개요
최근에 서비스기업 회사면접을 봤습니다. 문제상황은 다음과 같았습니다.
면접관 : 이력서에 트랜잭션 이야기를 했는데, DB의 트랜잭션과 스프링에 @Transactional에 대해 아는한 설명해주세요..!
나 : 트랜잭션은 롤백이 된다는 특징이 있고... (이후 머리가 하애졌다..)
심각했다.. 트랜잭션에 대해 분명 당연하게(?) 쓰고 DB에 있는 개념 역시 이해를 했는데, 막상 설명하려니까 표현에 어려움이 있었습니다. 그래서 이왕 이렇게 된거 정리해보고 싶었습니다.
트랜잭션이 왜 필요한거지?
트랜잭션은 쉽게 말하면 더 이상 나눌 수 없는 실행 단위를 의미합니다. 만약 A라는 사용자가 입금이 이루어 진다면, 은행은 +10000원 A는 수중에 -10000원이 됩니다.
만약 이걸 나눈다면, A라는 사용자는 아무 이유없이(?) 돈을 잃어버리는 상황이 되겠죠..
그리고 은행은 영문도 모른채(?) 돈을 10000원을 얻게 됩니다.
그렇기 때문에 값을 빼는 작업과 넣는 작업을 하나의 트랜잭션으로 묶어야 합니다.
트랜잭션을 DB에서 묶는방법?
우리가 MySQL을 쓴다 가정할 때, WorkBench나 Data Grip 같은 툴을 이용하게 된다면..
Update나 Insert를 실행을 하면 한건 마다 바로 적용이 되는 경우가 있을 수 있습니다.
이는 Auto Commit가 실행이 되어있기 때문입니다.
즉 트랜잭션을 묶기 위해서는 원하는 명령어(위를 기준으로 입금과 출금을 위한) 여러 명령어를 실행한다음에 커밋을 하게끔 해야 합니다. 따라서 Auto Commit를 비활성화 해야합니다.
하지만, 일회성(?)의 목적으로 단순히 트랜잭션을 테스트하고 싶은 목적이라면, START TRANSACTION 명령어를 실행해도 괜찮습니다.
DB에서 트랜잭션을 보장할 수 있는 이유?
DB의 트랜잭션 처리는 세션이라는 곳에서 이루어집니다. 즉 세션에 여러 트랜잭션들이 들어오게 되고 실행이 되는 것입니다. 그러면 우리는 궁금한게 있을겁니다.
여러개의 트랜잭션이 발생하면... 어떻게 작동이 되고, 그 과정에서 OS의 멀티 스레드 환경에서 발생할 가능성이 있는 데드락 같은 상황이 발생하지 않을까? 라는 생각이..
실제로 멀티스레드 환경에서 코딩을 했을 때, 객체를 잘못 쓰게 되면 데이터의 정합성이 깨지는 사이드이펙트가 발생할 수도 있습니다.
하지만 DBMS는 정합성, 무결성, 보안성을 보장한다고 말을 합니다. 왜 그럴까요?
즉 어떻게 데이터의 정합성을 보장할 수 있을지가 궁금할 수 있습니다.
트랙잭션 속성
답은 트랜잭션의 4대 속성에 있습니다. 트랜잭션의 경우 ACID라는 속성을 가지고 있습니다. 결국 이 속성이 있는 가장 큰 이유는 안전한 수행과 최대한의 무결성의 보장입니다.
무조건이 아닌, 최대한이라고 말한 이유는 트랜잭션의 격리수준에 따라 트랜잭션의 실행 순서 역시 달라질 수 있기 때문입니다.
ACID?
ACID를 이야기 해보겠습니다.
원자성 : 트랜잭션은 부분적으로 수행하다 중단되는 일이 없어야 한다.
일관성 : 실행이 완료되면 데이터베이스 상태로 유지가 되어야 한다.
독립성 : 여러 트랜잭션은 서로 연산작업에 끼어들 수 없도록 보장해야 한다.
