Workflow Scheduler의 필요성
-
ETL Model의 한계
-
ETL은 Batch에서 주로 사용되는 파이프라인을 추상화한 모델
-
하지만 sequential한 작업에서만 적용 가능함(복잡한 DAG에서 사용하기 어려움)
-
하나의 작업이 하나의 머신에서만 동작하므로 물리적인 스케일의 한계가 존재(Spring Batch 등)
-
-
Workflow Use-case
-
데이터 분석작업을 위해 event와 metadata를 조인해서 활용하는 경우
-
1시간 단위 배치작업이지만, event 저장소와 metadata의 저장소가 다를 경우
-
metadata의 dump는 1시간 내로 완료되지만, 이벤트데이터의 저장소는 데이터가 확정되는 시간이 불명확한 경우
-
이벤트 데이터가 2배 이상 폭증할 가능성으로 데이터가 확정되는 시간이 불분명한 경우
-
이러한 use-case를 기존 JAVA기반 ETL로 처리해야한다면, 신경쓸 것이 너무 많아져서 개발생산성이 떨어짐
-
Airflow란
-
Airflow의 주요 기능
-
Python 기반의 workflow scheduler
-
Task를 DAG(Directed Acyclic Graph)형식으로 구성
-
Scheduling 방식과 trigger 조건(a가 끝나면 b task 실행)을 정적 조건 뿐만 아니라 동적인 조건으로 설정 가능
-
스케줄러와 worker가 나누어져 있고, worker는 확장 가능해서 수많은 workflow를 실행하고 관리
-
python file로 workflow를 구성
-
Web UI 관리 툴을 활용해 쉽게 시각화하거나 디버깅 할 수 있음
-
-
Airflow의 장점
-
Python에서 오는 장점 : dynamic pipeline 구성 가능, VCS를 이용한 버전 관리, 여러 사람이 동시에 개발 가능, jinja template으로 parameterize 가능
-
