
데이터소스에서 정보를 검색하고 표시할 때 온 디맨더 방식을 사용하는 것이 일반적
ex) 뉴스 리더에서 사용자가 처음 앱을 열 때 일부 기사만 가져오고 아래로 스크롤할 때 데이터를 더 가져온다.
5장에서 다루는 주제
- 일시 중단 가능한 시퀀스(Suspendable sequence)
- 일시 중단 가능한 이터레이터(Suspendable iterator)
- 일시 중단 가능한 데이터 소스에서 데이터 산출
- 시퀀스와 이터레이터의 차이점
- 프로듀서(producer)를 사용한 비동기 데이터 검색
- 프로듀서의 실제 사례
일시 중단 가능한 시퀀스 및 이터레이터
지금까지 하나 또는 그 이상의 연산이 실행되기를 대기하는 동안 일시 중단하는 함수만을 알아보고 구현했음

- 일시 중단 가능한 시퀀스/이터레이터의 중요한 특성
-
호출 사이에서 일시 중단되지만, 실행 중에는 일시 중단될 수 없음
-> 일시 중단 연산이 없어도 반복할 수 있음 -
시퀀스와 이터레이터의 빌더는 CoroutineContext를 받지 않음
기본적으로 코드를 호출한 컨텍스트와 동일한 컨텍스트에서 코드가 실행됨을 의미
CoroutineContext :
Coroutine이 실행되는 환경이라고 생각하면 된다.
Dispatcher와 CoroutineExceptuonHandler 또한 Coroutine이 실행되는 환경의 일부이며,
이 둘 모두는 CoroutineContext에 포함되어 Coroutine이 실행되는 환경으로 볼 수 있다.
- 정보 산출후에만 일시 중단할 수 있음
-> yield() or yieldAll() 함수를 호출해야 함
값 산출
값을 산출하면 값이 다시 요청될 때까지 시퀀스 또는 이터레이터가 일시 중단 됨
ex)
val iterator = iterator { yield("First") yield("Second") yield("Third") } println(iterator.next()) println(iterator.next()) println(iterator.next()) /* 원서에서는 buildIterator를 이용해서 iterator를 생성하지만, 코틀린 1.3 버전 부터는 kotlin.sequences.iterator를 사용하도록 변경됐다. */
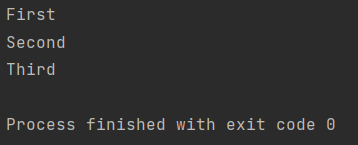
↪ 이 코드는 세 가지 요소를 포함하는 이터레이터를 빌드
요소가 처음 요청될 때 첫 번째 줄이 실행되고 "First"값이 산출 이후 실행 중단
세 가지 요소를 얻으려면 next() 함수를 세 번 호출
실행 중에 일시 중단할 수 없으므로 일시 중단 시퀀스/이터레이터는
일시 중단 불가능한 코드에서 호출할 수 있다. -> runBlocking ❌❌
이터레이터
- 이터레이터의 특성
-
인덱스 요소를 검색할 수 없으므로 요소는 순서대로 액세스할 수 있음
-
더 많은 요소가 있는지 여부를 나타내는 hasNext() 함수 존재
-
요소는 한 방향으로만 검색, 이전 요소 검색할 방법 ❌
-
재설정할 수 없으므로 한 번만 반복할 수 있음 ✔️
일시 중단 이터레이터를 작성하기 위해 iterator()를 사용해 이터레이터 본문과 함께 람다를 전달
달리 지정되지 않는 한 Iterator<T> 를 리턴
-> T는 이터레이터가 생성하는 요소에 의해 결정
-> 어떤 이유든 재정의하려면 타입을 정의할 수 있음
// 컴파일 오류 X val iterator : Iterator<Any> = iterator { yield(1) yield(10L) yield("Hello") } ----------------------------------------------- // 컴파일 오류 발생 val iterator : Iterator<String> = iterator { yield("Hello") yield(1) }
이터레이터와의 상호 작용
모든 요소를 살펴보기
-
이터레이터의 모든 요소를 하나씨 가져오는 대신 한꺼번에 가져오는 경우도 존재
-
전체 이터레이터를 반복하기 위해 forEach() / forEachReamining() 함수를 사용할 수 있음
-> 이터레이터는 한 방향으로만 갈 수 있기 때문에 두 기능 모두 똑같이 동작
iterator.forEach{ println(it) }
⚡
두 함수는 모두 같은 방식으로 작동
일부 요소를 이미 읽었다면 forEachRemaining()을 사용하면 코드를 읽는 사람에게 해당 시점까지 일부 요소가 이터레이터에 없을 수 있음을 명확히 안다.
