스트림 처리
-
일괄 처리는 입력으로 파일 집합을 읽어 출력으로 새로운 파일 집합을 생성하는 기술
-
출력은 파생 데이터 형태이며, 필요하다면 일괄 처리를 다시 수행해 재생성 가능한 데이터셋을 의미
-
하지만 일괄 처리는 입력을 사전에 알려진 유한한 크기로 한정한다는 가정이 있음. 그리고 이는 조기에 출력을 시작할 수 없음을 의미(맵리듀스에서 마지막 레코드가 가장 낮은 키라면?)
-
하지만 데이터는 서비스가 지속되는한, 영원히 생성되며 데이터셋은 어떤 의미로든 절대로 "완료"되지 않음. 일괄 처리는 인위적으로 일정 기간씩 데이터 청크를 나누어 작업함
-
일괄 처리의 단점은 입력의 변화가 하루 또는 일정 주기가 지나야 반영된다는 점이며, 이런 지연을 줄이기 위해선 고정된 시간 조각(얼마나 짧을지라도)이라는 개념을 완전히 버리고 단순히 이벤트가 발생할 때마다 처리해야 함. 이러한 개념이 스트림 처리의 기본 개념
이벤트 스트림 전송
-
일괄 처리 환경에서 작업은 입출력 파일이며, 대개 처리를 위한 첫 번째 단계로는 파일을 분석해 레코드의 연속으로 바꾸는 처리를 함
-
스트림 처리 문맥에서 레코드는 보통 이벤트라고 하며, 일반적으로 일기준 시계를 따르는 이벤트 발생 타임스탬프를 포함
-
이벤트는 텍스트 문자열이나 JSON 또는 이진 형태 등으로 부호화되며 이 과정을 통해 저장됨(예를 들어 부호화한 이벤트를 파일에 덧붙이거나 관계형 테이블에 삽입하거나 문서 데이터베이스에 기록하는 식으로)
-
일괄 처리에서 파일은 한 번 기록되면 여러 작업자에서 읽을 수 있듯이, 스트리밍에서는 생산자(producer)가 이벤트를 한 번 만들면 여러 소비자(consumer)가 처리할 수 있음
-
파일 시스템에서는 관련 레코드 집합을 파일 이름으로 식별하지만 스트림 시스템에서는 대개 토픽(topic)이나 스트림으로 관련 이벤트를 묶음
-
이론적으로 파일이나 데이터베이스를 통해 생산자와 소비자를 연결시킬 수 있지만, 지연 시간이 낮으면서 지속적인 처리를 지향할 때 데이터 스토어는 용도에 맞게 설계하지 않았다면 폴링하는 비용이 큼
-
대신 스트림 처리에서는 이벤트 알림 전달 목적으로 개발된 특별한 도구들을 사용
메시징 시스템
-
새로운 이벤트에 대해 소비자에게 알려주려고 쓰이는 일반적인 방법은 메시징 시스템(messaging system)을 사용하는 것
-
생산자는 이벤트를 포함한 메시지를 전송하며, 메시지는 소비자에게 전달됨
-
메시징 시스템을 구축하는 가장 간단한 방법은 생산자와 소비자 사이에 유닉스 파이프나 TCP 연결과 같은 직접 통신을 사용하는 방법임
-
하지만 메시징 시스템 대부분은 이 기본 모델을 확장함. 특히 유닉스 파이프와 TCP는 전송자 하나를 정확히 수신자 하낭에 연결하지만, 메시징 시스템은 다수의 생산자 노드가 같은 토픽으로 메시지를 전송할 수 있고 다수의 소비자 노드가 토픽 하나에서 메시지를 받아갈 수 있음
-
이러한 발행/구독(publish/subscribe)모델에서는 여러 시스템들이 다양한 접근법을 사용하고 있으며, 아래 두 가지 질문이 시스템을 구별하는 데 도움이 될 수 있음
- 생산자가 소비자가 메시지를 처리하는 속도보다 빠르게 메시지를 전송한다면 어떻게 될까?
