🏷️Retrievers
RAG(Retrieval Augumented Generation)에서 검색도구 (Retrievers)는 벡터 저장소에서 문서를 검색하는 도구이다. LangChain은 간단한 의미 검색 도구부터 성능 향상을 위해 고려된 다양한 검색 알고리즘을 지원한다.
🔺VectorStore-backed Retriever
대량의 텍스트 데이터에서 관련 정보를 효율적으로 검색하는 가장 기본적인 방법이다.
vector store에 구현된 유사도 검색이나 MMR과 같은 검색 메서드를 사용하여 vector store내의 텍스트를 쿼리한다.
Max Marginal Relevance (MMR)
MMR방식은 쿼리에 대한 관련 항목을 검색할 때 검색된 문서의 중복을 피하는 방법 중 하나로, 단순히 가장 관련성 높은 항목들만 검색하는 대신, 쿼리에 대한 문서의 관련성과 이미 선택된 문서들과의 차별성을 동시에 고려한다.
🔺Multi-Query Retriever
Vector Store Retriever의 한계를 극복하기 위해 고안된 방법으로, 단일 쿼리의 의미를 다양한 관점으로 확장하여 멀티 쿼리를 자동 생성하고, 이러한 모든 쿼리에 대한 검색 결과를 결합하여 처리한다.
즉, 사용자의 질문을 여러 개의 유사 질문으로 재생성해서 결과를 얻는 방법이다.
from langchain.retrievers.multi_query import MultiQueryRetriever
question = '카카오뱅크의 최근 영업실적을 알려줘.'
llm = ChatOpenAI(
model='gpt-3.5-turbo-0125',
temperature=0,
max_tokens=500,
)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(), llm=llm
)
# Set logging for the queries
import logging
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
unique_docs = retriever_from_llm.get_relevant_documents(query=question)
len(unique_docs)위에서 로깅 설정을 통해 MultiQueryRetriever에 의해 생성되고 실행되는 쿼리들에 대한 정보를 로그로 기록하고 확인할 수 있다.
NFO:langchain.retrievers.multi_query:Generated queries: ['1. 카카오뱅크의 최근 실적은 무엇인가요?', '2. 카카오뱅크의 최근 영업 성과에 대해 알고 싶어요.', '3. 카카오뱅크의 최근 경영 성과를 알려주세요.']
8🔺Self Querying Retriever
metadata를 이용해서 필터링해서 정보를 반환해주는 방식이다.
우선 metadata를 기반으로 유사도 검색이 가능한 벡터 저장소를 구축한다.
아래와 같이 metadata를 year, category, user_rating로 하고, 문서 내용을 작성해서 벡터 저장소를 구축한다.
docs = [
Document(
page_content="수분 가득한 히알루론산 세럼으로 피부 속 깊은 곳까지 수분을 공급합니다.",
metadata={"year": 2024, "category": "스킨케어", "user_rating": 4.7},
),
Document(
page_content="24시간 지속되는 매트한 피니시의 파운데이션, 모공을 커버하고 자연스러운 피부 표현이 가능합니다.",
metadata={"year": 2023, "category": "메이크업", "user_rating": 4.5},
),
Document(
page_content="식물성 성분으로 만든 저자극 클렌징 오일, 메이크업과 노폐물을 부드럽게 제거합니다.",
metadata={"year": 2023, "category": "클렌징", "user_rating": 4.8},
),metadata의 필드와 문서 내용에 대해 간단한 설명을 미리 제공해야 한다.
category, year, user_rating 각각이 의미하는 바가 무엇인지, 어떤 데이터 타입을 가지는지 명시한다.
metadata_field_info = [
AttributeInfo(
name="category",
description="The category of the cosmetic product. One of ['스킨케어', '메이크업', '클렌징', '선케어']",
type="string",
),
AttributeInfo(
name="year",
description="The year the cosmetic product was released",
type="integer",
),
AttributeInfo(
name="user_rating",
description="A user rating for the cosmetic product, ranging from 1 to 5",
type="float",
),
]SelfQueryRetriever.from_llm() 메서드를 사용하여 retriever 객체를 생성한다.
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# SelfQueryRetriever 생성
retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vectorstore,
document_contents="Brief summary of a cosmetic product",
metadata_field_info=metadata_field_info,
)마지막으로 metadata를 이용하여 필터를 걸 수 있는 질의를 입력하여 검색을 수행한다.
retriever.invoke("평점이 4.8 이상인 제품을 추천해주세요")
retriever.invoke("2023년에 출시된 상품을 추천해주세요")
retriever.invoke("카테고리가 선케어인 상품을 추천해주세요")
retriever.invoke(
"카테고리가 메이크업인 상품 중에서 평점이 4.5 이상인 상품을 추천해주세요"
)
...🔺Time Weighted Vector Retriever
가장 최근에 이용된 문서를 기준으로 먼저 참고하도록 하여 답변의 Freshness를 유지할 수 있다.
Socring Algorithm
semantic_similarity: 문서 또는 데이터 간의 의미적 유사도decay_rate: 시간이 지남에 따라 점수가 얼마나 감소하는지 나타내는 비율hours_passed: 객체가 마지막으로 접근된 후부터 현재까지 경과한 시간을 의미
위 방식을 통해 자주 접근되는 객체는 시간이 지나도 높은 점수를 유지하며, 이를 통해 자주 사용되거나 중요하게 여겨지는 정보가 검색 결과 상위에 위치할 가능성이 높아진다.
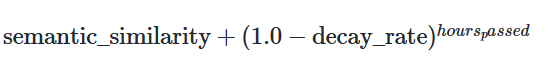
Reference
