신뢰성 없는 시계
-
분산 시스템에서는 통신이 즉각적이지 않으므로 시간은 다루기 까다로움
-
메시지를 받은 시간은 항상 보낸 시간보다 나중이지만 네트워크의 지연의 변동성 때문에 얼마나 나중일지는 알 수 없음
-
게다가 네트워크에 있는 개별 장비는 자신의 시계를 갖고 있어 다른 장비보다 약간 빠를 수도 느릴 수도 있음
-
흔히 NTP(Network Time Protocol)을 사용해 각 노드에서 시계를 조정함
일 기준 시계와 단조 시계
-
일 기준 시계
-
직관적으로 시계에 기대하는 시계
-
일 기준 시계는 보통 NTP로 동기화됨
-
로컬 시계가 NTP 서버보다 너무 앞서면 강제로 리셋되어 과거 시점으로 거꾸로 뛰는 것처럼 보일 수 있음
-
한 장비의 타임스탬프는 (이상적으로) 다른 장비의 타임스탬프와 동일한 의미를 지닌다는 뜻
-
-
단조 시계
-
타임아웃이나 서비스 응답 시간 같은 지속 시간(시간 구간)을 재는 데 적합
-
단조 시계란 이름은 항상 앞으로 흐른다는 사실에서 나옴(반면 일 기준 시계는 시간이 거꾸로 뛸 수도 있다)
-
한 시점에서 단조 시계의 값을 확인하고 어떤 일을 한 후 나중에 다시 시계를 확인할 때 쓰임
-
즉, 두 값 사이의 차이로 인한 시간의 흐름을 측정하며, 시계의 절대적인 값 자체는 의미가 없음
-
-
NTP는 컴퓨터의 로컬 시계가 NTP 서버보다 빠르거나 느리다는 것을 발견하면 단조 시계가 진행하는 진도수를 조정할 수 있음
-
분산 시스템에서 경과 시간을 재는 데 단조 시계를 쓰는 것은 일반적으로 괜찮음. 다른 노드의 시계 사이에 동기화가 돼야 한다는 가정이 없고 측정이 약간 부정확해도 민감하지 않기 때문
동기화된 시계
-
네트워크와 마찬가지로 시계는 대부분의 시간에 아주 잘 동작하지만 견고한 소프트웨어는 잘못된 시계에 대비할 필요가 있음
-
하지만, 시계가 잘못되었다는 것을 눈치채는 것은 쉬운 일이 아님. 다른 모든 장비 사이의 시계 차이를 모니터링하는 방식으로, 다른 노드와 시계가 너무 차이나는 경우 죽은 것으로 간주하고 클러스터에서 제거할 수 있음
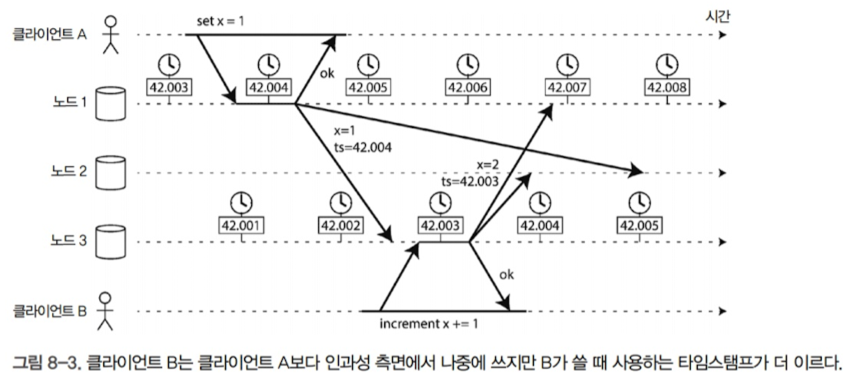
-
시계의 시간 차이로 인해 발생할 수 있는 문제는 다양함. 위 예시도 그 중 하나
-
데이터베이스 쓰기가 불가사의하게 사라질 수 있음. 시계가 뒤처지는 노드는 시계가 빠른 노드가 먼저 쓴 내용을 그들 사이에 차이나는 시간이 흐를 때까지 덮어쓸 수 없음
-
LWW는 순차적인 쓰기가 빠른 시간 내에 연속으로 실행되는 것 진짜 동시에 쓰기가 실행되는 것을 구별할 수 없음
-
두 노드가 독립적으로 동일한 타임스탬프를 가진 쓰기 작업을 만들 수도 있음
-
-
잘못된 순서화가 발생하지 않을 정도로 NTP 동기화를 정확하게 할 수 있을까?
