개요
IT-Hermes 프로젝트 개발과정에서 크롤링을 하는 것을 Node로 진행을 했었습니다. 하지만, 이슈가 발생한 것이 있었는데, 상황은 다음과 같습니다.
상황
유투브 데이터를 크롤링 해오려고 했습니다. 하지만.. 처음 접근할 때 유튜브 데이터는 크롤링을 하기 어려울정도로 데이터가 매우 복잡해서 규칙을 찾는 것이 어려웠습니다.
그래서 생각한 것은 puppeteer(퍼퍼티어)를 통해 직접 웹 사이트를 띄우고, 거기에서 데이터를 파싱하면 되겠지...? 였습니다.
이슈상황
puppeteer(퍼퍼티어) 라이브러리는 결과적으로 제가 원하는 웹 사이트를 띄우고, 그 안에 있는 데이터를 파싱한다는 점에서 장점이 있었습니다. 하지만...
처리속도의 이슈가 너무 심각했습니다. 약 50개의 데이터를 파싱함에도 불구하고, 28초가 걸리는 이슈가 생긴거였습니다.
상황분석
결론은 UI를 띄우고, 웹 사이트를 요청한 다음, 웹 사이트에서 Node 서버에 데이터를 가져오는 것이 원인이라 봤습니다.
느린 이유를 생각한 처리과정은 다음과 같습니다.
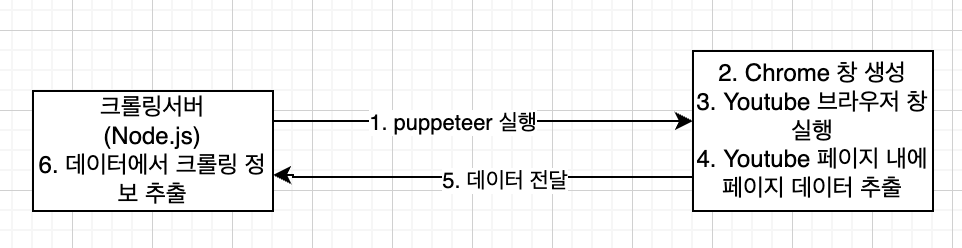
pupperteer의 단점?
우선 위에 그림에서 2,3,4번 과정에서 많은 처리시간을 보여 성능상의 이슈가 존재합니다. 또한 가장 큰 단점은 웹 페이지의 창 크기에 따라 보여지는 데이터가 다르다는 점입니다. 즉 데이터를 가져오는 것은 페이지의 창 크기에 따라 결정이 되고, 그렇다고 웹 페이지를 크게 하게 된다면, 2,3번 과정에서 처리속도는 더 늘어나게 됩니다.
개선
이렇게 2,3 과정을 없애고 데이터를 분석하여 Youtube를 크롤링했습니다.
(물론 데이터가 상당히 복잡했지만.. 어떻게 잘 반복적인 정보를 확인을 했던거 같네요..)
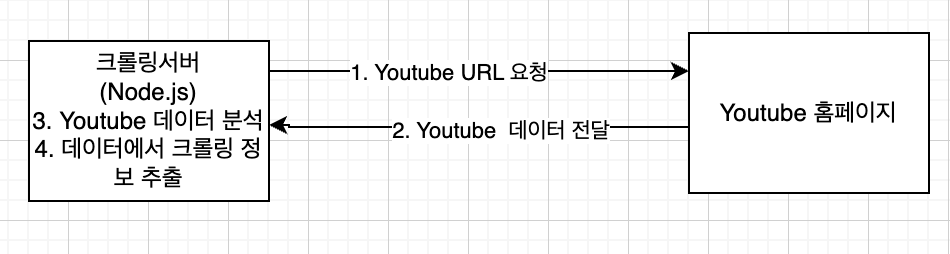
결과
처리속도의 경우 기존과 다르게 10~50배 이상 개선할 수 있었습니다.
웹 브라우져를 띄우고, 요청과 응답을 위한 처리시간이 상당히 오래 걸리는거로 봤을 때, 네트워크의 비용이 생각보다 크다는 것을 개발하는 과정에서 깨달을 수 있었던거 같습니다!

