Programmers
1.<Programmers> Heap_disk controller c++
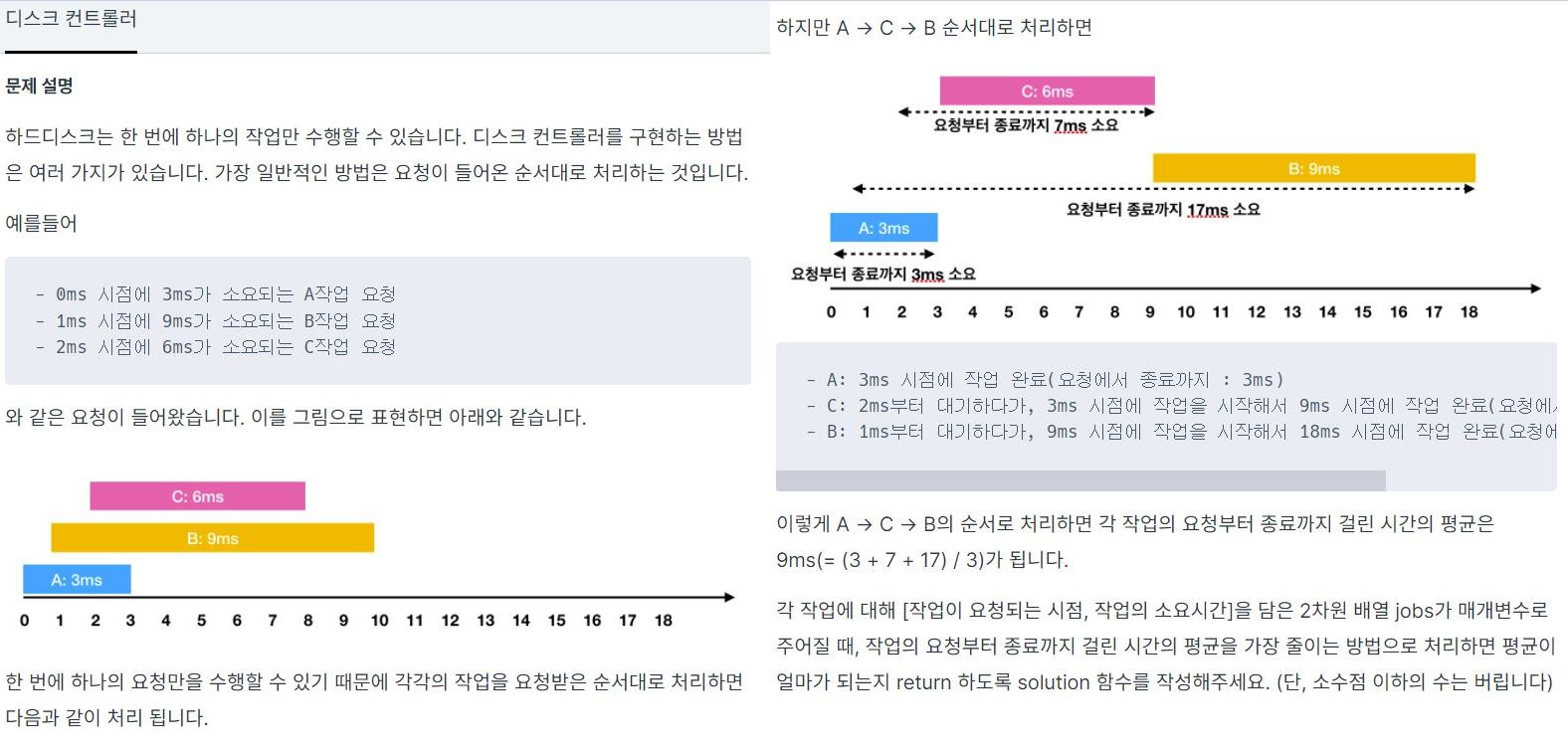
문제는 위와같이 한 번에 하나의 작업만 수행할 수 있는 하드디스크에 작업이 들어왔을 때, 요청부터 종료까지 걸린 시간이 평균을 가장 줄이는 방법으로 처리하는 평균을 구하는 문제이다.priority_queue를 구현할 때 제일 첫 번째 인자는 queue에 담길 자료형,
2.<Programmers> Heap_더 맵게, Priority queue 구현 c++

우선순위 큐는 순서대로 기다리고 있는 자료들을 저장하는 자료 구조 라는 점에서 큐와 비슷하지만, 우선순위가 가장 높은 자료가 가장 먼저 꺼내진다는 차이가 있다.우선순위 큐는 이진 검색 트리보다 훨씬 단순한 구조로 구현할 수 있는데, 그중 대표적인 것이 heap 이라는
3.<Programmers> Heap_Double Priority Queue c++
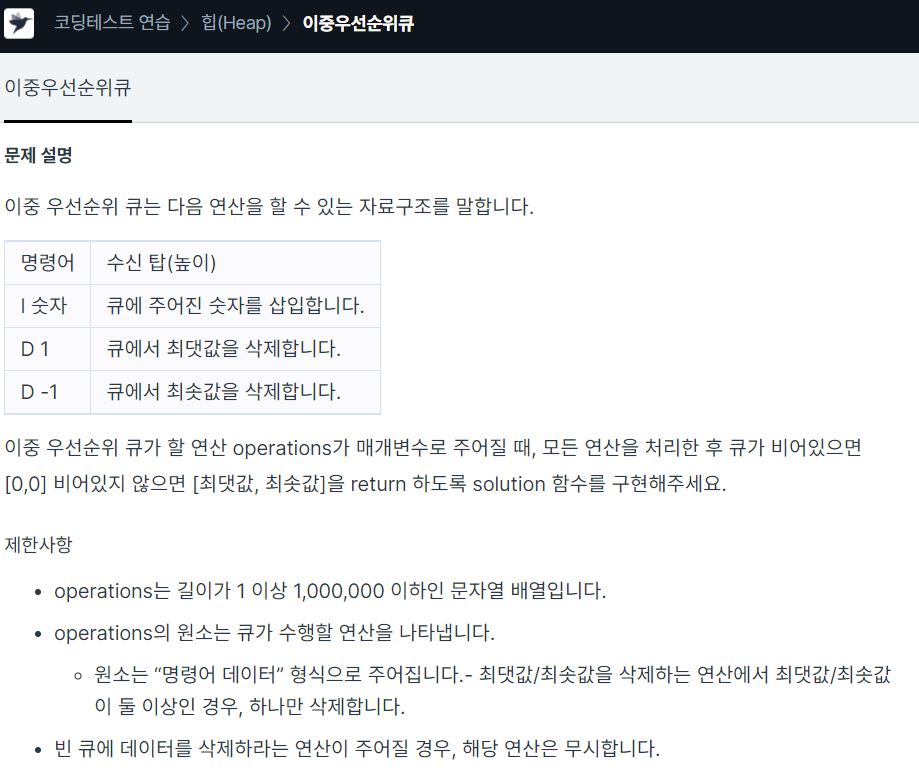
queue에서 단순하게 최댓값과 최솟값만 구하면 되므로 min heap과 max heap 두 개를 만든다.push는 각 queue에 해주고 max값을 pop할 경우 max heap에서, min값을 pop할 경우 min heap에서 pop을 해준다.
