 있는 Key-Value 데이터베이스의 대표적인 DB. 특장점에서 언급하듯 인메모리에서 job을 처리하므로 매우 빠르게 데이터를 조회하거나 쓸 수 있다! 아직 더 써봐야 알겠지만, 일반적인 rdb에서 느낄 수 있는 속도와는 확연히 다른 모습을 보여준다. 또한 데이터 구조가 여러 가지가 있어 잘 활용할 수만 있다면 NoSQL을 사용할 때 항상 겪는 문제점인 조회 후 Parsing을 고려한 쓰기가 가능할 것 같다.
개발 과정
데이터 적재
def OrderbookDataCollector(url, headers,key_list):
result_dict = {}
response = requests.get(url, headers=headers)
data = json.loads(response.text)['data']
for key in key_list :
bid_list = []
asks_list = []
for count in data[key]['bids']:
bid_list.append(float(count['price']))
for count in data[key]['asks']:
asks_list.append(float(count['price']))
result_dict[key] = {'bids' : int(np.round(sum(bid_list)/len(bid_list), 0)),
'asks' : int(np.round(sum(asks_list)/len(asks_list), 0))}
return result_dict
def DataCollector(url, headers,key_list, rd) :
result_dict = {}
response = requests.get(url['ticker'], headers=headers)
data = json.loads(response.text)['data']
unix_time = int(data['date']) / 1000
datekey = datetime.datetime.fromtimestamp(unix_time).strftime('%Y-%m-%d %H:%M:%S')
for key in key_list :
result_dict[key] = data[key]
orderbook_data = OrderbookDataCollector(url['orderbook'], headers, key_list)
combined_dict = {
currency: {
**values,
'bids': orderbook_data[currency]['bids'],
'asks': orderbook_data[currency]['asks']
}
for currency, values in result_dict.items()
}
jsonDataDict = json.dumps(combined_dict, ensure_ascii=False).encode('utf-8')
rd.set(datekey, jsonDataDict)
return None
두 가지의 API를 받아, 데이터를 원하는 형태로 변환하여 적재하기를 원하였으므로 두 개의 함수를 만들어 데이터 적재를 진행했다. Orderbook API에서 필요한건 매수가(bids)와 매도가(asks) 뿐이었으므로 두 key만 파싱하여 return하도록 하였고, DataCollector 함수에서 각 가상화폐 별로 매수가와 매도가를 추가한 뒤 Redis에 저장하였다.
def GetLatestData(redis_client, count):
keys = redis_client.keys()
sorted_keys = sorted(keys, reverse=True)
temp_dict = {}
for key in sorted_keys[:count]:
value = redis_client.get(key)
temp_dict[key.decode()] = json.loads(value.decode())
return temp_dict
def DataFrameGenerator(result, key_list):
result_dict = {}
for coin in key_list:
df_list = []
for dict_key in result.keys():
df_list.append(result[dict_key][coin])
df = pd.DataFrame(df_list, index=result.keys())
result_dict[coin] = df
return result_dict
레디스에서 데이터를 조회하여 가져오는 함수도 만들었다. 나는 Redis를 사용해본 적이 없어서, RDB처럼 그냥 order by로 최신 데이터를 가져와야겠다 생각을 하고 있었는데, 그런 기능을 사용하기 위해서는 Sorted Set이라는 데이터 구조를 활용해야 했다. 일단 나중에 개선하기로 하고, 일괄적으로 key값을 불러와 그 key를 정렬하여 최신 데이터를 가져왔다. 당연히 성능에 큰 제약이 되겠지만, 원체 속도가 빨라 아직까지는 느끼지 못했다.
GetLatestData 함수에서 일자 별로 데이터를 가져온 다음, 대시보드를 만들기 위해 DataFrameGenerator 함수에서 coin 별로 데이터를 추출해 딕셔너리에 담아 리턴하였다.
