
※ Notification
본 게시글에서 오탈자나 잘못된 부분이 있다면 댓글로 알려주시면 수정하도록 하겠습니다 :)
연관 포스팅
YOLO Mini Project
Dataset file check
Intro
Dataset file check 이후에 Detection 하고자 하는 이미지를 수집하여 Dataset을 만들고, YOLO 모델을 통해 Detection을 수행하는 Mini Project를 수행했다.
기간은 일주일 주셨으나 데이터셋만 완성된다면 기존 코드를 조금만 수정하면 되니 빠르게 끝내려고 노력했다.
YOLO Mini Project
프로젝트 개요에 대한 내용은 따로 포스팅해두었고, 이 글에서는 진행 과정에 대해서 이야기하도록 하겠다.
YOLO Mini Project
Clothing Detection
Musinsa Brand Snap Image
무신사의 스냅사진에서 각각의 의류를 찾아내는 프로젝트를 진행하기로 했다.
Data Collection
Beanie
Buckethat
Cap
Croptop
Glasses
Handbag
Jeans
Mask
Pants
Shoes
Shorts
Skirt
Top
T-shirts
Coat먼저 데이터셋을 만들기 위해 어떤 데이터를 수집할 것인지 Dataset의 class를 정의했다.
상의의 경우 Outer, shirt 등 좀 더 세분화 하려고 했지만, 프로젝트 기간이 짧기 때문에 일단은 Top으로 통일한 후 진행했다.
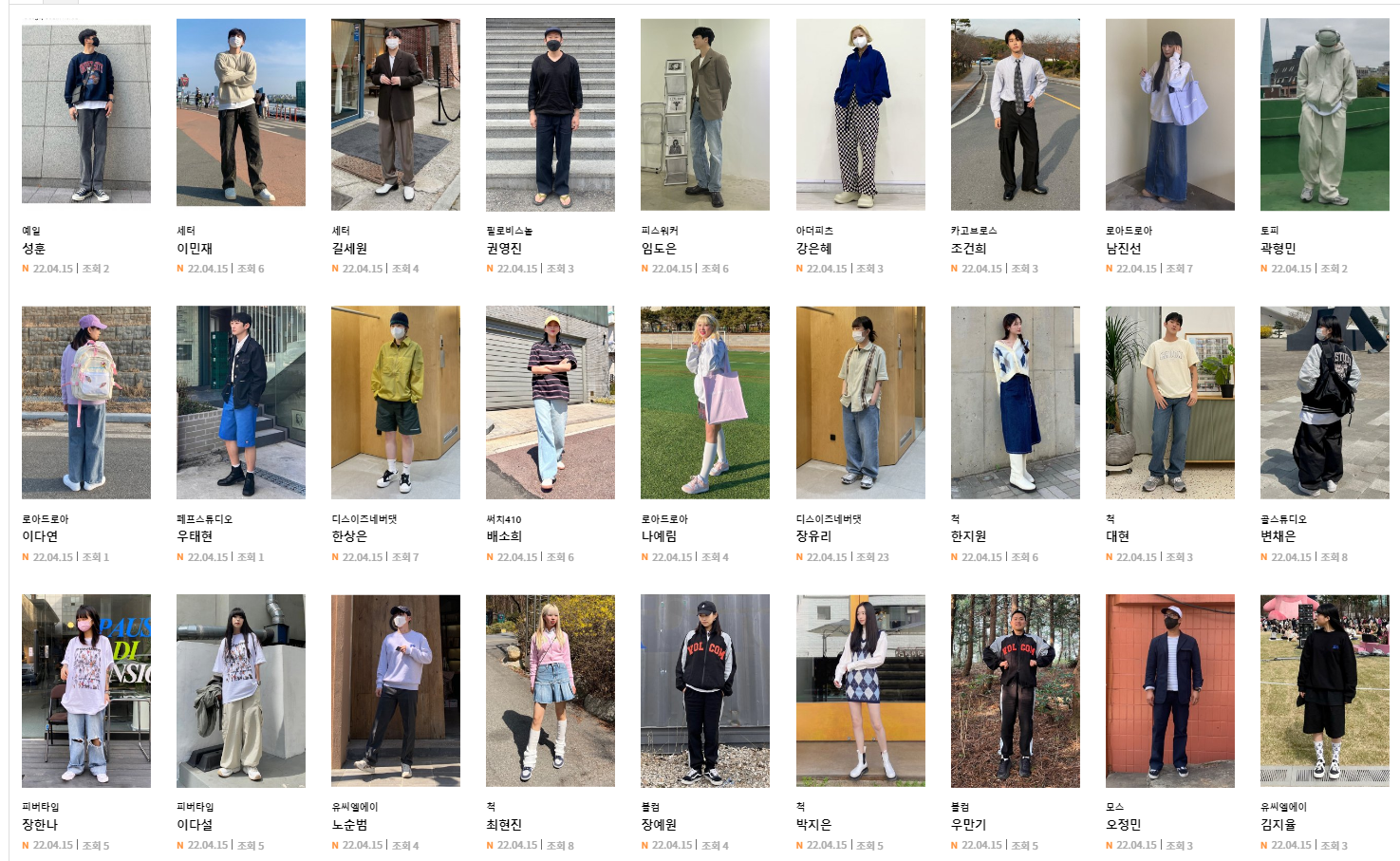 그 후 무신사 브랜드 스냅의 검색 기능을 활용해 각 class 별 이미지를 수집하였다.