- 메시지를 버리거나
- 큐에 메시지를 버퍼링하거나
- 배압(backpressure, 흐름제어(flow control)라고도 함) 즉, 생산자가 메시지를 더 보내지 못하도록 막음
- 큐 크기가 메모리 크기보다 커지면 시스템이 중단되는가? 메시지를 디스크에 쓰는가? 디스크에 쓴다면 디스크 접근이 메시징 시스템의 성능에 어떤 영향을 주는가?
- 노드가 죽거나 일시적으로 오프라인이 된다면 어떻게 되는가? 손실되는 메시지가 있는가?
- 지속성을 갖추려면 디스크에 기록하거나 복제본을 생성하거나 둘 모두를 해야 함
- 때로 메시지를 잃어도 괜찮다면 같은 하드웨어에서 처리량은 높고 지연 시간은 낮출 수 있음
생산자에서 소비자로 메시지 직접 전달하기
-
많은 메시지 시스템은 중간 노드를 통하지 않고 생산자와 소비자를 네트워크로 직접 연결함
-
UDP 멀티캐스트는 낮은 지연이 필수인 주식 시장과 같은 금융 산업에서 널리 사용됨. UDP 자체는 신뢰성이 낮아도 애플리케이션 단의 프로토콜은 잃어버린 패킷을 복구할 수 있음
-
ZeroMQ 같은 브로커가 필요없는 메시징 라이브러리와 나노메시지(nanomsg) TCP 또는 IP 멀티캐스트 상에서 발행/구독 메시징을 구현함
-
StatsD와 BruBeck은 네트워크 상의 모든 장비로부터 지표를 수집하고 모니터링하는 데 UDP 메시징을 사용
-
소비자가 네트워크에 서비스를 노출하면 생산자는 직접 HTTP나 RPC 요청을 직접 보낼 수 있음. 이것은 웹후크(webhook)를 뒷받침하는 아이디어로 서비스 콜백 URL을 다른 서비스에 등록하는 형식임. 즉 웹후크는 이벤트가 발생할 때마다 콜백 URL로 요청을 보내는 방식임
-
-
직접 메시징 시스템은 설계 상황에서는 잘 동작하지만 일반적으로 메시지가 유실될 수 있는 가능성을 고려해서 애플리케이션 코드를 작성해야함
-
일부 프로토콜은 실패한 메시지 전송을 생산자가 재시도하게끔하지만 생산자 장비가 죽으면 재시도하려고 했던 메시지 버퍼를 잃어버릴 수 있다는 문제가 있음
메시지 브로커
-
직접 메시징 시스템의 대안으로 메시지 브로커(메시지 큐)를 주로 사용함
-
메시지 브로커는 근본적으로 메시지 스트림을 처리하는 데 최적화된 데이터베이스의 일종임