4.<Programmers>Brute Force_소수 찾기 Finding Prime Numbers c++
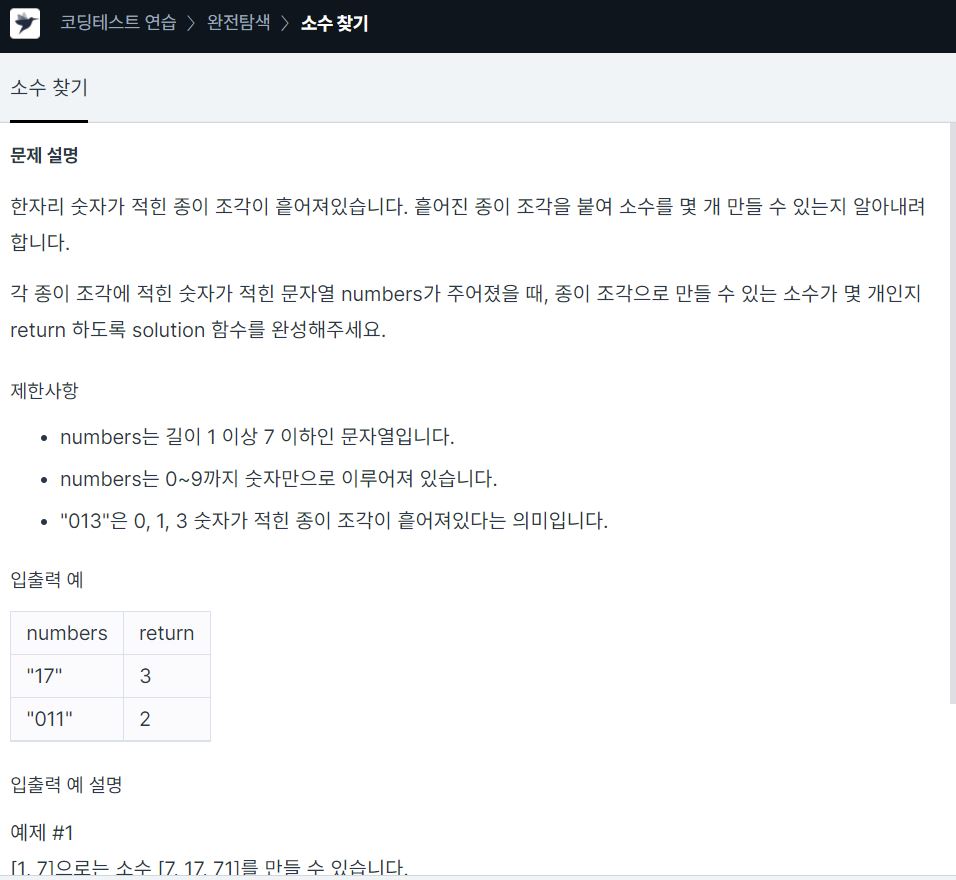
소수를 구하는 부분은 쉽게 구현할 수 있었는데 모든 순열을 구하고 중복된 값을 제외한는 과정을 구하지 못해서 다른 사람의 코드를 참고 했다.처음에는 for문을 i=2 to i=n-1 까지 돌리는 코드를 작성 하였는데 에라토스테네스의 체 라는 방법을 배웠다.<위키백
5.<Programmers> Brute Force_카펫 Carpet c++
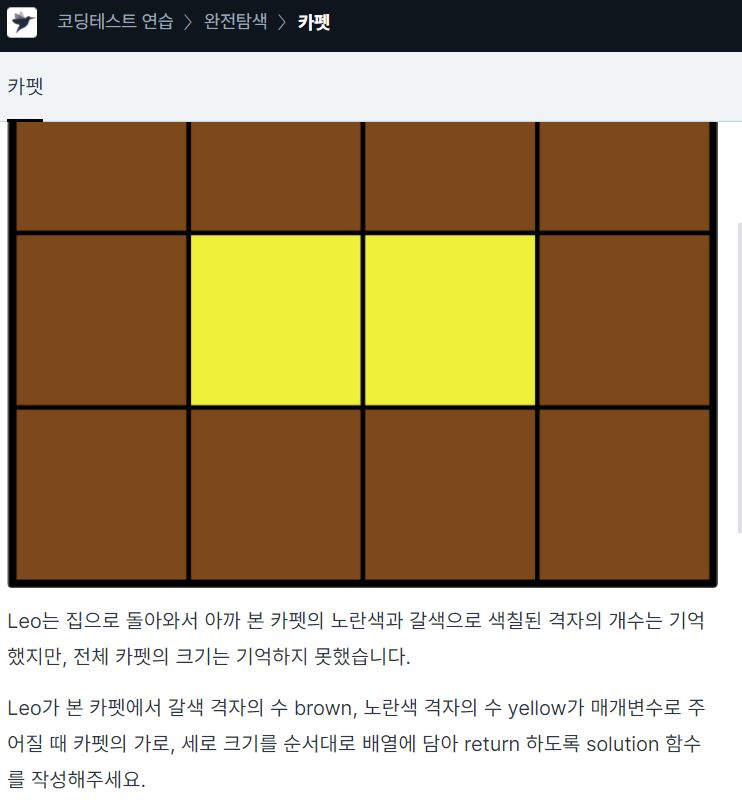
1. yellow 카펫의 가로를 y, 세로를 x 라고 두었을 때, brown 카펫의 가로는 y+2, 세로는 x+2 이다. brown 카펫의 개수는 (y+2)(x+2) - (yx) 이다. >2. yellow 카펫의 가로, 세로의 쌍을 구해주면 된다 y*x=yellow
6.<Programmers> DFS/BFS_타겟 넘버 (Target Number) c++
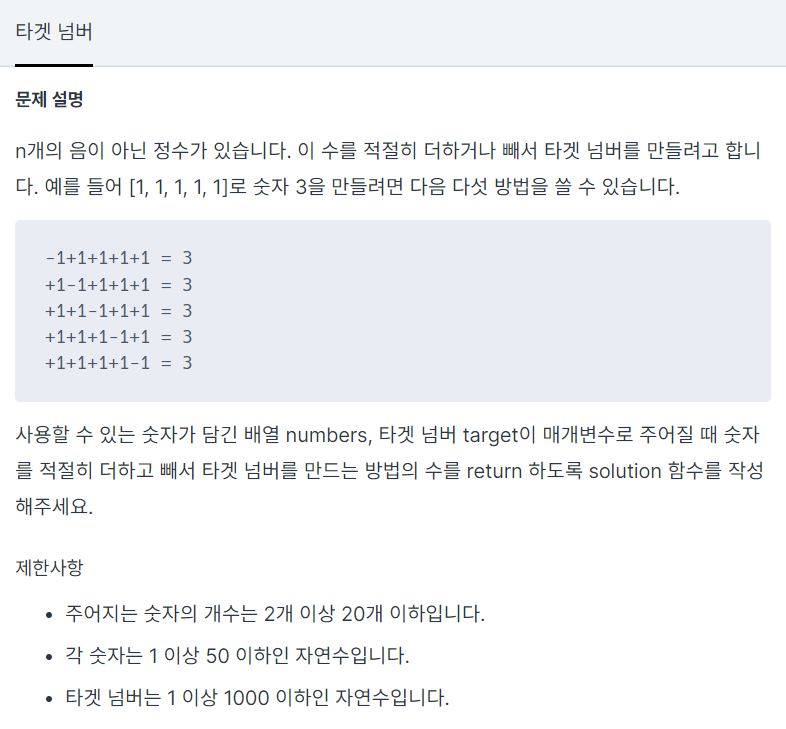
