단일 리더 기반 복제의 단점
-
리더가 하나만 존재하고 모든 쓰기를 해당 리더가 처리해야 함
-
어떤 이유로든 리더에 연결할 수 없다면, 데이터베이스에 쓰기를 할 수 없음
-
그래서 등장한 것이 다중 리더 복제
-
단일 리더 복제와 동일한 방식을 사용하지만, 쓰기 처리를 하는 다중 리더는 데이터 변경을 다른 모든 노드에 전달하며 싱크를 맞춤
-
마스터 마스터 / 액티브 액티브 구조라고 부름
사용 사례
-
단일 데이터센터에서는 다중 리더 설정 사용으로 인한 복잡도에 비해 이점이 크지 않음
-
다중 데이터센터 운영 관점에서는 각 데이터 센터마다 리더를 두어 쓰기 오버헤드(멀리 있는 데이터 센터에 쓰기 요청) 등을 줄일 수 있으며, 데이터센터 장애시에도 대처가 가능해짐
-
MySQL의 텅스텐 리스리케이터, postgresql의 BDR, Oracle의 골든게이트가 이와 같은 다중 리러 복제 방식을 사용
-
오프라인 작업을 하는 클라이언트 즉, 인터넷 연결이 끊어진 동안에도 애플리케이션이 계속 동작해야하는 경우에도 적합함.
- 이 경우, 오프라인 상태에서 데이터를 변경하면 디바이스가 데이터를 저장해두었다가, 온라인 상태가 됐을 때 서버와 디바이스를 동기화함(ex. 구글 독스)
- 아키텍처 관점에서 보면 이러한 설정은 근본적으로 데이터센터 간 다중 리더 복제와 동일
쓰기 충돌
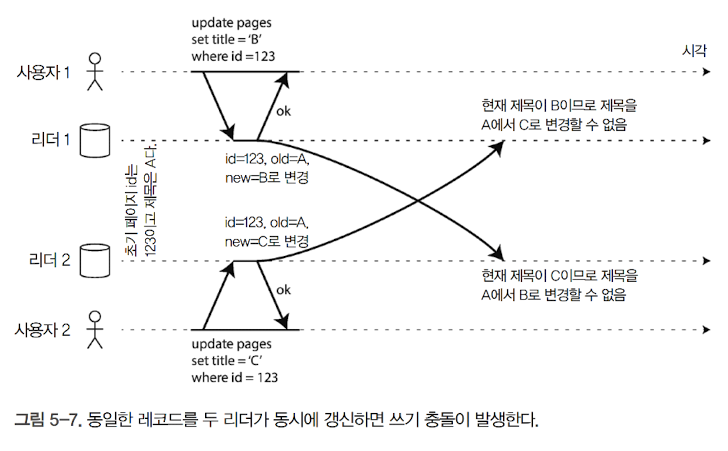
-
다중 리더 복제의 가장 큰 문제는 쓰기 충돌이 발생한다는 것
-
동시에 같은 변경을 적용하려고 할 때 문제가 될 수 있음(위 그림 참고)
-
충돌 감지(동기 대 비동기)
-
단일 리더 데이터베이스에서는 첫 번째 쓰기가 완료될 때까지 두 번째 쓰기를 차단해 기다리게 하거나 두 번째 쓰기 트랜잭션을 중단해 사용자가 쓰기를 재시도하게 할 수 있음
-
반면, 다중 리더 데이터베이스에서는 두 쓰기를 모두 성공처리하며 충돌은 이후 특정 시점에서 비동기로만 감지하게 함
-
이론적으로 충돌 감지를 동기식으로 구현할 수 있겠지만, 그렇다면 다중 리더 복제의 주요 장점인 "각 복제 서버가 독립적으로 쓰기를 허용"하는 것을 잃음
-
-
충돌 회피
-
충돌을 가장 잘 처리하는 방법은 충돌을 피하는 것
-
즉, 특정 레코드의 모든 쓰기가 동일한 리더를 거치도록 애플리케이션이 보장하도록 하는 것
-
예를 들어 특정 사용자의 요청이 항상 같은 데이터센터로 라우팅될 수 있도록 보장하는 것
-
-
일관된 상태 수렴
-
단일 리더 데이터베이스는 순차적인 순서로 쓰기를 적용해 일관된 상태를 지님
-
다중 리더 데이터베이스는 쓰기 순서가 정해지지 않아 최종 값이 무엇인지 명확하지 않음
-
수렴 충돌 해소 방법
-
각 쓰기에 고유 ID(UUID)를 부여하고 가장 높은 ID가 승자가 되어 쓰기로 선택 → 이 방식은 대중적이지만 데이터 유실 위험이 존재
-
각 복제 서버에 고유 ID를 부여하고 높은 숫자의 복제 서버에서 생긴 쓰기가 항상 우선적으로 적용 → 역시 데이터 유실 위험이 존재
-
어떻게든 값을 병합. 예를 들어 사전 순으로 정렬한 후 연결
-
명시적 데이터 구조에 충돌을 기록해 모든 정보를 보존 → 추후 애플리케이션에서 충돌을 해소
-
-
사용자 정의 충돌 해소 로직
-
일반적으로 다중 리더 복제 데이터베이스는 애플리케이션 코드를 사용해 충돌 해소 로직을 작성
-
쓰기 수행 중
- 복제된 변경 로그에서 데이터베이스 시스템이 충돌을 감지하면 충돌 핸들러를 호출
-
읽기 수행 중
- 충돌을 감지하면 모든 충돌 쓰기를 저장하며, 다음 번 데이터를 읽을 때 여러 버전의 데이터가 애플리케이션으로 반환. 이때 애플리케이션이 충돌을 해소
-
충돌 해소에 대한 자세한 내용은 7, 12장에서 다룰 예정
다중 리더 복제 토폴리지

-
복제 토폴로지는 쓰기를 한 노드에서 다른 노드로 전달하는 통신 경로를 설명
-
전체 연결(all-to-all) : 가장 일반적이며, 그림의 (c)
-
원형(circular) : 각 노드가 하나의 노드로 쓰기를 받고, 쓰기를 다른 노드에 전달(MySQL에서 사용)
-
별 모양(star) : 가장 대중적인 방식, 지정된 루트 노드 하나가 다른 모든 노드에 쓰기를 전달. 트리로 일반화 할 수 있음
-
원형과 별 모양에서는 무한 복제가 일어날 수 있기 때문에 모든 노드는 고유 식별자를 태깅하며, 한 노드가 데이터 변경 사항을 받았을 때 자신의 식별자가 태깅되어 있다면 변경 사항을 무시하는 방식으로 작동
-
원형과 별 모양 토폴리지는 하나의 노드가 장애가 발생하면, 다른 노드 간 복제 흐름에 방해를 줄 수 있음 즉, SPOF가 발생할 수 있으며 이는 수동으로 처리해야 함(전체 연결에서는 발생하지 않는 문제)

- 반면 전체 연결에서는 일부 네트워크 연결이 다른 네트워크보다 빠르다면(네트워크 혼잡으로 인해) 일부 복제 메시지가 다른 메시지를 추월할 수 있음 → 이 메시지에 종속성이 존재한다면?
-
이러한 이벤트를 올바르게 정렬하기 위해 버전 벡터(version vector)라는 기법을 사용할 수 있음(추후 설명)
-
하지만 많은 다중 리더 복제 시스템에서 충돌 감지 기법이 제대로 구현되지 않음 ( postgresql의 BDR은 쓰기의 인과적 순서를 제공하지 않으며 MySQL의 텅스텐 리플리케이터는 충돌 감지를 위한 시도조차 하지 않음)