-
메시지 브로커는 서버로 구동되고 생산자와 소비자는 서버의 클라이언트로 접속함
-
생산자는 브로커로 메시지를 전송하고 소비자는 브로커에서 메시지를 읽어 전송받음
-
이러한 시스템은 브로커에 데이터가 모이기 때문에 클라이언트의 상태 변경(접속, 접속 해제, 장애)에 쉽게 대처할 수 있음
-
지속성의 문제가 생산자와 소비자에서 브로커로 옮겨갔기 때문
-
어떤 메시지 브로커는 메모리에만 메시지를 보관하며, 어떤 메시지 브로커는 브로커가 장애로 중단됐을 때도 메시지를 잃어버리지 않기 위해 디스크에 메시지를 기록함
-
또한 큐 대기를 하면 소비자는 일반적으로 비동기로 동작함. 생산자는 메시지를 보낼 때 브로커가 해당 메시지를 버퍼에 넣었는지만 확인하고 소비자가 메시지를 처리하기까지 기다리지 않음
-
메시지 브로커와 데이터베이스의 비교
-
데이터베이스는 명시적으로 데이터가 삭제될 때까지 데이터를 보관하지만, 메시지 브로커 대부분은 소비자에게 데이터가 전송된 경우 자동으로 데이터를 삭제함(오랜 기간 데이터를 저장하는 용도로는 적당하지 않음)
-
메시지 브로커는 대부분 메시지를 빨리 지우기 때문에 작업 집합이 상당히 작다고 가정함. 즉, 큐 크기가 작음
-
데이터베이스는 보조 색인을 지원하고 데이터 검색을 위한 다양한 방법을 지원하지만, 메시지 브로커는 특정 패턴과 부합하는 토픽의 부분 집합을 구독하는 방식을 지원함(방식은 다르지만 둘 다 본질적으로는 클라이언트가 데이텅에서 필요한 부분을 선택하는 방법임)
-
데이터베이스에 질의할 때 그 결과는 일반적으로 데이터 스냅숏을 기반으로 하지만 메시지 브로커는 임의 질의를 지원하지 않지만 데이터가 변하면 클라이언트에게 알려줌
-
이러한 특징은 메시지 브로커의 전통적인 관점으로 래빗MQ, 액티브MQ, 구글 클라우드 Pub/Sub 같은 소프트웨어로 구현됨
복수 소비자
-
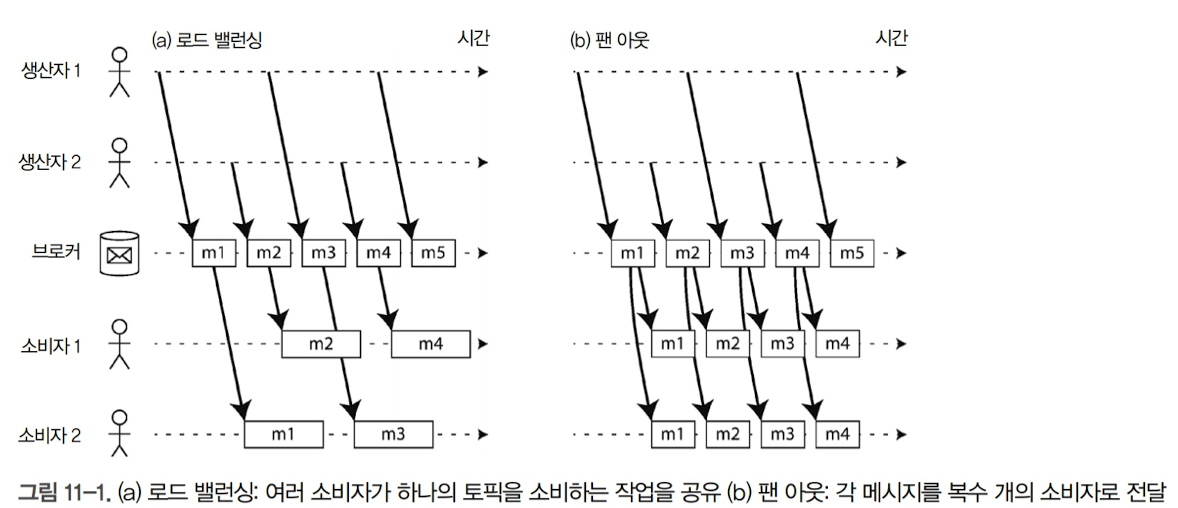
복수 소비자가 같은 토픽에서 메시지를 읽을 때 사용하는 주요 패턴 두 가지
-
로드 밸런싱
-
각 메시지는 소비자 중 하나로 전달되며 소비자들은 해당 토픽의 메시지를 처리하는 작업을 공유.