테스트 케이스로 주어진 예를 보면 {1, 1, 1, 1, 1} 이 주어져 있을 때 이 숫자들을 +, -로 적당히 조합해서 Target Number가 되는 경우의 개수를 세는 것이다. 처음 수가 +1 인 경우와 -1인 경우로 나누어 생각하면 { +1, a, b, c,
7.<Programmers> DFS/BFS_단어 변환 (convert words) c++
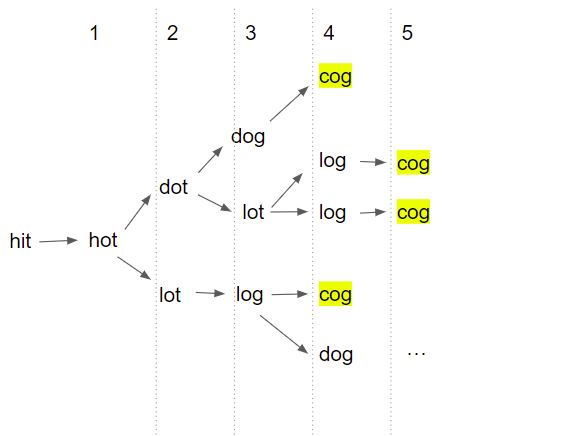
단어 변환 문제 링크문제에 나와있는 예시hot, dot, dog, lot, log, cog에서 hit->cog 로 가는 방법을 도식화하면 이렇게 나타낼 수 있다.한 번에 한 개의 알파벳만 바꿀 수 있기 때문에 현재 단어와 한 글자만 다른 단어를 찾는 함수를 만든다단어가
8.<Programmers> DFS/BFS_여행 경로(Travel Route) c++
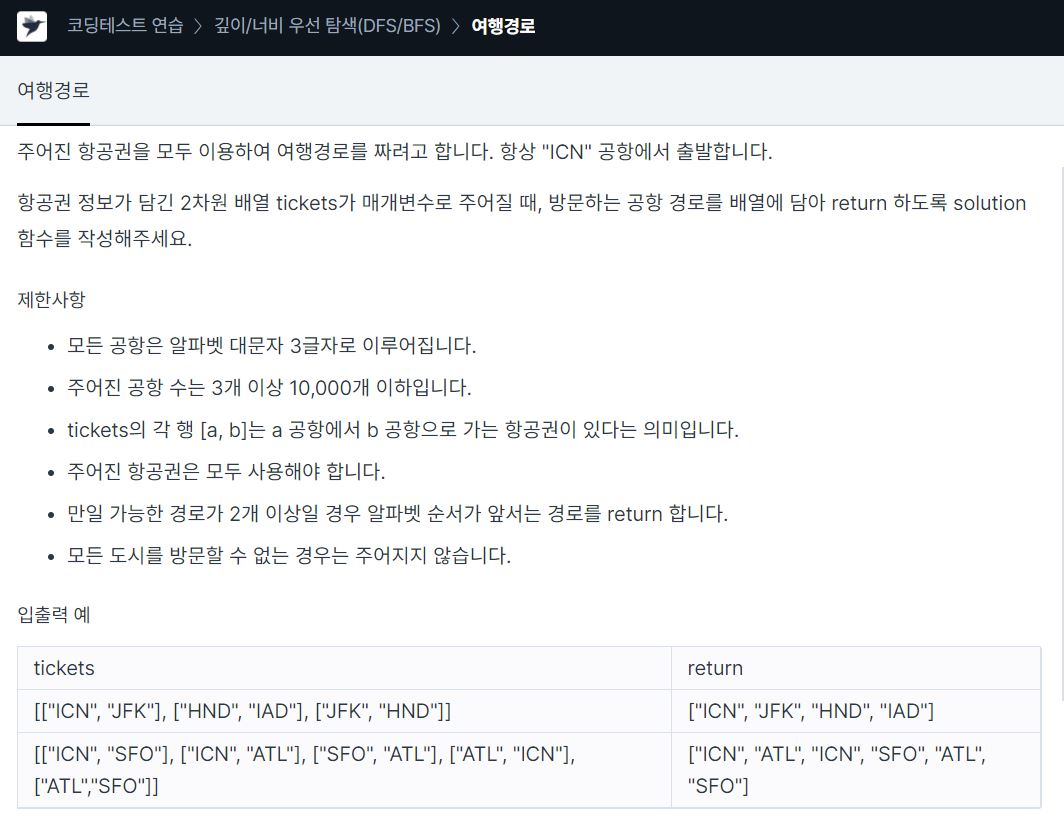
여행 경로 문제 링크문제를 보면 a공항에서 b공항으로, b공항에서 c공항으로 가는 항공권이 있을 때 a,b,c 순서대로 출력해야 한다.DFS를 사용하여 문제를 풀고, 주어진 항공권은 모두 사용해야 하므로 모든 tickets의 정점을 방문해야 한다가능한 경로가 2개 이상