그 후 무신사 브랜드 스냅의 검색 기능을 활용해 각 class 별 이미지를 수집하였다.
크롤링 코드를 만들어 수집할까도 고민했지만 단기적인 프로젝트라 코드 작성에 시간을 할애하는 것이 효율적이지 못하다 생각되어, 손수 다운로드를 진행했다.
목록에서 보이는 사진은 해상도가 낮기 때문에 각 페이지에 일일이 접속하여 다운로드를 진행해줘야 했다.
지금 생각하면 크롤링 코드를 작성하는 것이 더 효율적이었다고 생각한다.
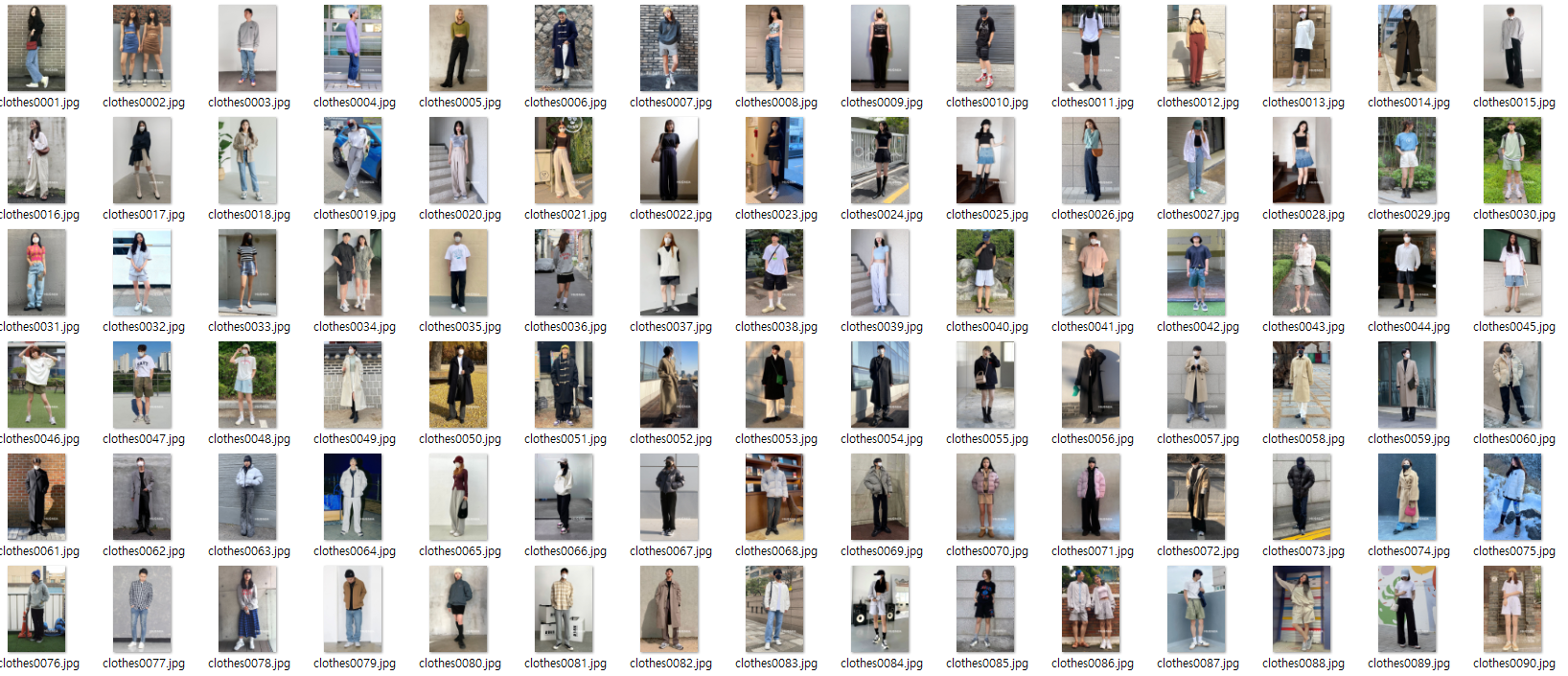 해당 방식을 통해 300개 이상의 이미지를 다운로드하고, 전처리를 통해 옷의 형태가 구분되지 않는 측면 사진, 각 의류의 구분이 뚜렷하지 않은 사진 등을 삭제처리해주어 300개의 이미지를 수집하였다.
