Process
프로세스 : 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램IPC(Inter-Process Communication) : 프로세스 간 통신, 프로세스들 사이에 서로 데이터를 주고받는 행위
-> 프로세스들이 공유하는 메모리가 필요하다.
스레드 간 통신보다 프로세스 간 통신이 어려운 이유
- 프로세스는 생성되면서 PC를 포함하여 메모리 공간 등을 복사하여 별도의 자원을 할당하지만, 스레드는 메모리 공간과 자원을 공유한다.
- 따라서 프로세스는 통신할 수 있는 공간이 없기 때문에 통신을 위한 별도의 공간을 만들어주어야 하므로 스레드 간 통신보다 어렵다.
IPC의 종류
1. 파이프 (PIPE)

- 익명의 PIPE를 통해서 동일한 PPID를 가진 프로세스들 간에 단방향 통신을 지원한다.
- FIFO(선입선출) 구조
- 한쪽 방향으로만 통신이 가능한 파이프의 특징 때문에 반이중(Half-Duplex) 통신이라고 부르기도 합니다.
- 생성된 PIPE에 대하여 Write 또는 Read만 가능하다.
-> 읽기와 쓰기, 송/수신을 모두 하기 원한다면 두 개의 파이프를 만들어야만 가능하다.
2. Named PIPE

- 이름을 가진 PIPE를 통해서 프로세스들 간에 단방향 통신을 지원한다. -> 연관이 전혀 없는 프로세스간에 통신을 할 때 사용
- 서로 다른 프로세스들이 PIPE의 이름만 알면 통신이 가능하다.
- FIFO 구조
- 생성된 PIPE에 대하여 Write 또는 Read만 가능하다.
-> 전이중 통신을 위해서는 익명 파이프처럼 2개를 만들어야 가능하다.
3. Message Queue
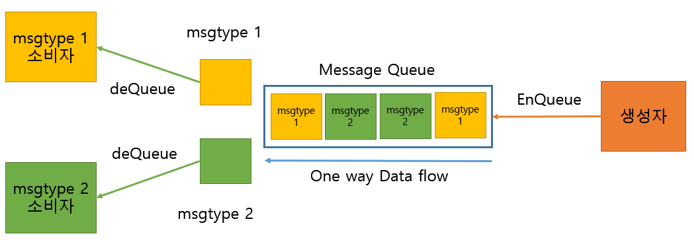
- 메모리를 사용한 PIPE이다. (Named PIPE가 데이터의 흐름이라면 메시지 큐는 메모리 공간이다.)
- 구조체 기반으로 통신을 한다.
- FIFO 구조
- 프로세스간 다양한 통신을 할 때 사용할 수 있다.
4. Shared Memory
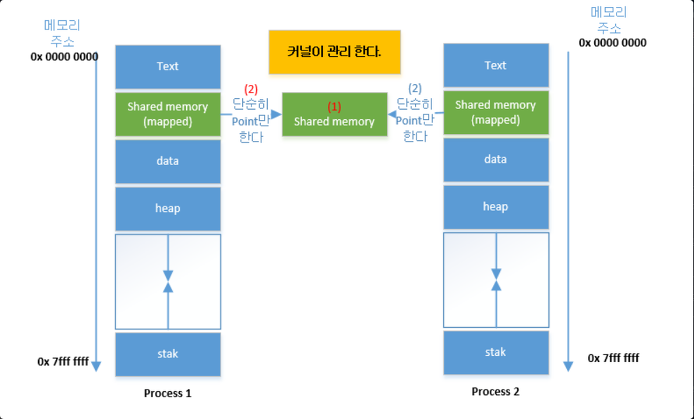
- 시스템 상의 공유 메모리를 통해 통신한다.
- 일정한 크기의 메모리를 프로세스간에 공유하는 구조
- 공유 메모리는 커널에서 관리된다.
- 프로세스간 Read, Write를 모두 필요로 할때 사용한다.
- 대량의 정보를 다수의 프로세스에게 배포 가능하다.
- 중개자 없이 곧바로 메모리에 접근할 수 있기 때문에 모든 IPC 중에서 가장 빠르게 작동할 수 있다.