9.<Programmers> Sort_가장 큰 수 c++
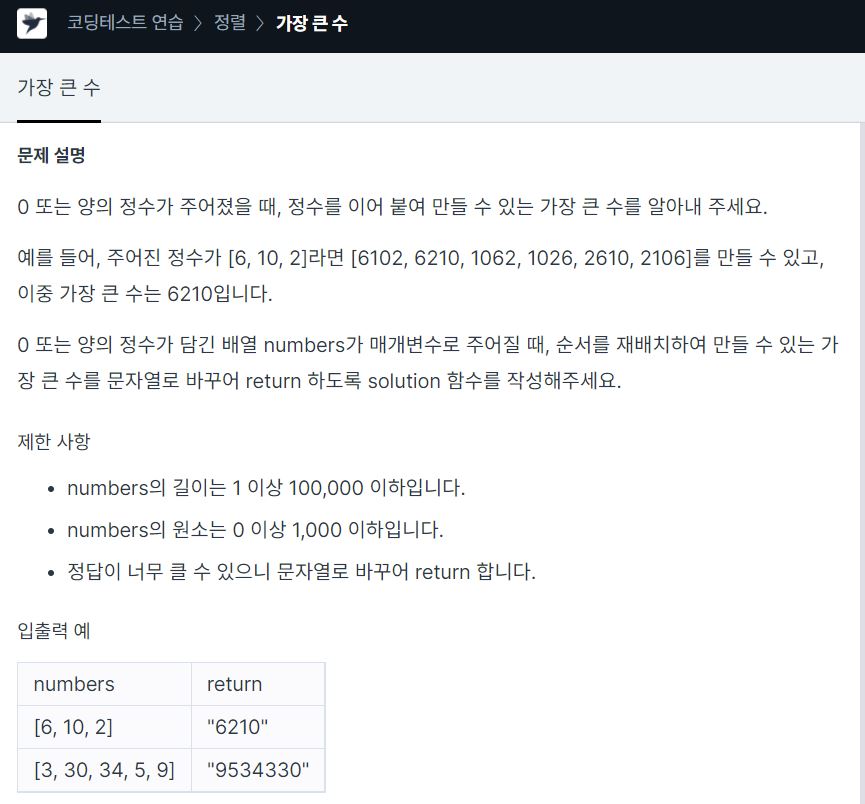
numbers의 길이가 최대 100,000까지 가능하므로 순서를 재배치하여 만들 수 있는 가지수는 최대 100000!이 된다. 따라서 모든 경우의 수를 구하는 것은 잘못된 접근 방법이다.문제의 예시 처럼 {6, 10, 2} 가 있을 때 "610"과 "106", "62"
10.<Programmers> Hash_완주하지 못한 선수 c++

먼저 문제에 들어가기 앞서 unordered_map 에 대해 정리unordered_map1\. unordered_map은 중복된 데이터를 허용하지 않음2\. map은 데이터를 정렬하여 저장 (삽입, 제거가 빈번할 때 성능이 저하)3\. index로 접근할 수 없고, i
11.<Programmers> Hash_전화번호 목록 c++
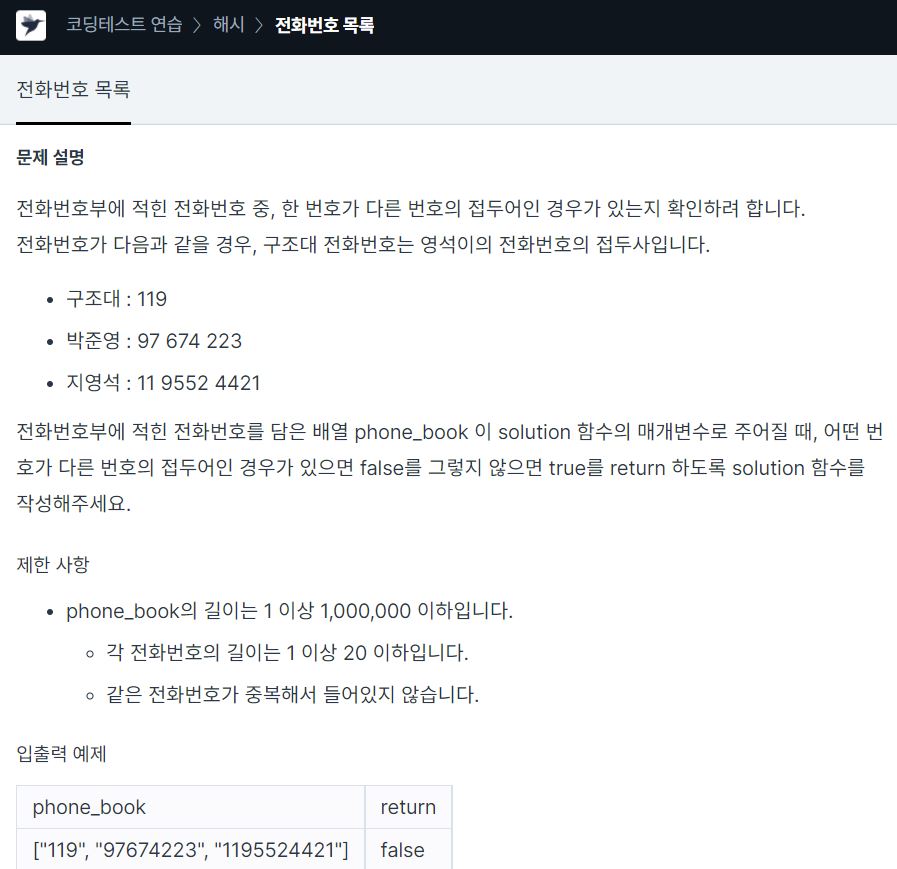
먼저 hash로 구하는 방법 말고는phone_book을 sort()하고, 인접한 두 string을 비교하면 된다.예를 들면"119", "97674223", "1195524421" 이 있을 때 이것을 정렬하면"119", "1195524421", "97674223" 순으로