-
메시지를 처리하는 비용이 비싸서 처리를 병렬화하기 위해 소비자를 추가하고 싶을 때 유용함
-
이러한 방식을 공유 구독(shared subscription)이라고 함
-
-
팬아웃
- 각 메시지는 모든 소비자에게 전달됨. 여러 독립적인 소비자가 브로드캐스팅된 동일한 메시지를 서로 간섭 없이 청취하는 방식
-
이 두가지 패턴을 함께 사용하기도 함. 예를 들어 두 개의 소비자 그룹에서 하나의 토픽을 구독하고 각 그룹은 모든 메시지를 받지만 그룹 내에서는 각 메시지를 하나의 노드만 받게하는 식
-
확인 응답과 재전송
-
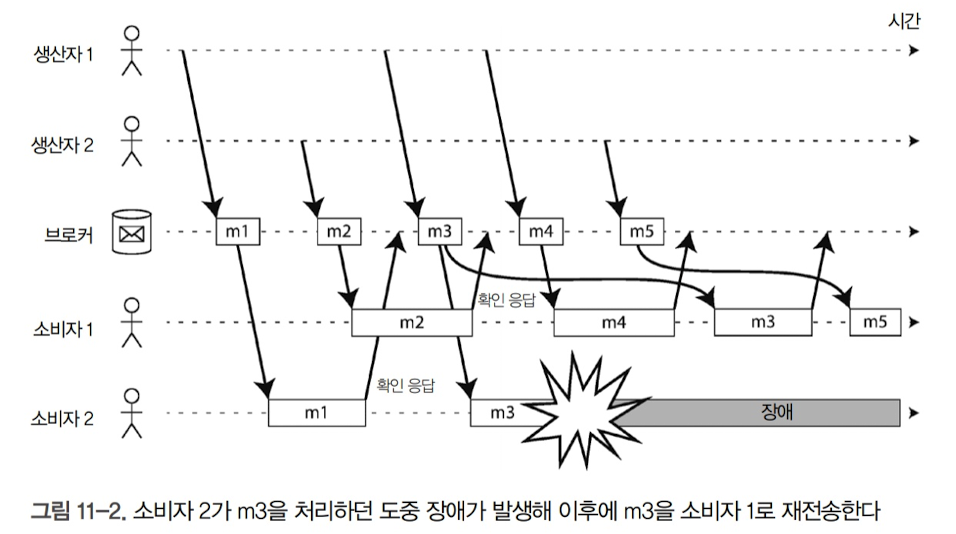
메시지를 잃지 않지 위해 브로커는 확인 응답을 사용함. 클라이언트는 메시지 처리가 끝났을 때 브로커가 메시지를 큐에서 제거할 수 있게 브로커에게 명시적으로 알림
-
브로커는 확인 응답을 받기 전에 클라이언틀의 연결이 닫히거나 타임아웃되면 메시지가 처리되지 않았다고 가정하고 다른 소비자에게 다시 전송함
-
부하 균형 분산과 결합할 때 이런 재전송 행위는 메시지 순서에 영향을 미칠 수 있음
-
위 그림에서 처럼 메시지를 재전송함으로써 m3, m4의 순서가 다르게 전달될 수 있음
-
이러한 문제는 소비자마다 독립된 큐를 사용하면, 즉 부하 균형 분산 기능을 사용하지 않으면 피할 수 있음
-
이 문제에 대해서는 추후에 살펴볼 예정
파티셔닝된 로그
-
메시지 브로커는 메시지를 일시적으로 보관하는 개념으로 만들어 졌기 때문에 메시지를 디스크에 지속성 있게 기록하더라도 메시지가 소비자에게 전달된 후 삭제함
-
데이터베이스와 파일 시스템은 이와는 반대로 모든 데이터는 적어도 누군가 명시적으로 다시 삭제할 때까지 영구적으로 보관된다고 간주함
-
이러한 개념의 차이는 파생 데이터를 생성하는 방식에 큰 영향을 끼침. 일괄 처리의 핵심은 입력이 읽기 전용이기 때문에 입력을 손상하지 않고 반복 수행해 각 처리 단계를 수행할 수 있다는 것임
-
하지만 메시징 처리는 브로커가 확인 응답을 받으면 브로커에서 메시지를 삭제하기 때문에 이미 받은 메시지는 복구할 수 없음. 따라서 소비자를 다시 실행하더라도 동일한 결과를 보장하지 못함
-
데이터베이스의 지속성 있는 저장 방법과 메시징 시스템의 지연 시간이 짧은 알림 기능을 조합할 수 없을까?
