합의란?
-
여러 노드들이 뭔가에 동의하게 만드는 것
-
원자적 커밋
- 여러 노드/파티션에 걸친 트랜잭션을 지원하는 데이터베이스에서는 트랜잭션의 원자성을 유지해야하며, 이를 위해서는 모든 노드가 트랜잭션의 결과에 동의하게 만들어야 함
-
리더 선출
- 단일 리더 복제 데이터베이스에서 모든 노드는 어떤 노드가 리더인지 동의해야한다(스플릿 브레인을 피하기 위해)
-
신뢰성 있는 합의?
FLP 결과란 어떤 노드가 죽을 위험성이 있다면 항상 합의에 이를 수 있는 알고리즘은 없다는 것을 증명
하지만, 이러한 증명은 어떤 시계나 타임아웃도 사용할 수 없는 상황을 가정하는 제한된 모델에서 증명됨
즉, 시스템이 타임아웃을 쓰고있거나 죽은 것으로 의심되는 노드를 식별할 수 있다면, 신뢰성있는 합의를 달성할 수 있음
원자적 커밋과 2단계 커밋(2PC)
단일 노드의 원자적 커밋
-
단일 노드 트랜잭션에서 원자성은 저장소 엔진에서 구현
-
커밋 요청이 오면 트랜잭션의 쓰기가 지속성 있게 하고(B트리 구현), 로그에 커밋 레코드를 추가
-
데이터베이스가 죽으면, 트랜잭션은 노드가 재시작될 때 로그로부터 복구됨
분산 노드의 원자적 커밋
-
만일 분산 노드에서 즉, 여러 노드가 트랜잭션에 관여할 때 원자적 커밋은 어떻게 구현될까? 무엇을 고려해야 할까?
-
어떤 노드들은 제약 조건 위반을 감지해서 어보트가 필요하게 하지만 다른 노드들은 성공적으로 커밋될 수 있음
-
어떤 커밋은 네트워크에서 손실되어 타움아웃 때문에 결국 어보트되지만 다른 커밋은 전달될 수 있음
-
어떤 노드는 커밋 레코드가 완전히 쓰여지기 전에 죽어서 복구할 때 롤백되지만 다른 노드는 성공적으로 커밋될 수 있음
-
정리해보자면, 노드는 트랜잭션에 참여하는 다른 모든 노드도 커밋될 것이라고 확신할 때만 커밋되어야 함
-
2단계 커밋(2PC)
- 2단계 커밋은 여러 노드에 걸친 원자적 트랜잭션을 달성하는 알고리즘임
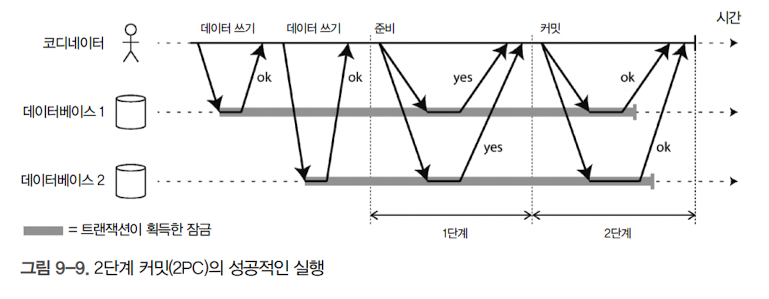
-
위 그림에서와 같이 커밋/어보트 과정이 두 단계로 나뉘기 때문에 2단계 커밋이라는 이름이 붙음
-
2PL과 혼동하지 않도록 주의. 2단계 잠금(2PL)은 직렬성 격리를 제공하기 위한 수단임
-
2PC는 코디네이터를 사용하여 구현됨. 이러한 코디네이터의 예로는 나라야나(Narayana), JOTM, BTM, MSDTC 등이 있음
2단계 커밋의 과정
-
애플리케이션이 커밋할 준비가 되면 코디네이터가 1단계를 시작
-
각 노드에 준비 요청을 보내서 커밋할 수 있는지 물어보고, 코디네이터는 참여자의 응답을 추적
-
모든 참여자에게서 커밋 준비가 완료됐다는 응답을 받으면, 2단계에서 커밋 요청을 보내고 커밋이 실제로 일어남
-
참여자 중 누구에게서라도 커밋이 불가능하다는 응답을 받으면, 2단계에서 모든 노드에 어보트 요청을 보냄
-
약속에 관한 시스템
- 2단계 커밋 과정을 대략적으로 살펴봤지만, 이해하기 쉽지 않음. 좀 더 자세한 과정을 분석해보자
-
애플리케이션은 분산 트랜잭션을 시작할 때 코디네이터에게 트랜잭션 ID를 요청. 이 트랜잭션 ID는 전역적으로 유일함
-
애플리케이션은 각 참여자에서 단일 노드 트랜잭션을 시작하고 단일 노드 트랜잭션에 전역적으로 유일한 트랜잭션 ID를 붙임. 모든 읽기와 쓰기는 이런 단일 노드 트랜잭션 중 하나에서 실행됨. 이 단계에서 뭔가 잘못되면(예를 들어 노드가 죽거나 요청이 타임아웃되면) 코디네이터나 참여자 중 누군가가 어보트할 수 있음