12.<Programmers> Hash_위장 c++
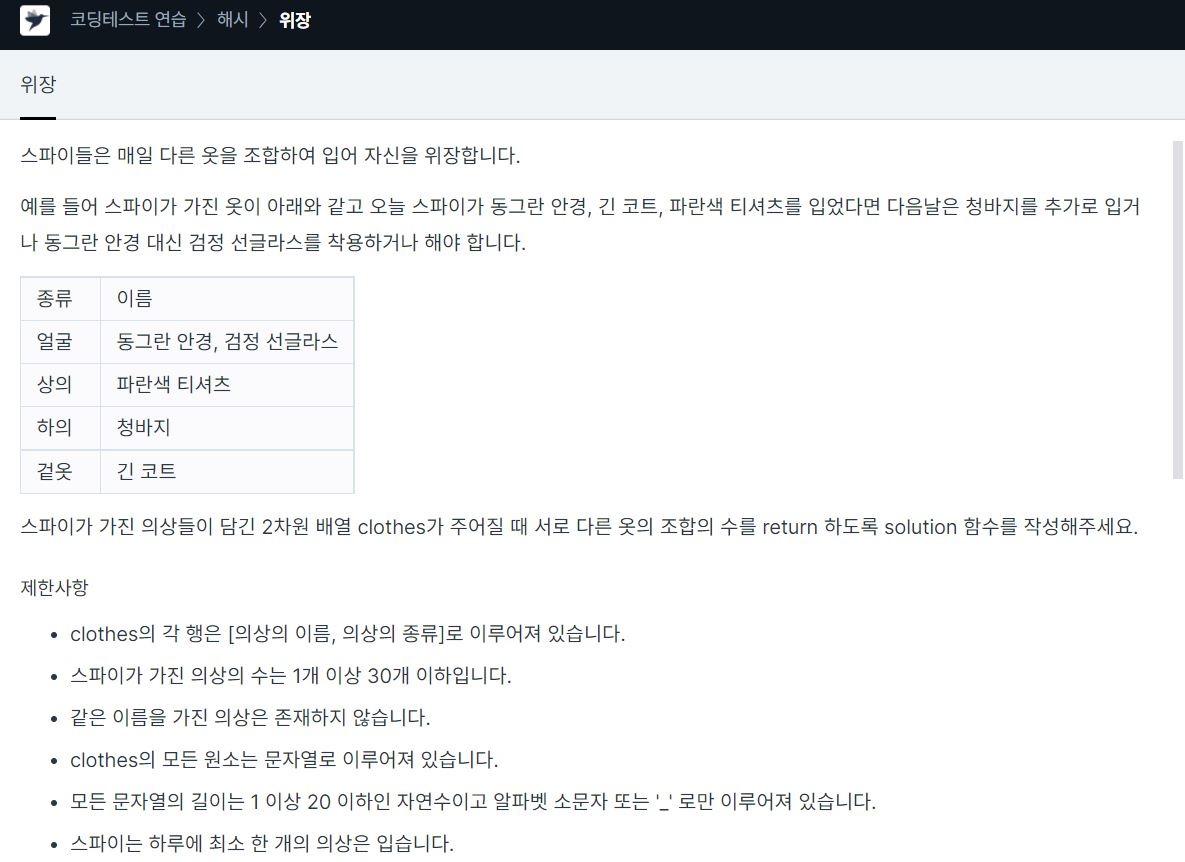
이 문제는 경우의 수만 제대로 알면 풀 수 있는 문제다예를 들어 스파이가 가지고 있는 의상의 종류의 개수가headgear=2, eyewear=3, face=4 이렇게 있을 때headgear 1번 선택, headgear 2번 선택, 선택하지 않음 총 3개가 있다그러니까
13.<Programmers> Dynamic Programming_N으로 표현 c++
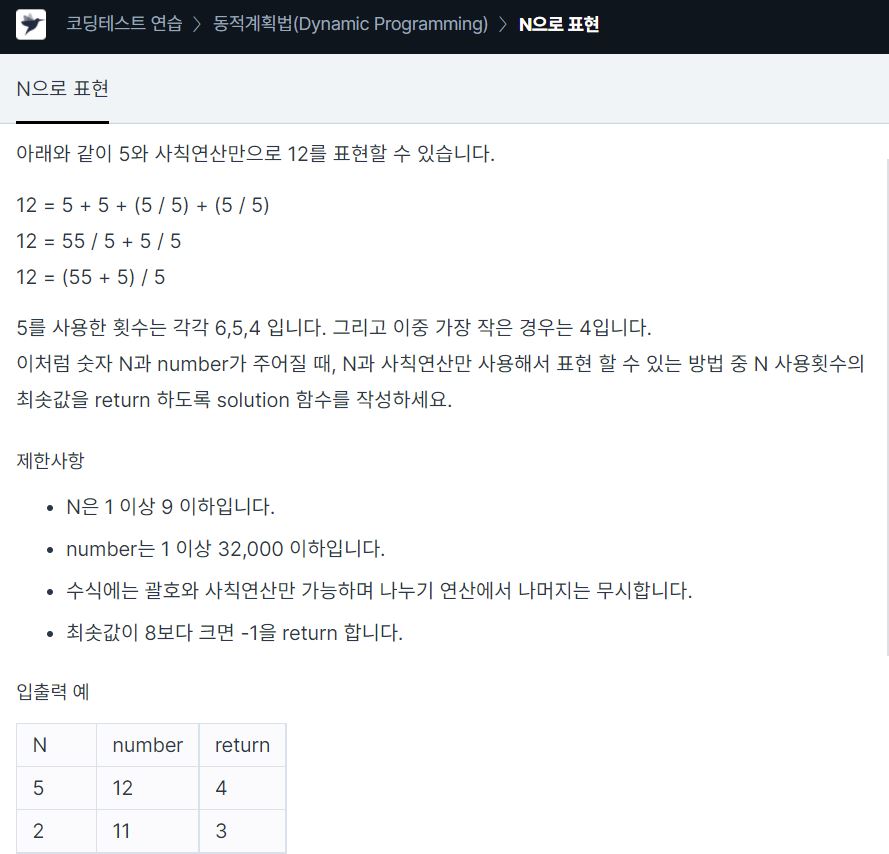
문제는 N과 number가 주어질 때 N과 사칙 연산만 사용해서 표현할 수 있는 방법 중 N 사용횟수의 최솟값을 구하는 문제이다. e.g. N=5, number=12인 경우12=5+5+(5/5)+(5/5) ->6개12=55/5+5/5 ->5개12=(55+5)/5 ->4
14.<Programmers> 문자열 압축 c++

