AWS의 RDS 프리티어 사용
서비스 테스트 이전에 DB 성능 테스트
서버는 로컬 환경이라 스레드 개수 제한을 두지 않았음
@SpringBootTest
class CourseRepositoryTest {
@Autowired
private CourseRepository courseRepository;
@Test
@Description("과목 코드로 조회")
void findAllBySubjectIdAndCourseYearAndSemester() {
long startTime = System.currentTimeMillis();
// Execute your JPA query
List<Course> results = courseRepository.findAllBySubjectIdAndCourseYearAndSemester(556L, 2023, 1).orElseThrow();
long endTime = System.currentTimeMillis();
long executionTime = endTime - startTime;
System.out.println("Query execution time: " + executionTime + " ms");
// Add assertions if needed
assertNotNull(results);
}
@Test
@Description("소속ID로 조회")
void findAllByCourseYearAndSemesterAndBelongId() throws InterruptedException {
long startTime = System.currentTimeMillis();
AtomicReference<List<Course>> results = new AtomicReference<>(new ArrayList<>());
final int executeNumber = 5000;
final ExecutorService executorService = Executors.newCachedThreadPool();
final CountDownLatch countDownLatch = new CountDownLatch(executeNumber);
final AtomicInteger successCount = new AtomicInteger();
final AtomicInteger failCount = new AtomicInteger();
// Execute your JPA query
for (int i = 0; i < executeNumber; i++) {
executorService.execute(() -> {
try {
results.set(courseRepository.findAllByCourseYearAndSemesterAndBelongId(2023, 1, 3L).orElseThrow());
successCount.getAndIncrement();
} catch (Exception e) {
failCount.getAndIncrement();
}
countDownLatch.countDown();
});
}
countDownLatch.await();
long endTime = System.currentTimeMillis();
long executionTime = endTime - startTime;
System.out.println("Query execution time: " + executionTime + " ms");
System.out.println("쿼리 성공: " + successCount.get());
System.out.println("쿼리 실패: " + failCount.get());
// Add assertions if needed
assertEquals(failCount.get() + successCount.get(), executeNumber);
}
@Test
@Description("구분으로 조회")
void findAllByCourseYearAndSemesterAndSort() throws InterruptedException {
long startTime = System.currentTimeMillis();
AtomicReference<List<Course>> results = new AtomicReference<>(new ArrayList<>());
final int executeNumber = 5000;
final ExecutorService executorService = Executors.newCachedThreadPool();
final CountDownLatch countDownLatch = new CountDownLatch(executeNumber);
final AtomicInteger successCount = new AtomicInteger();
final AtomicInteger failCount = new AtomicInteger();
// Execute your JPA query
for (int i = 0; i < executeNumber; i++) {
executorService.execute(() -> {
try {
results.set(courseRepository.findAllByCourseYearAndSemesterAndSort(2023, 1, "기초교양").orElseThrow());
successCount.getAndIncrement();
} catch (Exception e) {
failCount.getAndIncrement();
}
countDownLatch.countDown();
});
}
countDownLatch.await();
long endTime = System.currentTimeMillis();
long executionTime = endTime - startTime;
System.out.println("Query execution time: " + executionTime + " ms");
System.out.println("쿼리 성공: " + successCount.get());
System.out.println("쿼리 실패: " + failCount.get());
// Add assertions if needed
assertEquals(failCount.get() + successCount.get(), executeNumber);
}
}세 가지 조회 테스트가있다. belongId와 SubjectCd는 Long타입이라 둘의 단건 조회 속도는 비슷하다. 평균 20ms
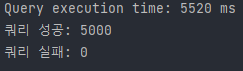
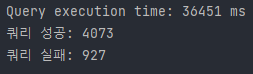
Sort라는 문자열로 조회했을 때 단건 조회 속도는 275ms 정도 나온다. 그렇게 느린 결과는 아닌데 문제는 rds가 프리티어라 동시처리로 들어갔을 때 이 쿼리 5천개가 처리가 안된다.
BelongId
Sort
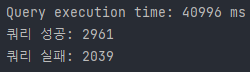
혹시 문자열 비교가 너무 빡센부분인가 싶어서 sort를 빼고 년도와 학기만으로 검색해봤다
@Test
@Description("년도 학기로만 검색")
void findAllByCourseYearAndSemester() throws InterruptedException {
long startTime = System.currentTimeMillis();
AtomicReference<List<Course>> results = new AtomicReference<>(new ArrayList<>());
final int executeNumber = 5000;
final ExecutorService executorService = Executors.newCachedThreadPool();
final CountDownLatch countDownLatch = new CountDownLatch(executeNumber);
final AtomicInteger successCount = new AtomicInteger();
final AtomicInteger failCount = new AtomicInteger();
// Execute your JPA query
for (int i = 0; i < executeNumber; i++) {
executorService.execute(() -> {
try {
results.set(courseRepository.findAllByCourseYearAndSemester(2023, 1).orElseThrow());
successCount.getAndIncrement();
} catch (Exception e) {
failCount.getAndIncrement();
}
countDownLatch.countDown();
});
}
countDownLatch.await();
long endTime = System.currentTimeMillis();
long executionTime = endTime - startTime;
System.out.println("Query execution time: " + executionTime + " ms");
System.out.println("쿼리 성공: " + successCount.get());
System.out.println("쿼리 실패: " + failCount.get());
// Add assertions if needed
assertEquals(failCount.get() + successCount.get(), executeNumber);
}검색되는 양이 더 많기 때문에 무조건 더 걸릴거라 생각했지만 혹시 내가 DB를 몰라서 그런걸까 했는데 그건 아니었다.

개발자호소인