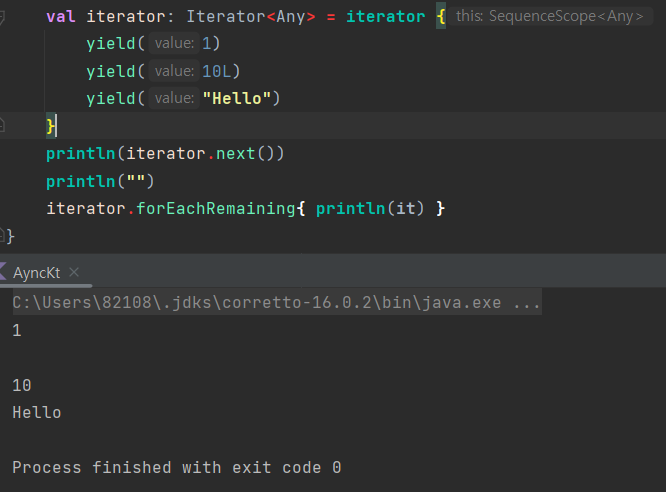
-> ??
다음 값 가져오기
- 이터레이터에서 요소를 읽으려면 next() 를 사용할 수 있음
-> 이 코드는 단순히 각 요소를 출력
요소가 더 있는지 검증하기
- 다른 유용한 함수는 hasNext()
-> 하나 이상의 요소가 있으면 true, 그렇지 않으면 false를 리턴
fun main(args: Array<String>) { val iterator = iterator { for(i in 0..4) yield(i * 4) } for(i in 0..5) if(iterator.hasNext()) println("Element $i is ${iterator.next()}") else println("No more Elements") }
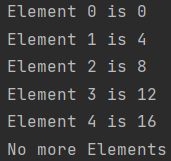
요소를 검증하지 않고 next() 호출하기
- next() 로 이터레이터에서 요소를 가져올 때는 항상 hasNext() 를 호출하는 것이 좋음
-> 검색할 요소가 있는지 확인하지 않으면 NoSuchElementException 발생
val iterator2 = iterator { yield(1) } println(iterator2.next()) println(iterator2.next())
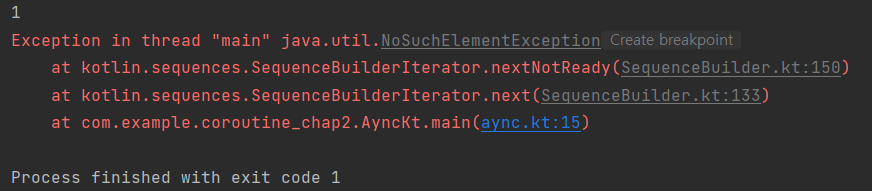
hasNext()의 내부 작업에 대한 참고사항
-
hasNext() 가 작동하려면 런타임은 코루틴 실행을 재개함
-> 새로운 값이 나오면 true를 반환,
더 이상 값이 없어 이터레이터 실행이 끝나면 false를 반환 -
hasNext() 호출로 인해 값이 산출되면 값이 유지되거나 다음에 next() 를 호출할 때 값이 반환
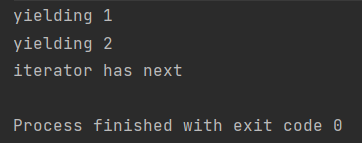
val iterator = iterator { println("yielding 1") yield(1) println("yielding 2") yield(2) } iterator.next() if(iterator.hasNext()) { println("iterator has next") iterator.next() }
시퀀스
- 일시 중단 시퀀스의 특징
-
인덱스로 값을 가져올 수 있음
-
상태가 저장되지 않으며, 상호 작용한 후 자동으로 재설정 됨
-
한 번의 호출로 값 그룹을 가져올 수 있음
- 일시 중단 시퀀스를 만들기 위해 sequence() 빌더를 사용
-> 빌더는 일시 중단 람다를 가져와 Sequence<T>를 반환
-> 여기서 T는 다음과 같이 생성된 요소에 의해 추론 될 수 있음
val sequence = sequence { yield(1) }
- 이터레이터와 유사하게 산출한 값의 타입을 준수하는 T를 지정 가능 !