문자열을 자르는 단위의 길이를 1개부터 문자열의 총 길이만큼을 기준으로 잘라본다 처음에 길이가 i인 단위가 되는 문자열을 temp에 저장하고 바로 뒤에 있는 문자열이 temp와 같으면 cnt를 증가시키고, 다르다면 string convert (새로 변환한 문자를 저장
15.<Programmers> Greedy_섬 연결하기 + MST, Kruskal Algorithm c++
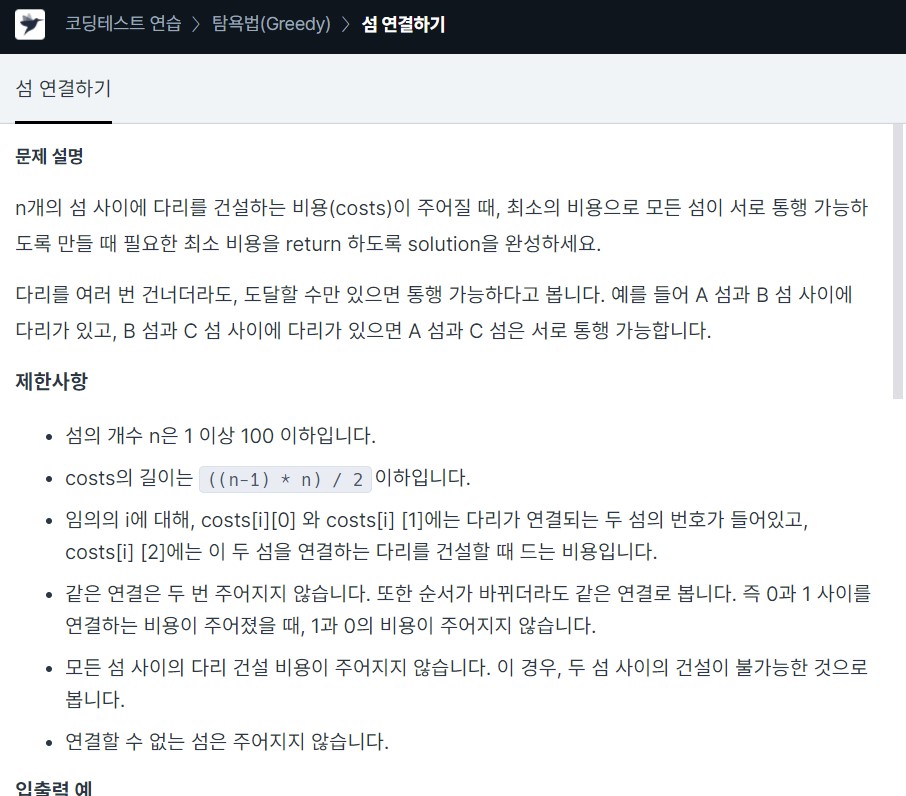
참고 Kruskal Minimum Spanning Tree Algorithm 모든 간선을 가중치의 오름차순으로 정렬 스패닝 트리에 하나씩 추가 가중치가 작다고 무조건 간선을 트리에 더하는 것이 아니라, 사이클이 생기지 않는 경우에만 트리에 더해준다 상호 배타적 집합
16.<Programmers>Binary Search_입국심사 c++
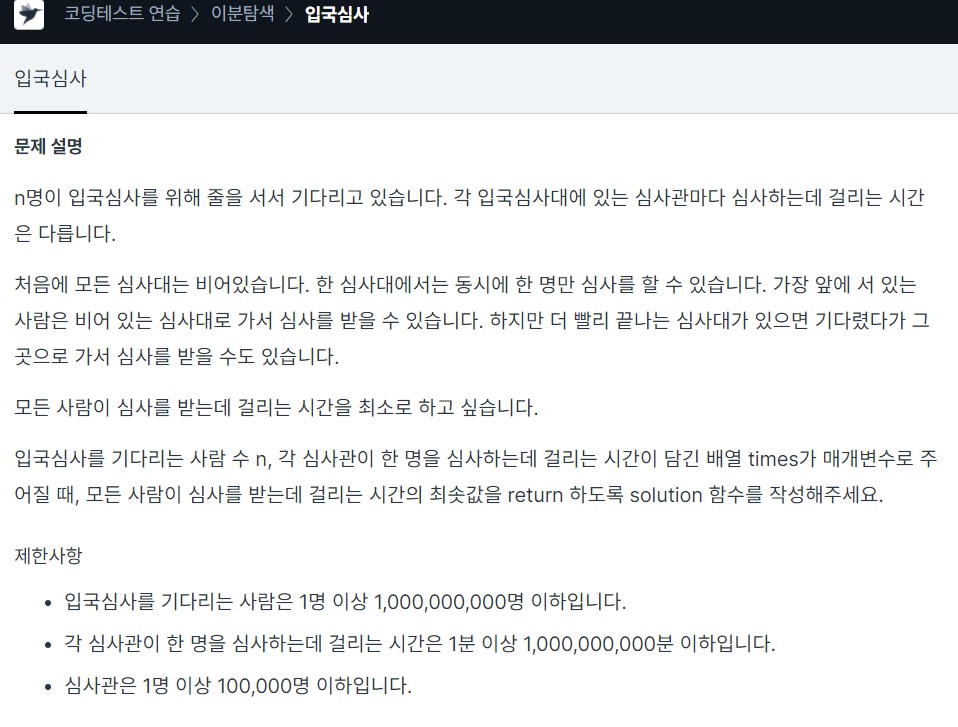
times에는 심사관 한 명이 심사하는데 걸리는 시간이 담겨있다입국 심사를 기다리는 사람은 n명이고, 범위는 1명이상 10^10이다모든 사람이 심사를 받는데 걸리는 시간의 최솟값을 return 해야 한다times에 저장된 값을 오름차순 정렬을 하면 심사관 한 명이 심사
17.<Programmers> 진법_124나라의 숫자

