[논문 리뷰] Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation
논문
Introduction
- Vision-and-Language Navigation(VLN)은 agent가 language instruction에 따라 unseen environment에서 목적지로 도착하기 위한 task이다
- 초기에는 step-by-step guidance로 세부적인 지시사항을 순차적으로 주는 방향의 연구들이 있었으나 이는 실용적이지는 못했다.
- 따라서, goal-oriented instructions에 대한 연구가 이루어졌고 agent가 이미 수행한 지시사항과 방문한 위치에 대한 memory를 담기 위해 recurrent architecture를 사용하였다.
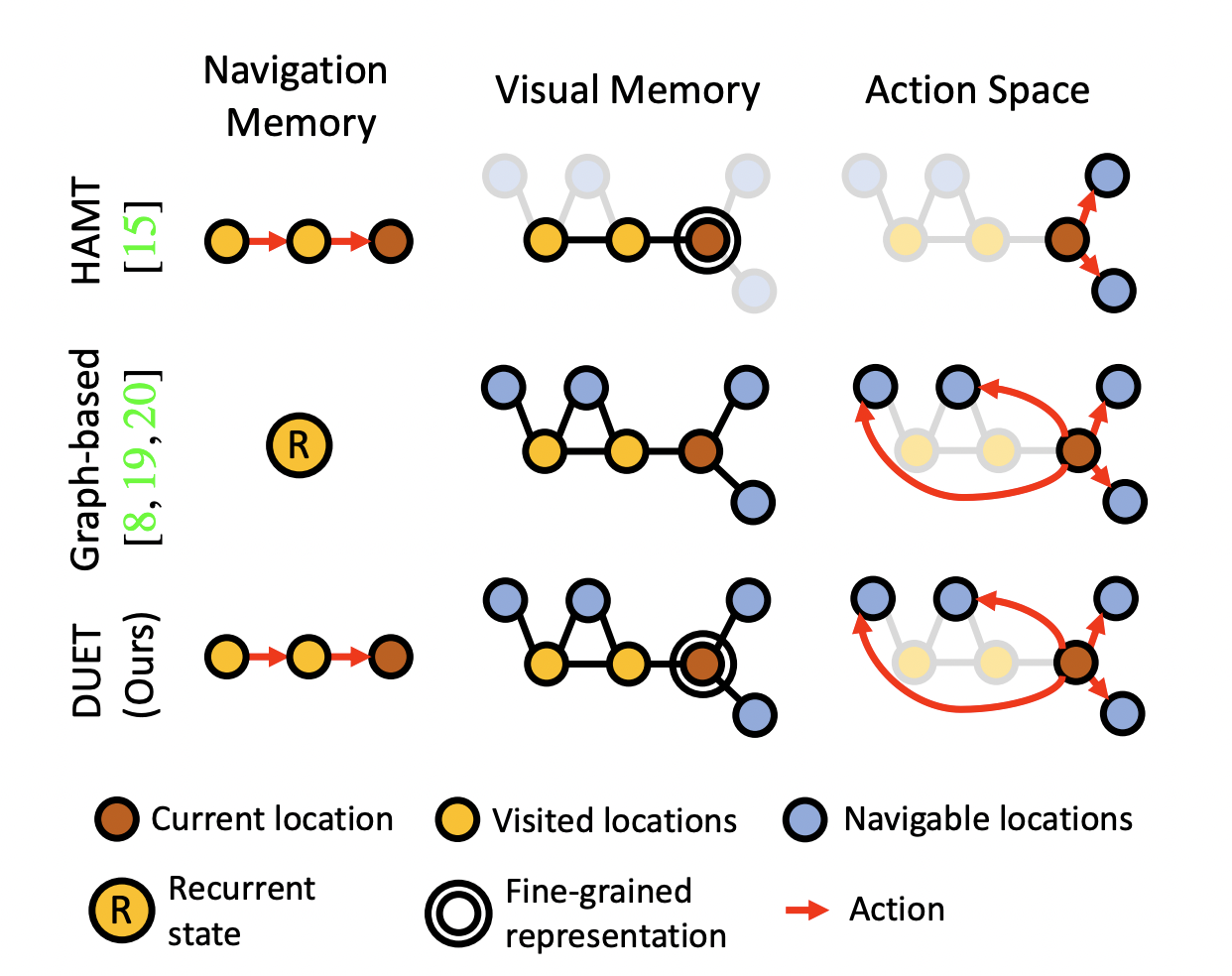
- 하지만, rich space-time structure에서 implicit memory mechanism은 비효율적이기 때문에 최근에는 memory를 explicit하게 저장하는 연구가 진행되었으나 local action에 대해서만 적용 가능해 모델을 N번 돌려야 한다는 단점이 있다.