- 이러한 관점에서 만들어 진 개념이 로그 기반 메시지 브로커(log-based message broker)임
로그를 사용한 메시지 저장소
-
생산자가 보낸 메시지는 로그 끝에 추가하고 소비자는 로그를 순차적으로 읽어 메시지를 받음
-
소비자가 로그 끝에 도달하면 새 메시지가 추가됐다는 알림을 기다리며 이는 유닉스의 "tail -f"와 동일한 구조를 지니고 있음
-
디스크 하나를 쓸 때보다 처리량을 높기 위해 로그를 파티셔닝하기도 함. 다른 파티션은 다른 장비에서 서비스하며, 토픽은 같은 형식의 메시지를 전달하는 파티션들의 그룹으로 정의함
-
각 파티션 내에서 브로커는 모든 메시지에 오프셋이라고 부르는, 단조 증가 순번을 부여함. 파티션이 추가 전용이고 따라서 파티션 내 전체 메시지는 전체 순서가 있기 때문에 순번을 부여하는 것. 다만, 다른 파티션 간 메시지의 순서를 보장하지는 않음
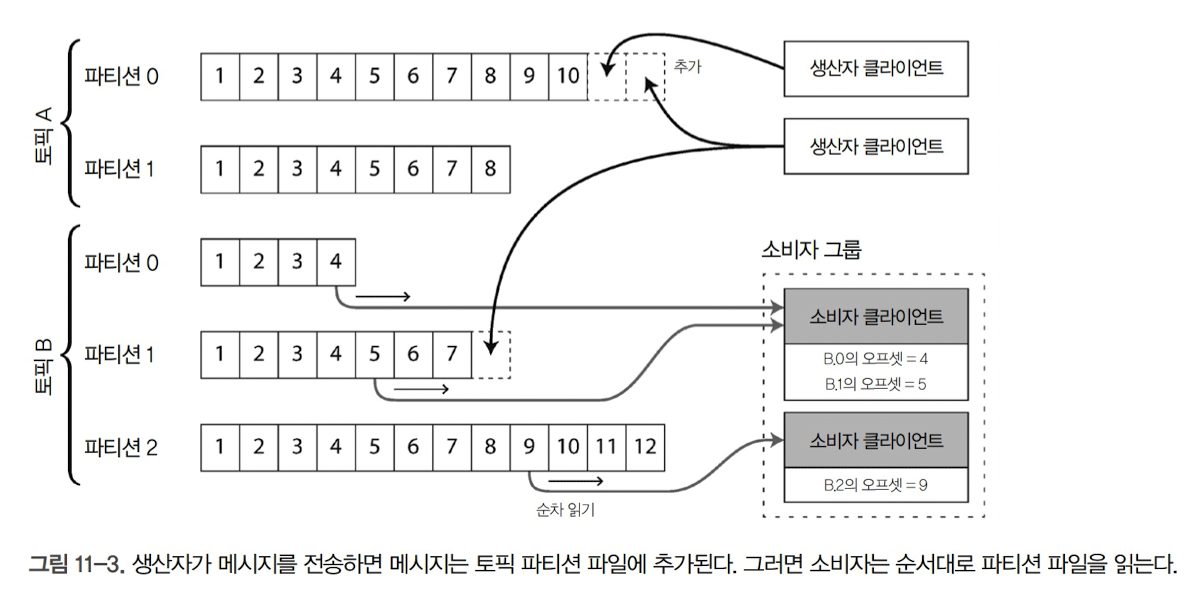
- 아파치 카프카(Apache Kafka), 아마존 키네시스 스트림(Amazon Kinesis Stream) 등이 이런 방식으로 동작하는 로그 기반 메시지 브로커임
로그 방식과 전통적인 메시징 방식의 비교
-
로그 기반 접근법은 팻 아웃 메시징 방식을 제공. 소비자가 서로 영향 없이 독립적으로 로그를 읽을 수 있고 메시지를 읽어도 로그에서 삭제되지 않기 때문임
-
각 클라이언트는 할당된 파티션의 메시지를 모두 소비함. 일반적으로 소비자에게 로그 파티션이 할당되면 소비자는 단일 스레드로 파티션에서 순차적으로 메시지를 읽음. 하지만 이런 방식의 로드 밸런싱은 몇 가지 단점이 존재함
-
토픽 하나를 소비하는 작업을 공유하는 노드 수는 많아야 해당 토픽의 로그 파티션 수로 제한됨. 같은 파티션 내 메시지는 같은 노드로 전달되기 때문
- 이 경우, 파티션 하나에 여러 개의 노드(ex. 짝수 홀수로 구분)할 수도 있지만, 이러한 방법은 오프셋 관리가 복잡해져서 일반적으로 단일 스레드가 처리하는 것이 적절함
-
특정 메시지 처리가 느리면 파티션 내 후속 메시지 처리가 지연됨
-
-
정리하자면 메시지 처리 비용이 비싸고 메시지 단위로 병렬화 처리하고 싶지만 메시지 순서는 그렇게 중요하지 않다면 전통적인 메시징 방식이 적합하고, 반대로 처리량이 많고 메시지를 처리하는 속도가 빠르지만 메시지 순서가 중요하다면 로그 기반 접근법이 효과적임
소비자 오프셋
-