모든 수를 1,2,4만을 사용해서 표현모든 수를 0,1,2,3,4,5,6,7,8,9 = 총 10개로 표현하는 숫자를 10진법이라 한다. 여기서 아이디어를 얻어 1,2,4,만을 사용해 표현하는 숫자를 3진법이라고 생각한다숫자 n을 3으로 나누어 나머지가 0이면 4, 1이
18.<Programmers> Lv2 유클리드 호제법, GCD, LCM_멀쩡한 사각형 c++
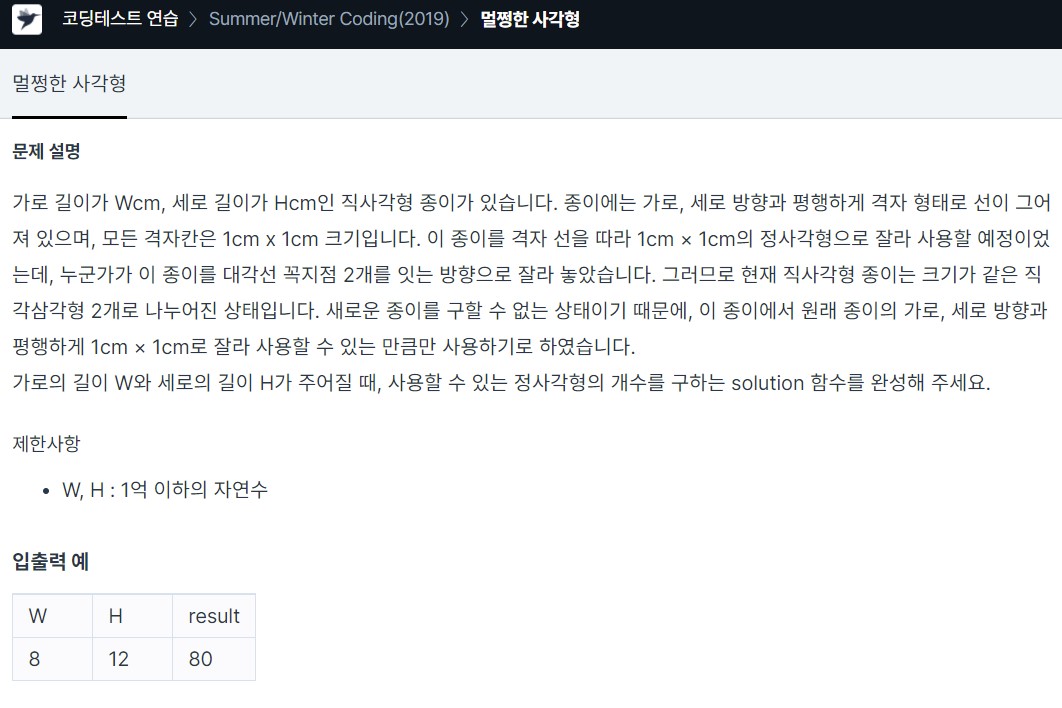
참고- 유클리드 호제법
19.<Programmers> Graph, Floyd Warshall_순위 c++
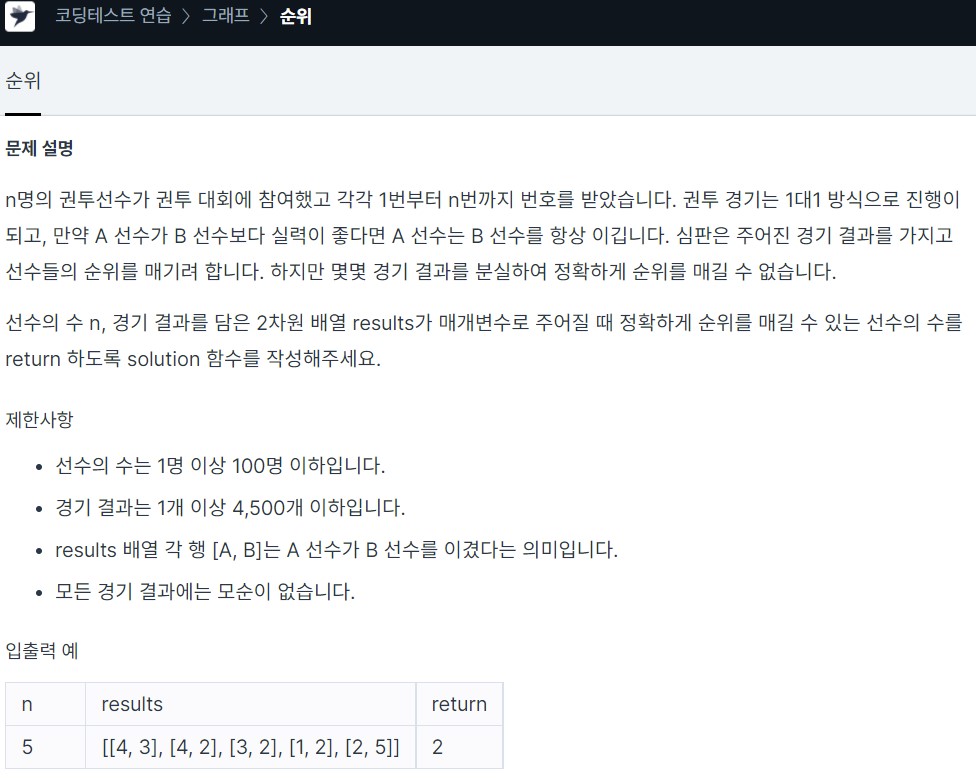
Lv3. 순위result 배열 각 행 \[a,b]는 a가 b를 이겼다는 의미이다처음 각 선수간 순위가 있으니 위상정렬(Topological Sort)로 구현해야 하나 생각을 했다 (indegree와 outdegree의 차수를 더한 값이 n-1이 되면 모든 선수들과 관계
20.<Programmers> Graph, BFS_가장 먼 노드 c++
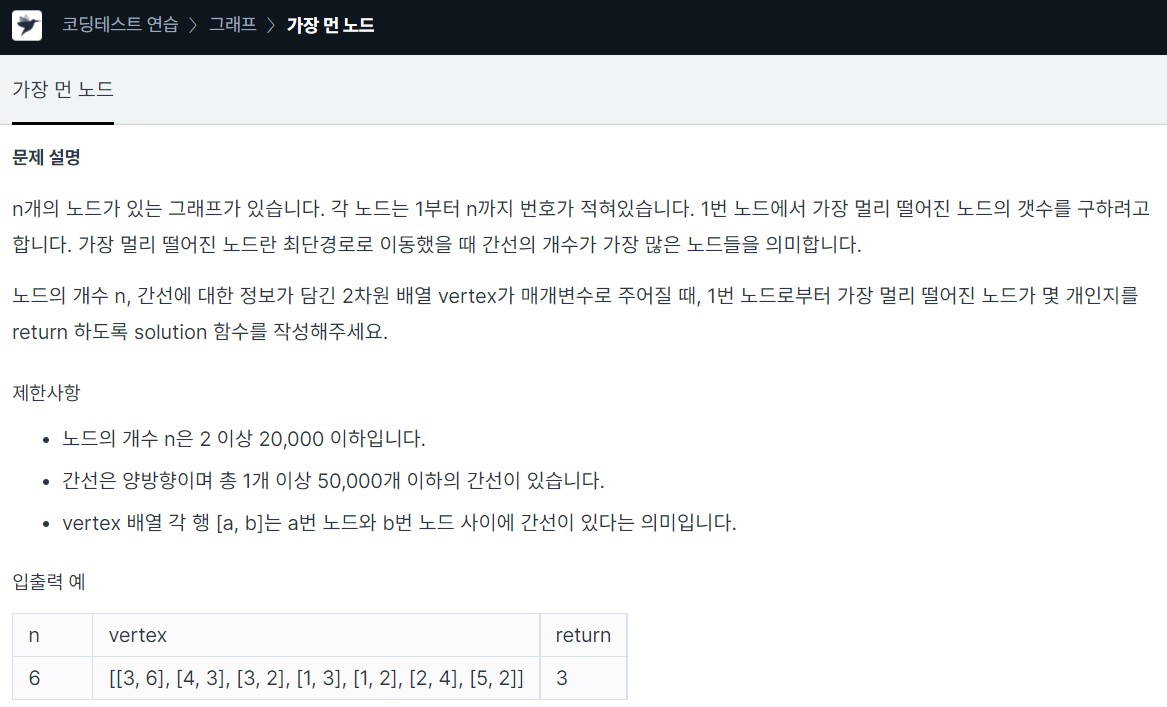