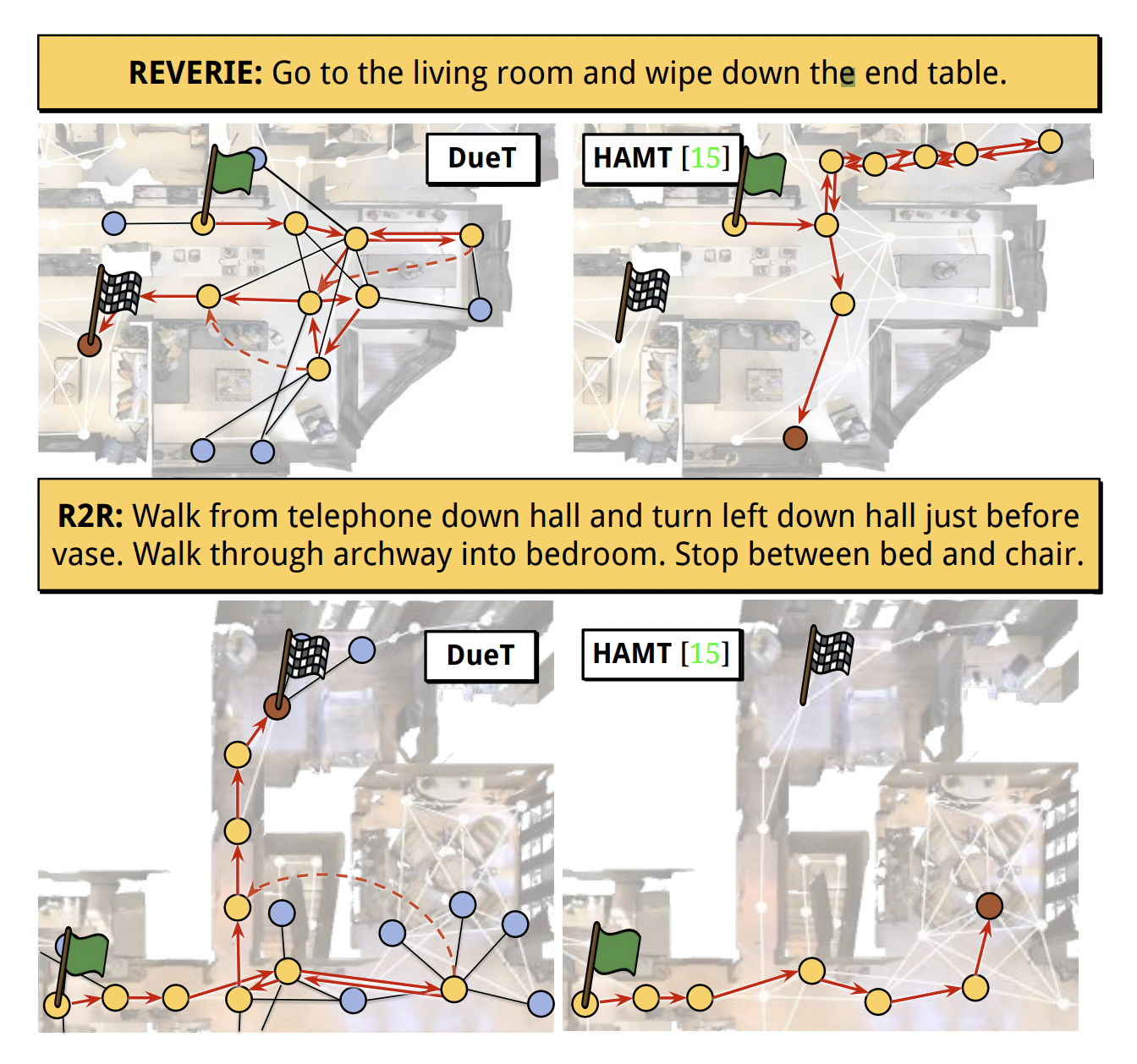
- 이를 보완하기 위한 방법으로는 방문한 곳과 navigable locations observed를 explicit하게 기록한 topological map을 만드는 방식이 있다.
- 하지만 이 또한 long-term reasoning에 취약하고 각 노드에 condensed visual features가 담겨 디테일이 부족하다는 단점이 있다.
