Zookeeper란?
-
분산 애플리케이션을 위한 분산 코디네이션 서비스
-
분산 애플리케이션을 위한 동기화, 설정, 그룹, 네이밍에 대한 추상화된 수준의 서비스를 제공
-
이를 API로 제공해 사용하기 쉽고, 데이터 모델도 디렉토리 구조를 이용하고 있어 이해하기 쉽다는 장점
-
분산 시스템에 있어서 코디네이션 기능은 매우 중요하지만, Lock, Race condition, Deadlock 등의 이유로 구현하기 까다로움. Zookeeper를 이용하면 코디네이션은 주키퍼에게 맡기는 형태로 쉽게 구현이 가능
Zookeeper의 주요 기능과 특징
-
ZNodes
-
파일 시스템과 유사한 shared hierarchical namespace를 통해 분산 프로세스가 상호작용할 수 있게 함
-
네임스페이스는 zookeeper용어로 데이터 레지스터로 구성. 저장용으로 설계된 파일시스템과 달리 데이터가 메모리에서 처리되기 때문에(파일형태로 저장해서 휘발되지는 않음), High throughput과 low latency를 제공
-
-
비기능적 특징
-
Zookeeper의 요구사항
-
High Performance
- Zookeeper의 성능은 대규모 분산 시스템(수천대 규모)에서도 사용할 수 있는 수준
-
High Available
- Reliability는 SPOF가 발생하지 않도록 설계
-
Strictly Ordered Access
- 클라이언트에서 정교한 동기화 기능을 구현할 수 있음
-
-
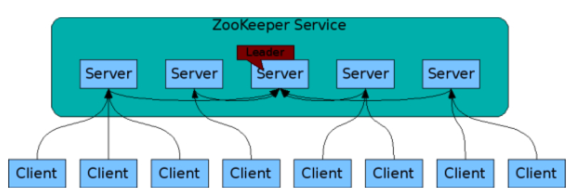
복제된 구성요소
-
Zookeeper는 ensemble(앙상블)이라는 호스트 집합을 통해서 복제
-
Persistent store(disk)에 트랜잭션 로그, 스냅샷, 메노리 내 상태 이미지를 유지
-
Cluster를 구성하는 서버들 중 과반수(Quorum)이상이 유지된다면, 일부 장애나 문제가 있어서 전체 Zookeeper 서비스는 유지됨(홀수로 구성하며(과반수), 최소 설치 대수는 3대)
-
클라이언트는 Zookeeper 연결에 대해 다음 기능을 수행할 수 있음
-
request
-
response
-
watch event
-
heartbeat
-
-
클라인언트는 연결된 서버(Zookeeper)에 대한 TCP 연결이 끊어지면, Cluster 내의 다른 서버에 연결함
-
-
Ordered
- Zookeeper는 모든 transaction에 대한 순서를 보장. 이 순서를 사용하여 synchronization primitives와 같은 더 높은 수준의 추상화를 구현할 수 있음
-
Performace
- Zookeeper는 read 위주의 워크로드에 적합. 수천 대의 서버에서 하나의 주키퍼 클러스터를 이용하려면 read 위주의 작업이고 그 데이터의 양이 많지 않을 때(memory를 사용하기 때문) 가능함. Zookeeper에서 감당 가능한 적정한 read:write 비율은 10:1 이하
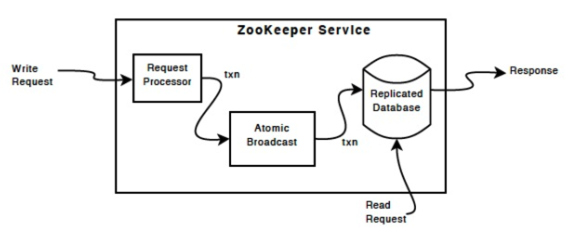
Zookeeper의 요청 처리
-
Replication & read
-
Request Processor를 제외하면 Zookeeper 서비스를 구성하는 각 서버는 각 구성요소의 자체 복사본을 복제함
-
복제된 데이터베이스는 전체 데이터 트리를 포함하는 in-memory 데이터베이스임. update는 복구를 위해 디스크에 기록되고, 쓰기는 메모리 내 데이터베이스에 적용되기 전 디스크에 serialization됨
-
-
Contract Protocol
-
모든 Zookeeper 서버는 클라이언트에 서비스를 제공
-
클라이언트는 cluster 중 하나의 서버에 연결을 요청
-
read request는 각 서버 데이터베이스의 로컬 복제본에서 처리