Operator로 반복작업을 줄이며 다양한 기술스택과 연결 가능
-
인프라를 동적으로 늘리거나 줄일 수 있음(worker)
-
-
Airflow의 한계
-
Airflow는 기본적으로 scheduling 기반의 batch용 workflow 도구
-
streaming, 무한 반복되는 작업, 외부 요소에 의해 trigger되는 scheduling 등은 하지 못함
-
지연을 허락하지 않은 스케줄링은 적합하지 않음(python언어에서 오는 특징)
-
airflow worker내에서 고부하 작업의 처리(단일 노드에서 처리하면 안됨, hive, spark 등에 job을 summit하는 용도로 사용해야 함)
-
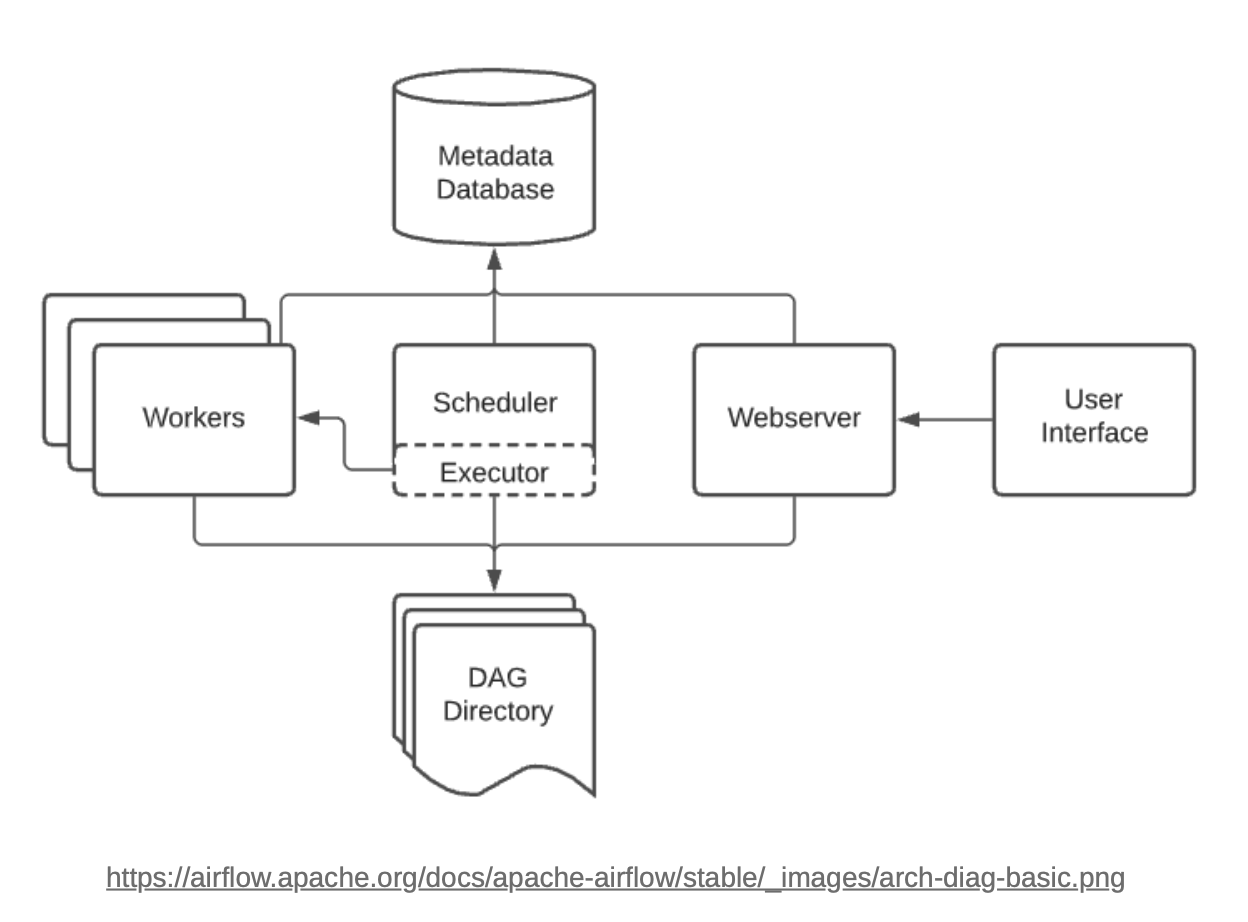
Airflow Architecture
-
Scheduler
-
Schedule된 workflow를 trigger하고 task를 excutor에게 실행하도록 제출
-
모든 task와 DAG를 모니터링하고(defualt:1m) 각 task instance를 조건에 맞게 trigger함.
-
-
Executor
-
Task의 실행을 관리. 실제 task의 실행은 스케줄러 내부에서 수행할 수도, 외부의 worker에게 실행을 맡길 수도 있음
-
선택가능한 Execuotr의 종류는 다양하지만, 보통 Celery Executor나 Kubernetes Executor를 가장 많이 선택함
-
-
Webserver
- 유저가 DAG나 task의 상태를 관리하는 Web interface 도구. 공통 설정을 관리하거나 매뉴얼한 작업의 수정, 디버깅이 가능함
-
DAG Directory
- workflow가 정의된 DAG의 Python 파일은 스케줄러와 executor가 읽을 수 있는 dags 경로에 존재해야 함
-
Metadata Database
-
작업의 정의, 상태, 실행 정보, 결과정보, 로그, audit 등을 관리