- 본 논문에서는 Transformer 구조와 dual-scale action planning을 활용해 위의 문제점을 해결한다.
Overview
- Agent는 RGB camera와 GPS sensor를 장착하고 있으며 지시사항에 따라 목적지에 도착해 object를 찾고자 한다.
- Environment은 undirected graph 로 구성되며는 개의 navigable nodes를, 는 edges를 의미한다.
- 은 개의 word로 구성된 instruction의 word embedding이다.
- 각 스텝 에서 agent는 현재 노드 의 panoramic view와 position coordinate를 받으며 panorama는 개의 image로 나뉘어 image feature vector 로 구성된 와 unique orientations로 표현된다.
- Fine-grained visual perception을 위해 panorama로부터 개의 object features 를 추출하며 agent는 neighbor nodes 의 일부 navigable view에 대한 정보도 가지고 있다.
- 스텝 에서의 possible local action space 는 로의 navigation과 에서 멈추는 것을 포함하며 agent가 멈출 위치를 결정한 후에는 target object의 위치를 예측한다.
- 본 논문의 모델은 topological map을 점진적으로 만들어내는 topological mapping module과 dual-scale reasoning을 수행하는 global action planning module로 구성된다.
Method
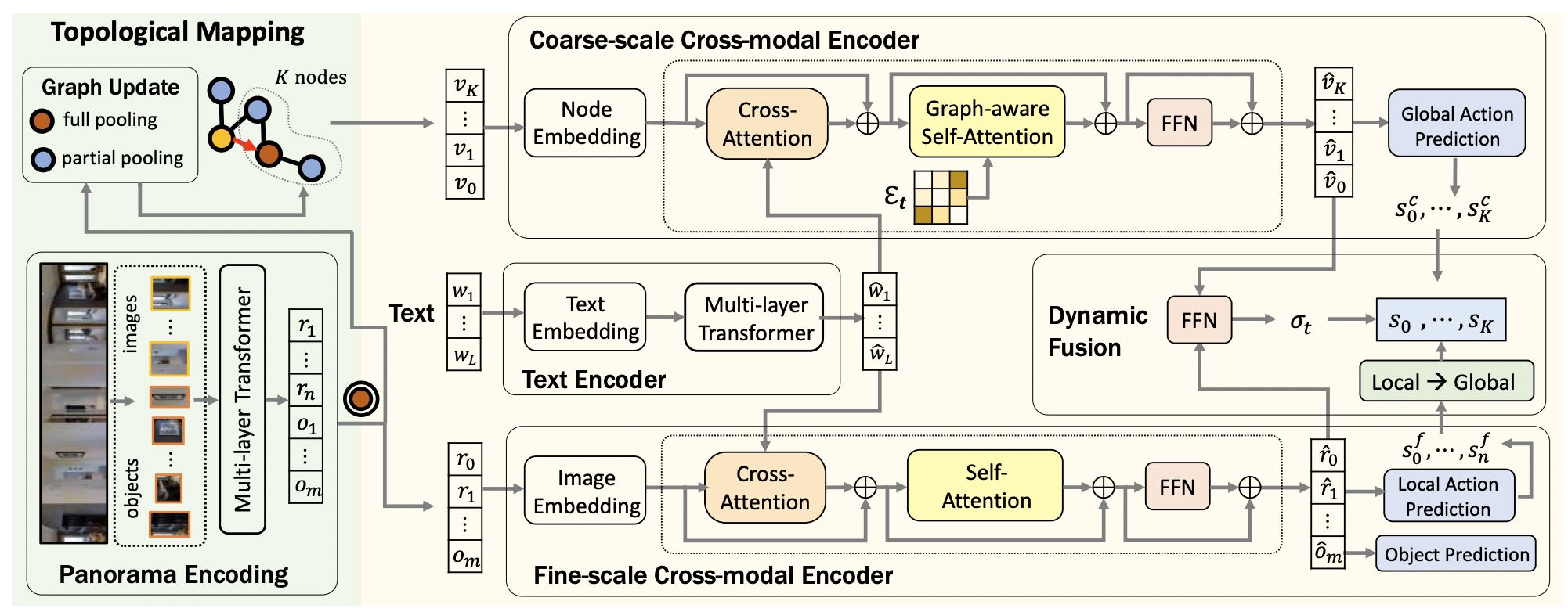
Topological Mapping
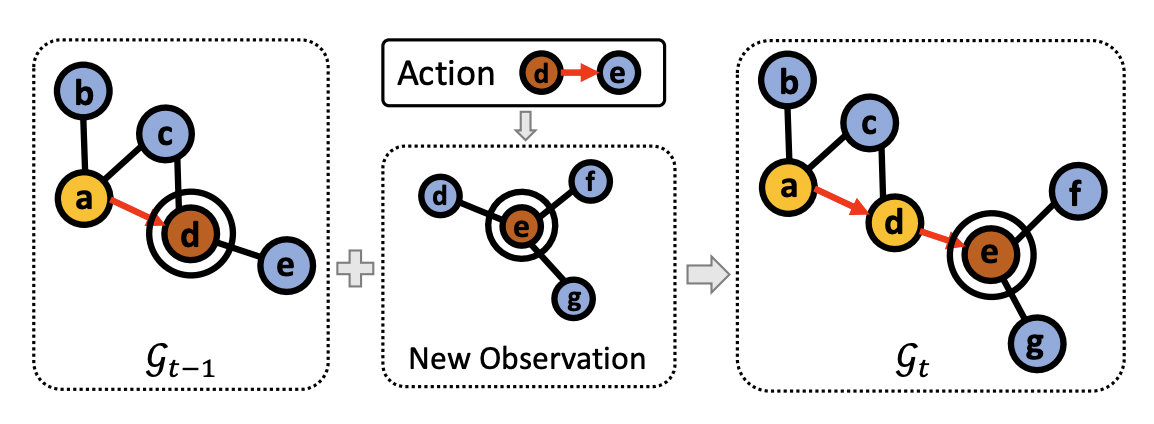
- Environment graph 는 visited nodes, navigable nodes, current node로 구성되며 agent는 visited nodes와 current node의 panoramic view에 대해서만 정보를 가진다.
- 각 스텝 에서 current node 와 neighboring unvisited nodes 가 추가되며 edge도 update 된다.
