하둡의 등장 배경
-
정형 데이터는 기존의 RDBMS에 저장하지만, 웹 로그 등의 비정형 데이터를 RDBMS에 저장하기에는 데이터의 크기가 너무 크고, RDBMS의 복잡한 기능이 필요하지도 않음
-
RDBMS는 보통 대용량, 고스펙의 장비에 운용하는데, 자주 사용하지 않는 데이터를 무작정 RDBMS에 보관하기에는 비용 문제가 발생
-
하둡은 값비싼 장비대신 x86 리눅스 서버라면 어떤 수준의 장비든지 운용이 가능. 데이터 용량이 커지면 단순히 노드를 늘려서 대응할 수 있다는 점이 큰 장점
-
또한, 하둡은 데이터의 복제본을 저장하기 때문에 유실이나 장애에도 데이터를 복구할 수 있음
-
데이터가 여러 노드에 분산 저장되어 있기 때문에, 프로세싱 또한 분한 서버에서 동시에 처리할 수 있음(동시성 구현에 비해 훨씬 쉬움)
하둡의 특징
- 고수준(High-Level)에서의 주요 특징은 다음과 같다
- 확장성 : 확장시 Sacle-Out으로 확장(노드 추가)
- 경제성 : 저렴한 노드에서 분산 처리
- 효율성 : 분산처리 가능
- 신뢰성 : 데이터 복제본 저장으로 인한 신뢰성 확보
하둡 아키텍처
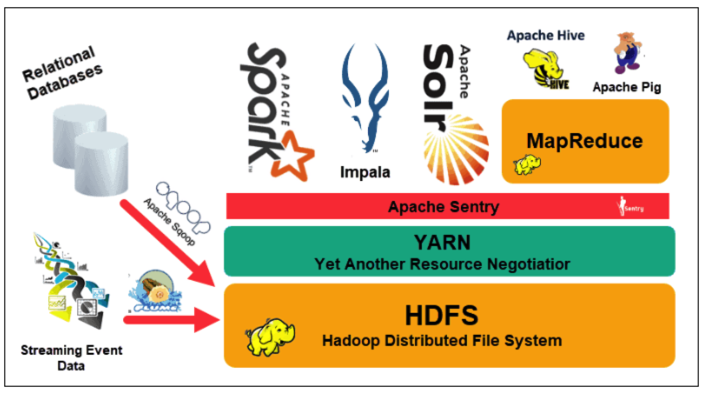
source : https://phoenixnap.com/kb/apache-hadoop-architecture-explained
-
노드와 파일시스템은 HDFS를 근간으로 하고, 그 이외의 작업은 Yarn이라는 Resource Management 프레임워크를 이용해서 유연하게 분산 처리작업을 작성하고 활용함
-
Yarn은 Mapreduce뿐만 아니라, Tez, Flink, Spark 등 분산 처리를 위한 프레임워크나 도구들이 HDFS와 HDFS가 설치된 컴퓨팅 자원을 더 쉽게 이용할 수 있게 해주는 역할