-> A트랜잭션에서 Insert가 실행되고 있는데, 갑자기 끼어들어서 B트랜잭션에서 Update를 하는 일이 없게 되는거죠..
지속성 : 커밋 된 트랜잭션은 영원히 반영이 되어야한다.
-> 커밋되면 DB에 무조건 들어있어야 되는거죠.
트랜잭션에서 원자성이 보장된다고?
네트워크상의 이슈 등으로 인해 트랜잭션이 실패할 가능성이 있고, 문법이슈 등으로 인해
트랜잭션이 재대로 작동이 안될 수 있습니다. 그러면 어떻게 트랜잭션은 이러한 이슈를 해결할까요?
바로 UNDO와 REDO를 통해 해결합니다. 트랜잭션은 별도로 UNDO, REDO를 가지고 있습니다. 이유는 UNDO의 경우, 트랜잭션이 실행되다 갑자기 실패하면, 같은 트랜잭션에서 정상적으로 실행 된 것들도 모두 실패 시켜야 됩니다. 그렇기 때문에 롤백을 해야되는거고요. UNDO는 트랜잭션이 실행하기 전의 데이터입니다. 따라서 롤백이 가능합니다.
하지만 네트워크 오류로 트랜잭션이 실행 중에 잠깐 멈출 수도 있습니다. 만약 트랜잭션의 처리시간이 엄청 긴 상황이라면, 롤백을 하는데도 그만큼의 시간이 걸릴겁니다.
(예를 들어 30기가짜리 온라인 게임을 99%까지 다운받았는데.. 갑자기 네트워크가 1초 끊겨서 0%부터 다시 시작해야된다면..? 상상만 해도 끔찍할거 같습니다...)