- 에서 새로운 observation이 주어지면 current node의 visual representations와 navigable nodes도 update 한다.
Visual representations for nodes
-
Time step 에서 agent는 의 image features 와 object featuers 를 받는다.
-
Multi-layer transformer를 통해 images와 objects 간의 spatial relations를 학습한다.
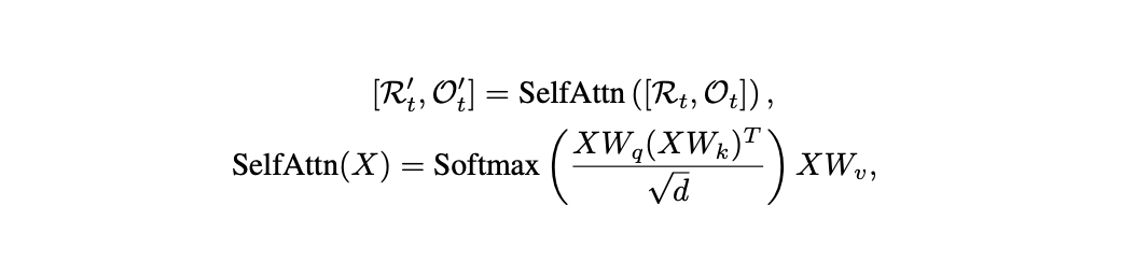
-
와 를 average pooling하여 current node의 visual representation을 update한다.
-
Navigable nodes는 다른 노드들에서 일부 관측된 모든 정보를 평균내서 담아준다.
-
이러한 coarse-scale representation은 large graph에서 효율적인 추론을 가능하게 하지만 object에 대한 fine-grained language grounding을 하기에는 정보가 부족하다.
-
따라서, 와 를 keep해두었다가 fine-scale에서의 추론을 보조하는데 이용한다.
Global Action Planning
Text Encoder
- 의 word embedding은 positional embedding을 거친다.
- 모든 word token은 multi-layer transformer를 거치며 로 정의된다.
Coarse-scale Cross-modal Encoder
Coarse-scale map 와 encoded instruction 를 받아 global action space()에서의 navigation 예측을 한다.
Node embedding
- Node visual feature 에 location encoding과 navigation step encoding이 추가된다.
- Location encoding은 current node에 대한 상대 orientation과 distance를 임베딩하며 navigation step encoding은 visited nodes에 대해서는 방문한 time step을 unvisited nodes에 대해서는 0을 임베딩한다.
- Stop action을 정의하기 위해 'stop' node 을 추가하고 다른 모든 노드들과 연결한다.