val sequence: Sequence<Any> = sequence { yield("A") yield(1) yield(32L)
시퀀스의 모든 요소 읽기
- 시퀀스의 모든 요소를 살펴 보기 위해 forEach() / forEachIndexed() 를 사용
-> 둘 다 유사하게 동작
-> forEachIndexed() 는 값과 함께 인덱스를 제공하는 함수
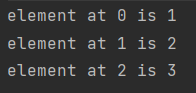
sequence.forEach { print("$it") } sequence.forEachIndexed { index, value -> println("element at $index is $value") }
-
ElementAt()
함수는 다음과 같이 인덱스를 가져와 해당 위치의 요소를 반환
sequence.elementAt(2) -
elementAtOrElse()
함수는 주어진 인덱스에 요소가 없으면 람다로 실행
-> 람다는 전달된 인덱스를 받음
sequence.elementAtOrElse(10,{it*2})
-> 시퀀스에 10개의 요소가 안되면 인덱스 10에 2를 곱한 20을 반환 -
elementAtOrNull()
함수는 인덱스를 가져와서 T?를 반환
-> 주어진 인덱스에 요소가 없으면 null을 반환
sequence.elementAtOrNull(10) -
요소 그룹 얻기
값을 그룹으로 가져올 수 있음
// sequence = (1,1,2,3,5,6,13,21) 이 들어있는 상황 val firstFive = sequence.take(5) println(firstFive.joinToString()) // 1, 1, 2, 3, 5 // 쉼표로 구분된 처음 5 개의 값이 출력
⚡
take()는 중간 연산이므로 나중에 종단 연산이 호출되는 시점에 계산돼
Sequence<T>를 반환한다는 점을 주목
-> 실제로 시퀀스에는 값을 갖지 않지만 joinToString()을 호출하면 값을 갖게 됨
시퀀스는 상태가 없다
- 일시 중단 시퀀스는 상태가 없고 사용된 후에 재설정 됨
val sequence = sequence { for(i in 0..9){ println("Yielding $i") yield(i) } } println("Requesting index 1") sequence.elementAt(1) println("Requesting index 2") sequence.elementAt(5) println("Taking 3") sequence.take(3).joinToString()
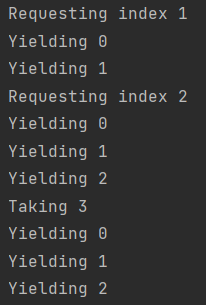
↪ 이터레이터를 사용하는 것과 달리 시퀀스는 각각의 호출마다 요소의 처음부터 실행됨
-> 질문
elementAt은 인덱스를 가져와서 해당 위치의 요소를 반환하는게 아닌가?
-> 해당 위치의 인덱스까지 반환하는 이유가 무엇인지
2편에 계속..
📌참고자료
- CoroutineContext에 대해
↪ https://kotlinworld.com/152