잠깐 네트워크 이슈로 롤백을 시키면, 다시 또 해당 트랜잭션을 실행해야되니까.. 처리속도 상에 이슈가 발생할 수 밖에 없습니다. REDO는 실패한 실행문을 다시 실행하게끔 저장하기 때문에 실패한 시점부터 재요청을 할 수 있기 때문에 처리속도상 이점이 있습니다.
트랜잭션 격리수준?
동시성과 연관이 되어있습니다. 결국 독립이 될 때도 기준이 있습니다.
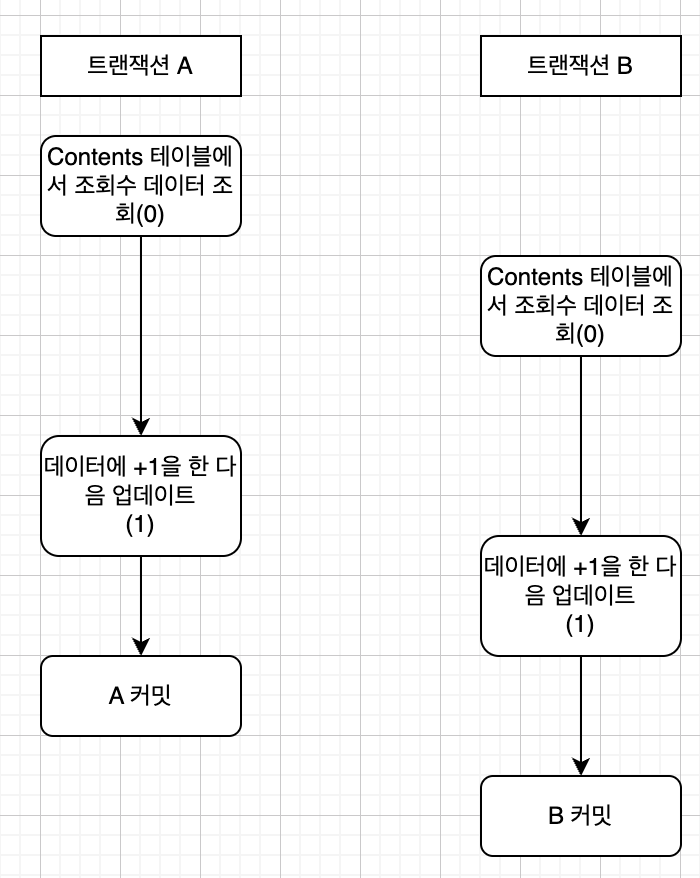
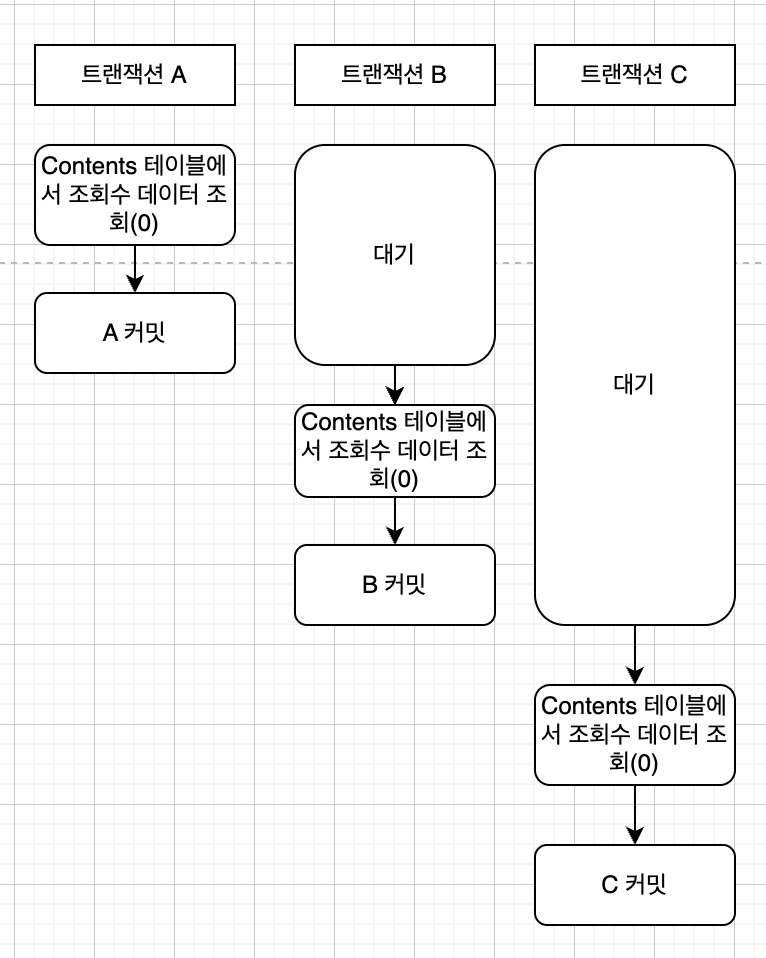
만약 조회수라는 데이터가 있고 0이라고 가정하겠습니다.
트랜잭션이 이와 같이 실행이 되면 어떻게 될까요?
이렇게 되면 결국 개발자는 조회수를 +2를 기대했지만, 아쉽게도 +1로 나오게 됩니다. 즉 같은 데이터를 읽고 업데이트를 할 때 동시성 문제가 발생하게 됩니다.
트랜잭션 격리 수준이 필요한 이유는 이와 같이 동시성 이슈가 발생했을 때, 여러 트랜잭션이 동시에 실행되더라도, 동일한 결과를 보장하기 위해 사용합니다.
트랜잭션 격리수준
정의를 설명하면 길기 때문에, 간단하게 왜 필요한지만 적고 넘어가겠습니다.
격리수준에 대한 특징은 MySQL DB엔진인 InnoDB 기준으로 설명하겠습니다.