-
애플리케이션이 커밋할 준비가 되면 코디네이터는 모든 참여자에게 전역 트랜잭션 ID로 태깅된 준비 요청을 보내고, 이런 요청 중 실패하거나 타임아웃된 것이 있으면 코디네이터는 모든 참여자에게 그 트랜잭션 ID로 어보트 요청을 보냄
-
참여자가 준비 요청을 받으면 모든 상황에서 분명히 트랜잭션을 커밋할 수 있는지 확인. 여기에는 모든 트랜잭션 데이터를 디스크에 쓰는 것(죽거나 전원 장애나 디스크 공간이 부족한 것은 나중에 커밋을 거부하는 데 용인되는 변명이 아니다)과 충돌이나 제약 조건 위반을 확인하는 게 포함됨. 코디네이터에게 “네”라고 응답함으로써 노드는 요청이 있으면 트랜잭션을 오류 없이 커밋할 것이라고 약속한다. 달리 말하면 참여자들은 트랜잭션을 어보트할 권리를 포기하지만 실제로 커밋하지는 않음
-
코디네이터가 모든 준비 요청에 대해 응답을 받았을 때 트랜잭션을 커밋할 것인지 어보트할 것인지 최종적으로 결정. 이때 코디네이터는 추후 죽는 경우에 어떻게 결정했는지 알 수 있도록 그 결정을 디스크에 있는 트랜잭션 로그에 기록. 이를 커밋 포인트라고 함
-
코디네이터의 결정이 디스크에 쓰여지면 모든 참여자에게 커밋이나 어보트 요청이 전송됨. 요청이 실패하거나 타임아웃이 되면 코디네이터는 성공할 때까지 영원히 재시도함. 도중에 한 참여자가 죽었다면 트랜잭션은 그 참여자가 복구될 때 커밋됨
정리해보자면, 2단계 커밋에는 "돌아갈 수 없는 지점"이 존재함
1. 참여자가 커밋할 수 있다고 응답
2. 코디네이터가 커밋을 결정
이러한 제약이 2단계 커밋이 원자성을 보장할 수 있도록 함
코디네이터 장애
-
2단계 커밋 중 노드 하나에 네트워크 장애가 발생하면, 코디네이터는 트랜잭션을 어보트 함
-
만일, 코디네이터 장애가 준비 요청을 보내기 전에 발생했다면, 참여자들은 트랜잭션을 어보트하기만 하면 됨
-
하지만, 투표가 종료된 이후 코디네이터에 장애가 발생했다면, 각 참여자들은 코디네이터로부터 트랜잭션이 커밋됐는지, 어보트됐는지 회신 받을 때까지 기다릴 수밖에 없음
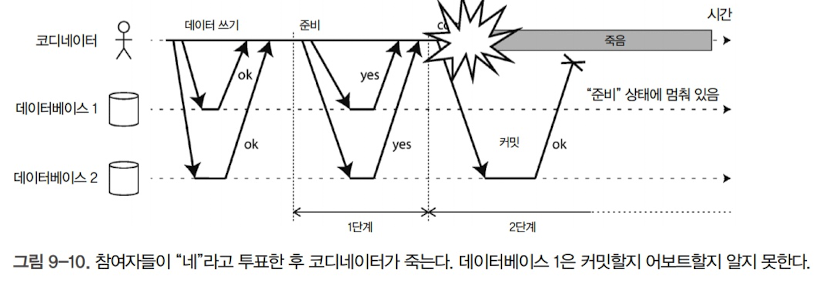
-
이때는 타임아웃도 도움이 되지 않음. 만일, 데이터베이스1이 타임아웃 이후, 일방적으로 어보트하면 커밋한 데이터베이스2와 일관적이지 않게 됨. 반대로 또 다른 참여자가 어보트했을지도 모르는 트랜잭션을 커밋하는 것도 안전하지 않음
-
2PC가 완료될 수 있는 유일한 방법은 코디네이터가 복구되기를 기다리는 것 뿐임. 코디네이터는 참여자들에게 커밋이나 어보트 요청을 보내기 전에 디스크에 있는 트랜잭션 로그에 자신의 커밋이나 어보트 결정을 쓰기 때문에, 코디네이터가 복구된다면 트랜잭션이 이어서 진행됨
3단계 커밋
-
2단계 커밋은 코디네이터가 복구하기를 기다리느라 멈출 수 있다는 것 때문에 블로킹 원자적 커밋 프로토콜이라고 부름
-
이론적으로는 이러한 원자적 커밋을 논블로킹하게 만들 수 있음
-
일반적으로 논블로킹 원자적 커밋을 구현하기 위해선 완벽한 장애 탐지가 필요함 즉 노드가 죽었는지 아닌지 구별할 수 있는 신뢰성 있는 메커니즘이 필요함
-
하지만 기약 없는 지연이 존재하는 네트워크 환경에서 타임아웃은 신뢰성 있는 장애 감지기가 아니며, 이런 까닭으로 여전히 2PC가 주로 쓰이고 있음