Lv3. 가장 먼 노드주어진 양방향 간선을 인접 리스트 그래프로 만들어 준다시작 정점 1에서부터 인접한 노드들 중 방문하지 않은 정점들을 queue에 넣어주며 bfs로 탐색한다해당 정점의 방문 거리는 이전 정점의 방문 거리+1 이다양방향 인접 리스트 만들기(어차피 di
21.<Programmers> Lv2. String, Stack_짝지어 제거하기 c++
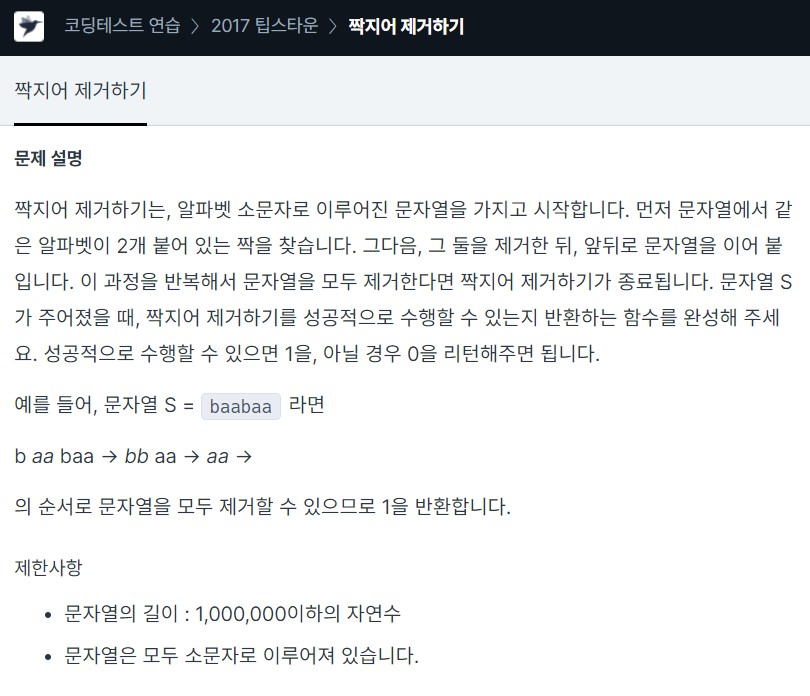
탐색하다가 2개가 겹쳐서 나오는 부분이 있으면 해당 부분을 '\_'으로 만들어주고 다시 처음부터 순회하는 방법을 사용했다문자열의 길이는 최대 1,000,000이므로 O(N^2)의 시간 복잡도를 가지므로 최대 1,000,000 X 1,000,000 의 시간 복잡도를 가지
22.<Programmers> 무지의 먹방 라이브_Priority Queue java
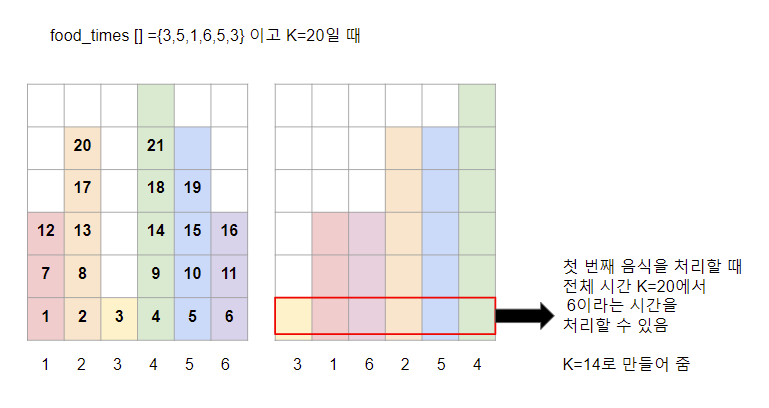
문제 : 무지의 먹방 라이브이 문제는 효율성 테스트를 따질 때, 방송시간(K) 값이 최대 2 X 10^3 이고, food_times의 길이는 최대 200,000, food_times의 각 원소는 최대 1,000,000,000 이므로 일반 배열을 순회하면서 풀었을 때 최