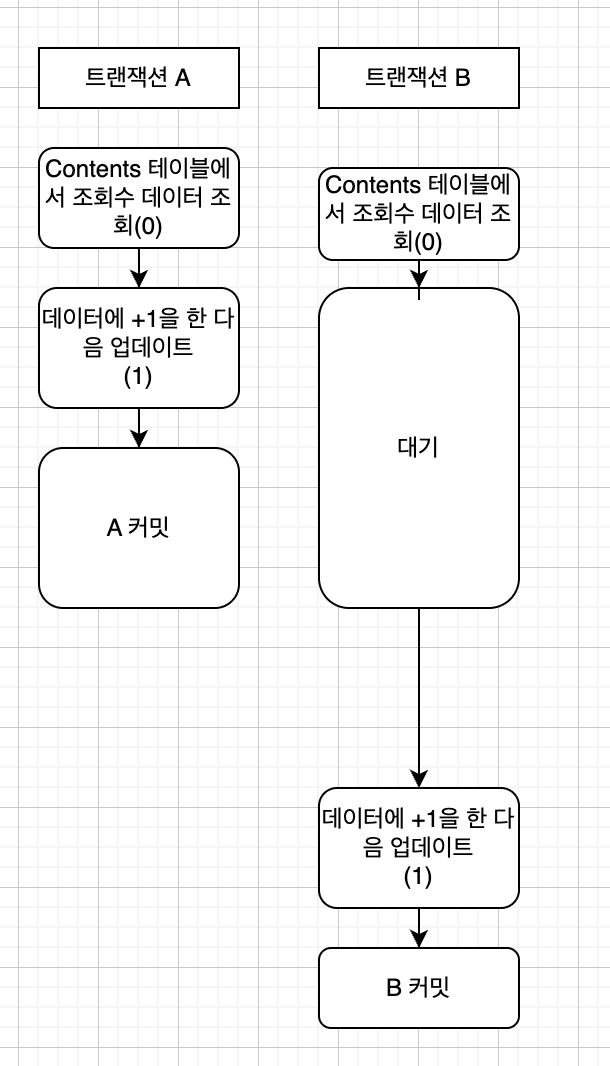
Read Commited
커밋한 것만 읽는 것, 커밋한 것만 읽고 쓸 수 있게 하는 것입니다. 커밋을 하지 않았는데, 데이터를 변경하는 Dirty Read 등을 방지하기 위해 사용하는 것이죠
어떻게 가능할까요?? 바로 행 단위로 락을 사용하기 때문입니다.
Read Commited가 이렇게 간단한건가?
이 생각이 들 수도 있다고 본다.
만약 두개의 트랜잭션이 있고, 둘다 Update가 동시에 일어나게 된다면 어떻게 될지?
결론만 말한다면, DB엔진에 따라 다릅니다. InnoDB의 경우 행 단위로 shared lock 하기 때문에,
즉 B의 트랜잭션이 업데이트를 수행할 때는 트랜잭션 A가 커밋된 이후에 수행을 하게 됩니다. 따라서 이와 같습니다.
(만약 B가 shared lock이 걸린 상태에서 데이터를 읽는다면? 수정 된 데이터를 읽지 않고 UNDO(업데이트 하기 전)에 저장되어 있는 데이터를 읽습니다.