조회 함수를 재활용할 생각으로 함수를 분리해놨는데, 생각해보니 굳이 분리되어 있을 필요는 없는 것 같기도 하다.
def DataLoader(rd, data_count, KEY_LIST):
data_list = GetLatestData(rd, data_count)
df_dict = DataFrameGenerator(data_list, KEY_LIST)
return df_dict일일이 치기 귀찮아서...매우 안좋은 방법이지만 두 함수를 호출하는 함수를 별도로 만들었다.
def ChartDataFilter(df):
columns_keep = ['min_price', 'max_price', 'bids', 'asks']
columns_drop = [col for col in df.columns if col not in columns_keep]
df_filtered = df.drop(columns_drop, axis=1)
return df_filtered[::-1]
def TableDataFilter(df_dict) :
index = ['시가', '종가', '저가', '고가', '거래량', '거래금액', '전일종가', '최근 1일 거래량', '최근 1일 거래금액', '최근 1일 변동가', '최근 1일 변동률', '최신 매수가', '최신 매도가']
for coin in df_dict.keys():
df = pd.DataFrame(df_dict[coin])
df.index= index
return dfchart를 그리는데 사용되는 df로 가공하는 함수와, Table 만드는 df를 가공하는 함수를 별도로 만들었다. Chart에는 매수가와 매도가만 띄울 생각이어서 해당하는 컬럼만 추출했다.
import time
import streamlit as st
import altair as alt
import pandas as pd
import redis
import DataHandler as DH
URL_DICT = {
'ticker': 'https://api.bithumb.com/public/ticker/ALL_KRW',
'orderbook': 'https://api.bithumb.com/public/orderbook/ALL_KRW'
}
HEADERS = {"accept": "application/json"}
KEY_LIST = ['BTC', 'ETC', 'XRP', 'BCH', 'QTUM', 'BTG']
rd = redis.StrictRedis(host='localhost', port=6379, db=0)
data_count = 15
def Load(url, headers, _rd, data_count, KEY_LIST):
DH.DataCollector(url, headers, KEY_LIST, _rd)
dataset = DH.DataLoader(_rd, data_count, KEY_LIST)
return dataset
def Line_Chart(data):
chart_df = DH.ChartDataFilter(data)
x = pd.Series(pd.to_datetime(chart_df.index)).dt.strftime('%H:%M:%S')
bid_price = chart_df['bids']
asks_price = chart_df['asks']
data = pd.DataFrame({'x': x, 'bids': list(bid_price), 'asks': list(asks_price)})
bid_scale = alt.Scale(domain=(data['bids'].min()*0.999995, data['bids'].max()*1.000005))
asks_scale = alt.Scale(domain=(data['asks'].min()*0.999995, data['asks'].max()*1.000005))
bid_line = alt.Chart(data).mark_line(color='blue').encode(
x=alt.X('x', axis=alt.Axis(title='시간')),
y=alt.Y('bids', scale=bid_scale, axis=alt.Axis(title='가격')),
tooltip=['x', 'bids'])
asks_line = alt.Chart(data).mark_line(color='red').encode(
x=alt.X('x', axis=alt.Axis(title='시간')),
y=alt.Y('asks', scale=asks_scale, axis=alt.Axis(title='가격')),
tooltip=['x', 'asks'])
chart = alt.layer(bid_line, asks_line).resolve_scale(y='independent')
return chartChart를 생성하는 함수. altair를 Streamlit에서 호출하는 라이브러리를 이용해 차트를 만들었다. streamlit에도 자체적인 line chart가 있지만, 미관상 좋지 않을 뿐더러(테마를 config해주면 해결되는 문제이긴 했다) 실시간성으로 데이터를 업데이트 하는 기능이 부실했다. Community에도 altair를 활용하라는 이야기만 있어서, altair를 사용한 차트를 그렸다.