-
서비스 상태를 변경하는 write 요청은 contract protocol에 의해 처리됨
-
Zookeeper 클러스터의 서버는 역할에 따라 leader와 follower로 나뉨
-
leader : 데이터의 수정 권한을 가진 노드
- write operation이 수행
-
follower : leader가 아닌 노드
- write 요청은 leader에게 전달(read > write가 되어야 하는 이유)
- leader에게 메시지를 받고 전달
-
-
Messaging Layer
-
Messaging Layer는 실패 시 리더를 교체하고 팔로워를 리더와 동기화하는 작업을 담당
-
메시지 계층은 atomic(원장성 보장)하기 때문에 Zookeeper는 로컬 복제본이 절대 분기되지 않도록 보장(Split-brain 장지)
-
리더는 write 요청을 수신하면 변경이 적용될 때 시스템 상태를 계산하고 이를 새로운 상태를 캡처하는 트랜잭션으로 변환
-
Zookeeper Quorum
-
Quorum이란
-
Quorum은 주키퍼 클러스터의 앙상블을 이루고 있는 모든 서버 중 과반수 서버로 이루어진 그룹을 의미
-
Quorum을 이루는 노드들은 반드시 running 상태여야 하며, 클라이언트 요청을 처리하는 최소한의 서버 노드로 구성되어야 함
-
주키퍼에서 데이터 변경(write)가 성공했다면, Quorum을 구성하는 노드들은 변경 트랜잭션이 반영된 상태를 유지
-
Zookeeper 상세 기능
-
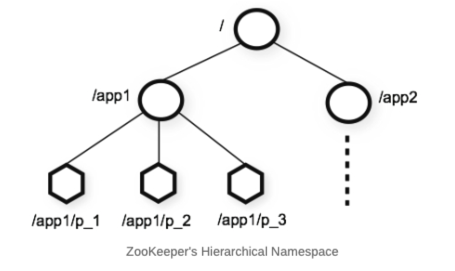
Namespace Structure
- Zookeeper가 제공하는 네임스페이스는 파일 시스템의 형식과 유사. 이름은 "/"로 구분된 경로를 표시. 모든 znode(데이터)는 경로로 식별됨
-
파일 시스템과의 차이점은 Zookeeper Namespace의 각 노드(znode)는 하위 노드뿐만 아니라 해당 노드와 연결된 데이터를 가질 수 있음. 쉽게 말해 파일 자신이 디렉토리가 될 수 있는 파일시스템으로 이해하면 쉬움
-
하나의 znode의 크기는 수 bytes ~ 수 KB 이하로 유지하는 것을 권장
-
주로 설정 정보나 적은 수의 metadata 등의 빠른 동기화 용도 위주로 사용됨
-
Versioning
- Znode는 캐시 유효성 검사, coordinated update를 위한 version number를 가짐
- Data 변경
- ACL 변경
- Client가 znode 데이터를 받을 때 이 버전 정보도 항상 같이 전달됨
- Znode는 캐시 유효성 검사, coordinated update를 위한 version number를 가짐
-
Atomic Operation
-
Namespace의 각 znode에 저장된 데이터는 automic read/write operation을 수행.
-
read는 znode와 연결된 모든 데이터를 가져오고, write는 모든 데이터를 덮어씀
-
각 znode에는 수행할 수 있는 작업을 제한하는 ACL(엑세스 제어 목록)이 존재
-
-
Ephemeral nodes
- 일시적 노드의 개념. Ephemeral node는 znode를 생성한 세션이 활성화되어 있는 동안만 존재
-
Conditional Update & Watch
-
Client가 특정 znode에 watch 설정하면, 해당 znode(child 포함)에 업데이트가 발생하면 watch가 trigger되고, client의 watch가 해제됨
-
Client API로 watch에 대한 callback 함수를 등록해서 원하는 operation을 수행할 수 있음
-
3.6.0 version부터는 trigger 이후에도 watch가 유지되도록 할 수 있음
-