Repeatable Read
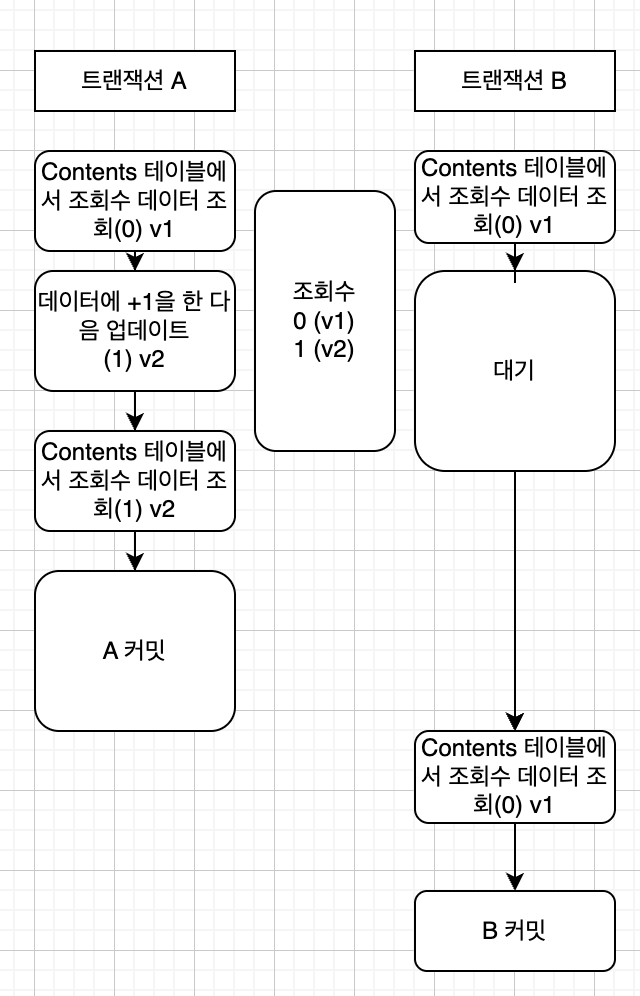
Repeatable Read
-> 말그대로 반복적으로 읽어도 동일한 데이터를 읽을 수 있게 하는 것입니다. 이것이 가능한 이유는 스냅샷의 특징 때문입니다. A와 B의 트랜잭션이 있을 때, insert 등의 작업을 하게 된다면 스냅샷의 버전은 트랜잭션 마다 다른 버전을 읽게 됩니다.
즉 다른 트랜잭션이 커밋이 되더라도 이전에 조회한 스냅샷 버전의 정보를 읽습니다.
그러면 스냅샷 버전은 올라간 것을 다른 트랜잭션에서 읽을 수 없도록 해야 되지 않은가? 라는 생각이 들 수 있습니다.
정답입니다. Repeatable Read에서는 데이터 변경과 관련 있는 업데이트 등이 실행 될 때 Exclusive Lock이 발생합니다. 즉 이 데이터는 다른 트랜잭션에서 쓰는것 뿐만아니라, 읽는 것 역시 할 수 없습니다. 따라서 이러한 특징이 있기 때문에 반복해서 읽어도 동일한 데이터를 읽을 수 있는 특징이 있는거죠..
Serializable
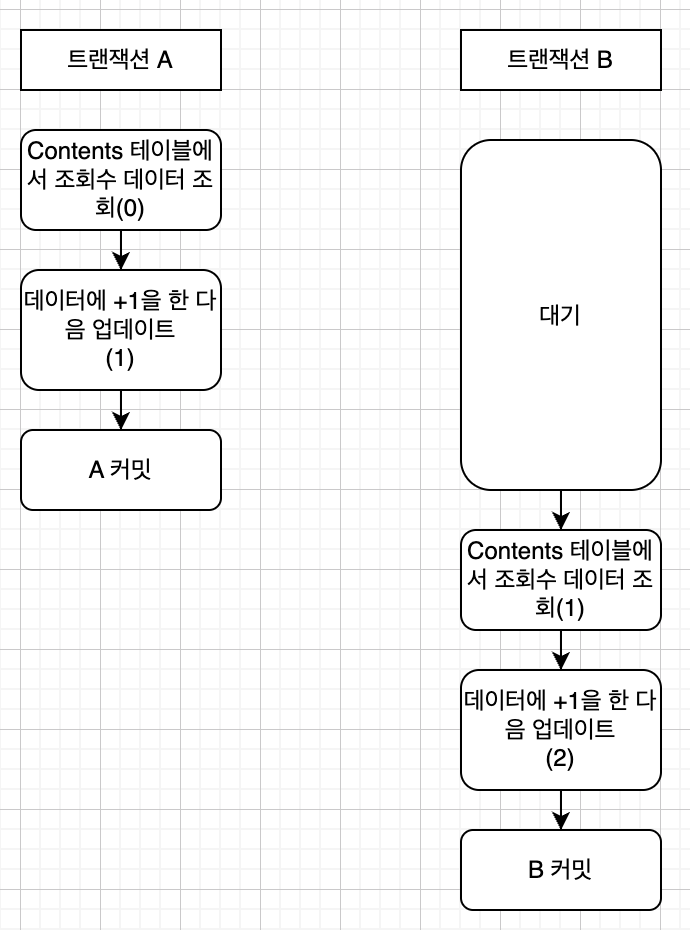
신기하게도 더 높은 격리수준이 있습니다. 바로 Serializable입니다. Serializable와 Repeatable Read의 결정적인 차이는 락을 거는 것의 차이입니다. 바로 Serializable는 자체에도 락을 건다는 특징이 있습니다. 이유가 뭘까요?