해당 방식을 통해 300개 이상의 이미지를 다운로드하고, 전처리를 통해 옷의 형태가 구분되지 않는 측면 사진, 각 의류의 구분이 뚜렷하지 않은 사진 등을 삭제처리해주어 300개의 이미지를 수집하였다.
Image labeling
그 다음 labelImg 툴을 이용하여 Image에 대한 labeling을 진행해주었다.
YOLO 이미지 라벨링을 위한 labelImg 사용법
설치 과정 및 사용법은 위 링크에서 확인할 수 있다.
해당 과정을 통해 300개의 이미지에 대한 labeling을 진행했다.
Train, Test, Validation Split
Python 코드를 통해 데이터셋을 분리해주었는데, 모든 데이터에서 10%를 분리해 validation data로 옮긴 후 나머지 데이터에서 9:1의 비율로 train, test data를 구성했다.
주요 코드는 다음과 같다.
import random
split_ratio = 0.1
img_file_name_list = list(map(lambda x : x.split('.')[0], os.listdir(TRAIN_IMAGE_DATA_DIR)))
split_num = int(len(img_file_name_list) * split_ratio)
random.shuffle(img_file_name_list)
move_file_name_list = img_file_name_list[:split_num]
print('=======================================')
print('train -> valid 10% / start moving...')
for file_name in move_file_name_list:
shutil.move(os.path.join(TRAIN_IMAGE_DATA_DIR,file_name) + IMG_EXTENSION,
os.path.join(VALID_IMAGE_DATA_DIR,file_name) + IMG_EXTENSION)
shutil.move(os.path.join(TRAIN_LABEL_DATA_DIR,file_name) + LABEL_EXTENSION,
os.path.join(VALID_LABEL_DATA_DIR,file_name) + LABEL_EXTENSION)
print('=======================================')
print('train nums : ', len(os.listdir(TRAIN_IMAGE_DATA_DIR)),'\ntrain nums : ', len(os.listdir(TRAIN_LABEL_DATA_DIR)))
print('valid nums : ', len(os.listdir(VALID_IMAGE_DATA_DIR)),'\nvalid nums : ', len(os.listdir(VALID_LABEL_DATA_DIR)))
print('=======================================')Dataset
Train, Test, Validation으로 구분된 Image, label 파일에 더불어 학습을 위한 yaml 파일을 생성해줬다.
train: ../train/images
val: ../valid/images
nc: 15
names: ['Beanie', 'Buckethat', 'Cap', 'Croptop', 'Glasses',
'Handbag', 'Jeans', 'Mask', 'Pants', 'Shoes', 'Shorts',
'Skirt', 'Top', 'T-shirts', 'Coat']완성된 데이터셋의 구성은 다음과 같다.
Clothes_Data
├─ test
│ ├─ images
│ └─ labels
├─ train
│ ├─ images
│ └─ labels
├─ validation
│ ├─ images
│ └─ labels
└─ data.yamlModeling
[17일 차] YOLOv5 - Mask Wearing detection
모델링 관련한 내용은 17일차 내용을 참고바란다.
Clothes Dataset을 YOLOv5 v6.0 YOLOv5s 모델을 이용하여 학습했다.
Result
 비교적 결과가 잘 나왔지만, Jeans과 Pants가 겹쳐서 나타나는 이미지도 있었다.
비교적 결과가 잘 나왔지만, Jeans과 Pants가 겹쳐서 나타나는 이미지도 있었다.
첫번째 사진을 보면 Jeans의 연두색 Bounding Box와 Pants의 초록색 Bounding Box가 겹쳐져 있는 것을 알 수 있다.
프로젝트 포스팅에서도 언급했지만 청바지의 이미지와 다른 재질의 바지 이미지를 더 수집하여 Jeans과 Pants의 인식률을 높일 필요성이 있다.
Outro
직접 Dataset을 구축하고, 이를 통해 Object detection을 진행해봤다. 생각보다 결과가 좋게 나와서 놀랐다.
크롤링을 통해 더 많은 이미지를 다운로드하고, 상의를 Top으로 통일하지 않고 여러 종류로 나누어서 다시 시도해본다면 좋을 것같다.

안녕하세요 라벨링하는 글부터 detection 프로젝트 관련 글 잘봤습니다! 저도 관련해서 공부하고싶어서 무신사에서 데이터 수집하고 비슷하게한 공부과정을 블로그에 정리해도 될까요? 출처랑 참고 남기겠습니다!