-
Schedule, Executor, Webserver 모두 metadata database를 바라봄
-
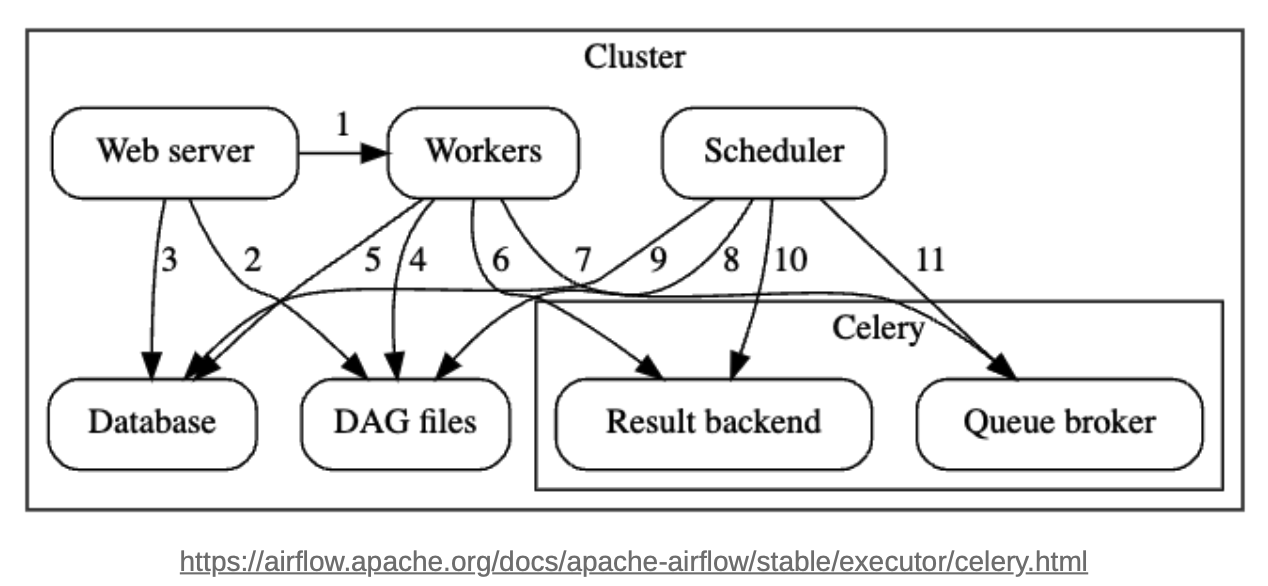
Celery Executor Architecture
-
Components
-
Workers
-
Scheduler
-
Web server
-
Database
-
Celery - 스케줄링하는 Queue의 사용 방식
-
-
Celery Components
-
Broker : 실행해야할 command를 저장
-
Result backend : 완료된 commanddml 상태를 저장
-
Flower : Celery Queue 및 작업 상태를 모니터링하는 Web-UI
-
-
Communications
-
Web-server → Workers, DAG files, Database
- task 실행 로그
- DAG 구조
- task 상태를 가져옴
-
Workers → DAG files, Database, Celery Result backend, Celery brokers
- DAG구조와 실행할 tasks정보 확인
- connection와 configuration과 variablesdhk XCOM 등의 정보를 가져오거나 저장
- tasks의 상태 저장
- 실행하야할 command를 가져옴(subscribe)
-
Scheduler → DAG files, Database
- DAG 구조와 실행해야할 tasks 정보 확인
- DAG run과 관련된 tasks 정보 저장
-
Scheduler → Celery Result backend, Celery broker
-
완료된 task의 상태 정보를 가져옴
-
실행해야할 command 저장
-
-
-
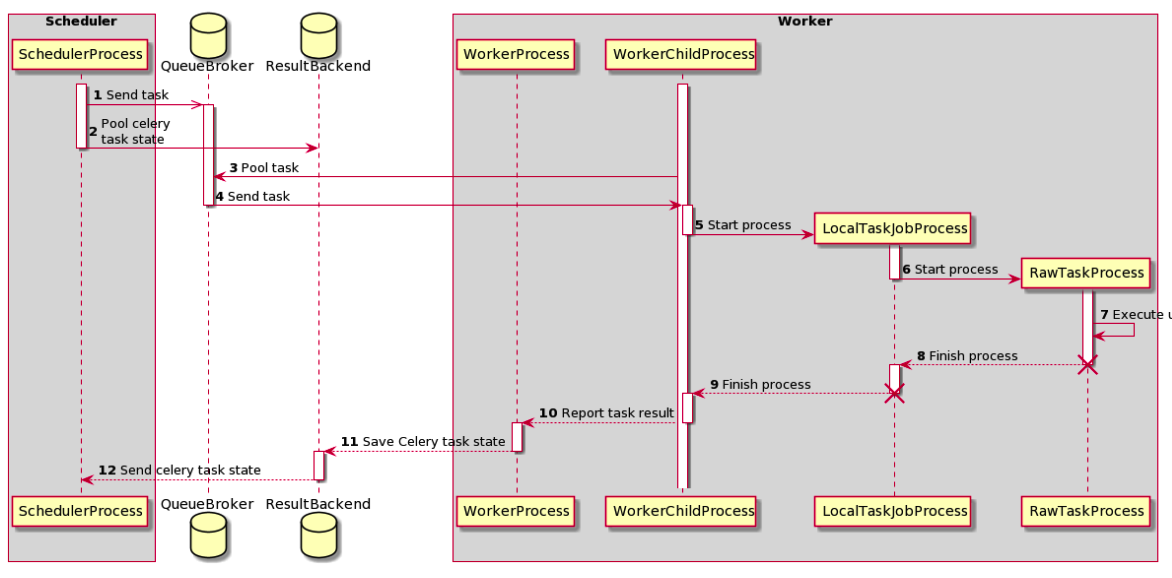
Tasks execution process