다만 여기에도 문제가 하나 있었는데, altair에는 범례를 나타내주는 기능이 없었다! 어차피 2개 line만 있으므로, 반드시 필요하지는 않을 것 같다고 생각해 더 깊게 파보지는 않았다.
st.set_page_config(layout="wide")
st.title('가상화폐 시세 추이')
with st.container():
table = st.empty()
dataset = Load(URL_DICT, HEADERS, rd, data_count, KEY_LIST)
col1, col2, col3 = st.columns(3)
with col1:
st.subheader('BTC')
BTC_Chart = Line_Chart(dataset['BTC'])
chart_component1 = st.altair_chart(BTC_Chart, use_container_width=True)
with col2:
st.subheader('ETC')
ETC_Chart = Line_Chart(dataset['ETC'])
chart_component2 = st.altair_chart(ETC_Chart, use_container_width=True)
with col3:
st.subheader('XRP')
XRP_Chart = Line_Chart(dataset['XRP'])
chart_component3 = st.altair_chart(XRP_Chart, use_container_width=True)
col4, col5, col6 = st.columns(3)
with col4:
st.subheader('BCH')
BCH_Chart = Line_Chart(dataset['BCH'])
chart_component4 = st.altair_chart(BCH_Chart, use_container_width=True)
with col5:
st.subheader('QTUM')
QTUM_Chart = Line_Chart(dataset['QTUM'])
chart_component5 = st.altair_chart(QTUM_Chart, use_container_width=True)
with col6:
st.subheader('BTG')
BTG_Chart = Line_Chart(dataset['BTG'])
chart_component6 = st.altair_chart(BTG_Chart, use_container_width=True)데이터를 불러오고, 웹에서 표시될 streamlit의 레이아웃을 설정하였다. 최 상단에 있는 st.empty()는 이후 테이블을 넣을 자리로, 후술할 While문에서 데이터를 채워넣기 위해 일단은 객체 선언만 해두었다. 그리고 아까 만든 Line_Chart 함수를 사용하여 각 컨테이너마다 Chart 객체를 선언하고, 초기에 불러온 데이터셋을 통해 라인 차트를 그렸다.
여기서 볼 수 있듯, Streamlit은 다른 웹 프레임워크 & 시각화 라이브러리에 비해 간단하게 프론트 딴을 설정할 수 있어서 매우 좋다. 대신 지원하는 기능이 아직은 많지 않아, 더 복잡한 커스터마이징이 필요할 경우 다소 복잡해지는 문제점이 있다고 한다.
while True:
dataset = Load(URL_DICT, HEADERS, rd, data_count, KEY_LIST)
chart_component1.altair_chart(Line_Chart(dataset['BTC']), use_container_width=True)
chart_component2.altair_chart(Line_Chart(dataset['ETC']), use_container_width=True)
chart_component3.altair_chart(Line_Chart(dataset['XRP']), use_container_width=True)
chart_component4.altair_chart(Line_Chart(dataset['BCH']), use_container_width=True)
chart_component5.altair_chart(Line_Chart(dataset['QTUM']), use_container_width=True)
chart_component6.altair_chart(Line_Chart(dataset['BTG']), use_container_width=True)
table_dataset = DH.GetLatestData(rd, 1)
table_data = DH.TableDataFilter(table_dataset)
table.dataframe(table_data.astype(str), width=2200, height=512, use_container_width=True)
time.sleep(3)맨 하단의 반복문에서 데이터를 주기적으로 Redis에서 불러오고, 이를 통해 각 개체를 업데이트 하는 방식으로 수정하였다. 테이블 안에 들어가는 데이터를 통으로 업데이트하는 방식이라, 사실 올바르게 구현된 방식은 아닌 것 같다. 3초마다 업데이트 될 수 있도록 time을 걸어놓았다.
개선점
앞서 언급하였듯 데이터의 I/O를 최대한 줄이는 방향으로 코드를 바꾸는게 첫 번째 과제인 것 같다. 두 번째로, 지금은 두 가지 정보만 단순하게 보여주고 있는 정도라 대시보드라 부르기 민망한 정도인 것 같다. 추가적으로 몇 가지 정보를 더 띄워주면 좋을 것 같은데, 아직까지는 어떤걸 띄워줘야 할지 감이 안잡힌다. 머신러닝으로 가격 예측을 해봐도 좋을 것 같고...