5. Memory Map
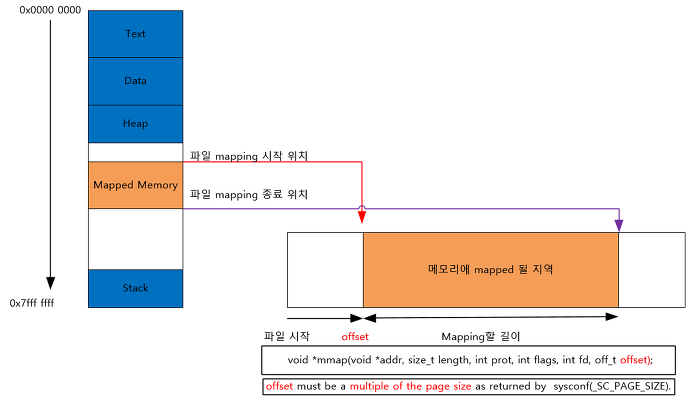
- 파일을 프로세스의 메모리에 일정 부분 맵핑 해서 사용한다.
- 공유메모리와 마찬가지로 메모리를 공유한다는 공통점이 있습니다.
- 차이점은 열린파일을 메모리에 맵핑시켜서 공유합니다.
-> 공유 매개체가 파일+메모리
- 파일로 대용량 데이터를 공유해야 할 때 사용합니다.
- 메모리 맵 파일은 파일의 크기를 바꿀 수는 없으며 메모리 맵 파일을 사용하기 이전, 또는 이후에만 파일의 크기를 바꿀 수 있다.
6. Socket
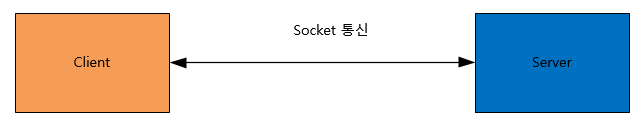
- 네트워크 소켓통신을 사용한 데이터 공유입니다.
- 클라이언트와 서버가 소켓을 통해서 통신하는 구조로, 원격에서 프로세스 간 데이터를 공유할 때 사용한다.
- 전이중(Full Duplex, 양방향) 통신이 가능한다.
- 중대형 애플리케이션에서 주로 사용한다.
7. Semaphore
- 다른 IPC설비들이 대부분 프로세스간 메시지 전송을 목적으로 하는데 반해, 세마포어는 프로세스 간 데이터를 동기화 하고 보호하는데 그 목적을 두게 됩니다.
from multiprocessing import Process, Queue
import time
def worker(id, number, q):
increased_number = 0
for i in range(number):
increased_number += 1
q.put(increased_number)
return
if __name__ == "__main__":
start_time = time.time()
q = Queue()
th1 = Process(target=worker, args=(1, 50000000, q))
th2 = Process(target=worker, args=(2, 50000000, q))
th1.start()
th2.start()
th1.join()
th2.join()
print("--- %s seconds ---" % (time.time() - start_time))
q.put('exit')
total = 0
while True:
tmp = q.get()
if tmp == 'exit':
break
else:
total += tmp
print("total_number=",end=""), print(total)
print("end of main")
from multiprocessing import Process, shared_memory, Semaphore
import numpy as np
import time
def func(id, number, new_array, shm, sem):
increased_number = 0
for i in range(number):
increased_number += 1
sem.acquire()
ex_shm = shared_memory.SharedMemory(name=shm)
b = np.ndarray(new_array.shape, dtype=new_array.dtype, buffer=ex_shm.buf)
b[0] += increased_number
sem.release()
if __name__ == "__main__":
start_time = time.time()
sem = Semaphore(1)
new_array = np.array([0])
shm = shared_memory.SharedMemory(create=True, size=new_array.nbytes)
c = np.ndarray(new_array.shape, dtype=new_array.dtype, buffer=shm.buf)
th1 = Process(target=func, args=(1, 50000000, new_array, shm.name, sem))
th2 = Process(target=func, args=(2, 50000000, new_array, shm.name, sem))
th1.start()
th2.start()
th1.join()
th2.join()
print("---%s seconds ---" % (time.time() - start_time))
print("total_number=", end=""), print(c[0])
print("end of main")
shm.close()
shm.unlink()