오프셋의 의미는 소비자의 현재 오프셋 보다 작은 메시지는 이미 처리한 메시지고 소비자의 현재 오프셋보다 큰 오프셋을 가진 메시지는 아직 처리하지 않은 메시지라는 의미
-
따라서 브로커는 모든 개별 메시지마다 확인 응답을 추적할 필요가 없으며, 단지 주기적으로 소비자 오프셋을 기록하기만 하면 됨
-
이러한 방식으로 추적 오버헤드를 감소시키며, 로그 기반 시스템의 처리량을 높일 수 있음
-
소비자 노드에 장애가 발생하면 소비자 그룹 내 다른 노드에 장애가 발생한 소비자의 파티션을 할당하고 마지막 기록된 오프셋부터 메시지를 처리하기 시작함
-
이때 장애가 발생한 소비자가 처리는 했지만, 아직 오프셋을 기록하지 못한 메시지가 있다면 이 메시지는 재시작할 때 두 번 처리될 수 있음(이에 관해선 추후에 살펴볼 예정)
디스크 공간 사용
-
로그를 계속 추가하다보면 결국 디스크 공간을 전부 사용하게 될 것
-
디스크 공간을 재사용하기 위해 실제로는 로그를 여러 조각으로 나누고 가끔 오래된 조각을 삭제하거나 보관 저장소로 이동시킴
-
소비자 처리 속도가 느려서 메시지가 생산되는 속도를 따라잡지 못하면 소비자가 너무 뒤쳐져서 소비자 오프셋이 이미 삭제된 조각을 가리킬 수도 있음
-
로그는 크기가 제한된 버퍼로 구현하고 버퍼가 가득 차면 오래된 메시지부터 차례대로 버림. 이런 버퍼를 원형 버퍼(circular buffer) 또는 링 버퍼(ring buffer)라고 함. 하지만, 버퍼가 디스크 상에 있다면 상당히 커질 수 있음
-
간단한 예시로 하드디스크 6TB, 순차 기록 처리량 150MB/s라면, 최대 속도로 메시지를 기록하면 디스크를 가득 채우는 데 약 11시간이 걸림. 즉, 이 하드디스크는 11시간 동안 발생한 메시지를 버퍼링할 수 있다는 의미이며, 그 이후에는 오래된 메시지를 덮어쓰기 시작할 것
-
일반적으로 로그는 하드디스크 버퍼에 수 일에서 수 주간 메시지를 보관할 수 있음
소비자가 생산자를 따라갈 수 없을 때
-
소비자가 생산자를 따라갈 수 없을 때 선택할 수 있는 방법은 크게 세 가지임. 메시지 버리기, 버퍼링, 배압 적용하기
-
로그 기반 접근법은 디스크 공간으로 제한된 고정 크기의 버퍼를 사용하는 버퍼링 형태임
-
따라서 소비자가 로그의 헤드로부터 얼마나 떨어졌는지 모니터링하면서 눈에 띄게 뒤처지는 경우 경고할 수 있음
-
어떤 소비자가 너무 뒤쳐져서 메시지를 잃기 시작해도 해당 소비자만 영향을 받고 다른 소비자들의 서비스는 정상적으로 동작함(전통적인 메시지 브로커에서는 그렇지 않았음)