Repeatable Read는 데이터의 정합성을 보장할 수는 있지만, 테이블 레코드의 수를 보장할 수는 없기 때문입니다.
예를 들어 트랜잭션 A와 B가 있고 테이블에 1, 2레코드가 있다고 가정하겠습니다.
A에서 테이블을 조회합니다. 레코드가 2개 읽힙니다.
B에서 테이블에 insert를 하고 커밋합니다. 레코드는 3개가 되고, 추가된 레코드에만 exclusive Lock이 걸립니다.
이후 A에서 테이블을 조회합니다. 그러면 데이터는 동일하지만, 레코드의 수를 보장할 수 없습니다.
결국 이를 해결하려면 어떻게 해야될까요? 바로 테이블에 접근하는 시점에 접근한 트랜잭션이 끝날 때까지 락을 거는 것입니다.
격리수준 높이면 무조건 좋은건가?
격리수준을 Serializable까지 높이게 된다면.. 물론, 여러 트랜잭션이 동시에 실행하더라도 동일한 실행결과를 보장할 수는 있습니다. 하지만, 처리속도가 아무 느릴 가능성이 있습니다. 굳이 데이터의 동시성처리에서 정합성 보장이 필요하지 않다면... 격리수준을 높이는 것이 과연 정답일까? 라는 생각을 해볼 필요는 있을 것 같습니다.
예시로
이렇게 트랜잭션 격리수준을 높이면.. 물론 데이터의 정합성을 보장하지만,
이런 상황도 발생하기 때문에, 상황에 맞게 쓰는게 좋다고 생각됩니다..
@Transactional를 쓰는 이유가 뭐지?
결론만 말한다면, 안써도 개발자가 맘만적으면 만들 수 있습니다. 예전에 JdbcTemplate를 간단하게(?) 써본분들은 알거라고 생각합니다.
jdbc를 연결할 때 상황은 다음과 같았습니다.
DateSource를 만들고 환경설정(url, 아이디, 패스워드 등)을 한 뒤 만약 코드를 작성하게 된다면..1. DateSource를 통해 Connection 설정 2. 트랜잭션 시작 3. 쿼리 실행 4. 트랜잭션 커밋 5. 트랜잭션 롤백(예외발생 시) 6. Connection 종료이 과정으로 되어있습니다.
하지만 우리도 잘 알겠지만 우리는 서비스를 개발하게 될 경우, 3번을 제외하고 1,2,4,5,6은 스프링 부트에서 설정을 할 필요 없이 잘 되어있습니다. 왜 개발자들은 예시로 3번에서 insert를 하는데 5번에 있는 트랜잭션 롤백을 하기위해 Delete와 같은 명령어를 작성 안해도 스프링부트에서 하면 알아서 문제 생기면 롤백이 되는 이유가 뭘까요? 스프링부트에서 이를 어떤 방식으로 동작하는지를 알고 싶었습니다.
@Transactional에 대해서
DB설명하다 너무 길어서, 다음 포스팅에서 말하겠습니다...