-
NTP 동기화 정확도 자체가 네트워크 왕복 시간에 따라 제한되기 때문에 이는 불가능에 가까움
-
논리적 시계(logical clock) 는 일 기준 시간이나 경과한 초 수를 측정하지 않고 이벤트의 상대적인 순서만 측정하는 방식으로 이 문제를 해결하려고 함(추후에 살펴봄)
-
전역 스냅숏용 동기화된 시계
-
스냅숏 격리 구현은 단조 증가하는 트랜잭션 ID에 의존한다는 것을 살펴봤음
-
다만, 분산 데이터베이스에서는 코디네이션이 필요함. 모든 파티션에 걸쳐서 전역 단조 증가하는 트랜잭션 ID를 생성하기가 어렵기 때문
-
트랜잭션 ID는 인과성을 반영해야함(즉, 나중의 트랜잭션 ID가 이전의 트랜잭션 ID보다 커야함)
-
동기화된 일 기준 시계의 타임스탬프를 트랜잭션 ID로 쓸 수는 없을까?
-
스패너는 구글의 트루타임 API를 활용해 이러한 스냅숏 격리를 구현함
-
트루타임은 시간의 신뢰구간을 표시하며, 각 가장 이른 타임스탬프와 가장 늦은 타임스탬프를 포함하는 두 개의 신뢰 구간이 있고(A = [Aearliest, Alatest]와 B = [Bearliest, Blatest])라는 두 구간이 겹치지 않는다면(즉 Aearliest < Alatest < Bearliest < Blatest) B는 분명히 A보다 나중에 실행됐다고 판단하며, 트랜잭션 타임스탬프가 인과성을 반영하는 것을 보장하기 위해 스패너는 읽기 쓰기 트랜잭션을 커밋하기 전에 의도적으로 신뢰 구간의 길이만큼 기다림
-
하지만 이와 같은 방식은 주류 데이터베이스에서는 아직 구현되지 않음
프로세스 중단
-
동기화된 시계에 의존하는 프로세스는 문제가 있음
-
단조 시계만을 사용한다 하더라도, 다양한 이유로 스레드가 오랫동안 멈출 수 있기 때문임
-
JAVA GC과정의 Stop-the-world, 애플리케이션이 느린 디스크 I/O를 기다리느라 중단되는 등 다양한 원인이 존재
-
단일 장비에서는 뮤텍스(mutex), 세마포어(semaphore), 원자적 카운터(atomic counter), 잠금 없는(lock-free) 자료구조, 블로킹 큐(blocking queue) 등으로 스레드 안전하게 만들 수 있지만, 이런 도구들은 분산 시스템용은 아님
응답 시간 보장
-
소프트웨어가 응답해야 하는 데드라인(deadline)을 명시하는 방식의 엄격한 실시간 시스템을 사용할 수 있음
-
이러한 방식은 자동차의 에어백처럼 임베디드 시스템에서 주로 사용되며, 실시간 운영체제(realtime operating system, RTOS)가 필요함
-
이 경우 비용이 많이 들며, 실시간은 고성능을 의미하지 않음(자동차 에어백은 고성능을 충족하지 않아도 됨)
-
따라서 일반적인 애플리케이션의 데이터 처리 시스템에게 실시간 보장은 적절하지 않음
가비지 컬렉션 영향 제한하기
-
GC 중단은 프로세스 중단과 어느정도 관련됨
-
최근의 아이디어 중 하나는 GC 중단을 노드가 계획적으로 중단되는 것으로 간주하고, GC가 일어나는 동안에 클라이언트로부터의 요청을 다른 노드들이 처리하도록 하는 방식도 존재함
-
지연 시간에 민감한 금융 거래 시스템 중 이 방법을 쓰는 곳이 존재하지만 대중화되지는 않았음