Graph-aware cross-modal encoding
-
Encoded node와 word embeddings는 multi-layer graph-aware cross-model transformer를 통과한다.
-
각 layer는 nodes와 instructions의 관계를 학습하기 위한 cross-attention layer와 environment layout을 인코딩하는 graph-aware self-attention layer로 구성된다.
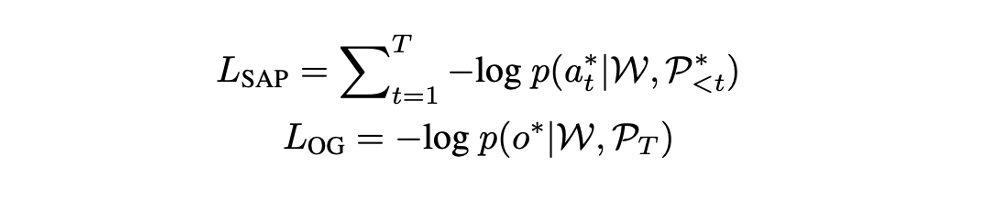
-
는 node representations, 는 pair-wise distance matrix로 visual 정보 뿐만 아니라 거리 관계까지 고려한 attention을 수행하게 된다.
Global action prediction
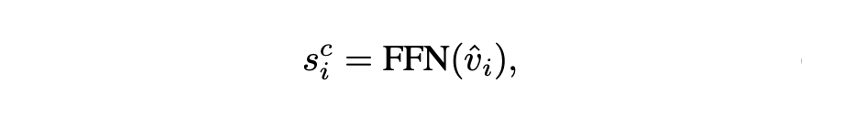
- 2개의 layer로 구성된 feed-forward network를 통해 각 노드 에 대한 navigation score를 구한다.
- 는 stop score이며 노드를 재방문할 필요가 없기 때문에 visited nodes는 마스킹 처리를 한다.
Fine-scale Cross-modal Encoder
Instruction 와 current node의 fine-grained visual representations 를 받아 local action space()에서의 navigation actions를 예측하고 object를 ground 한다.
Visual Embedding
- 두 종류의 location embedding을 에 추가한다.
- 첫번째 embedding은 start node에 대한 current location으로 "go to the living room in first floor"과 같이 absolute location에 대한 이해를 돕는다.
- 두번째 embedding은 각 neighboring nodes의 current node에 대한 상대적인 position으로 "turn right"와 같은 egocentric directions을 이해하는데 도움이 된다.
- 'stop' token 또한 추가된다.
Fine-grained cross-modal reasoning
- 를 concat하여 multi-layer cross-modal transformer의 visual token으로 받고 vision and language relations를 학습한다.
- Visual token의 output은 로 표기한다.
Local action prediction and object grounding
- Global action prediction과 동일하게 FFN을 거쳐 local action space 에서의 navigation score 를 예측한다.
- Object grounding을 object score 또한 구한다.
Dynamic Fusion
- Coarse-scale과 fine-scale을 fusion하기에 앞서 두 scale에서의 prediction이 매칭이 안되기 때문에 local action space 을 global action space로 변환한다.
- Current node와 연결되지 않은 곳을 탐색하기 위해서는 visited node를 거쳐야 하므로 neigbor가 아닌 노드를 예측할 경우에는 의 모든 visited nodes의 score의 합인 를 사용한다.
- 각 step에서 과 을 concat하여 funsion scalar로 사용하며 converted local action score 와 global action score 를 fusion 한다.
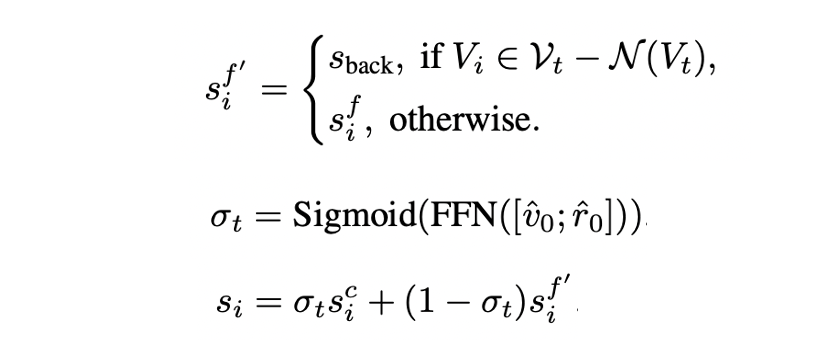
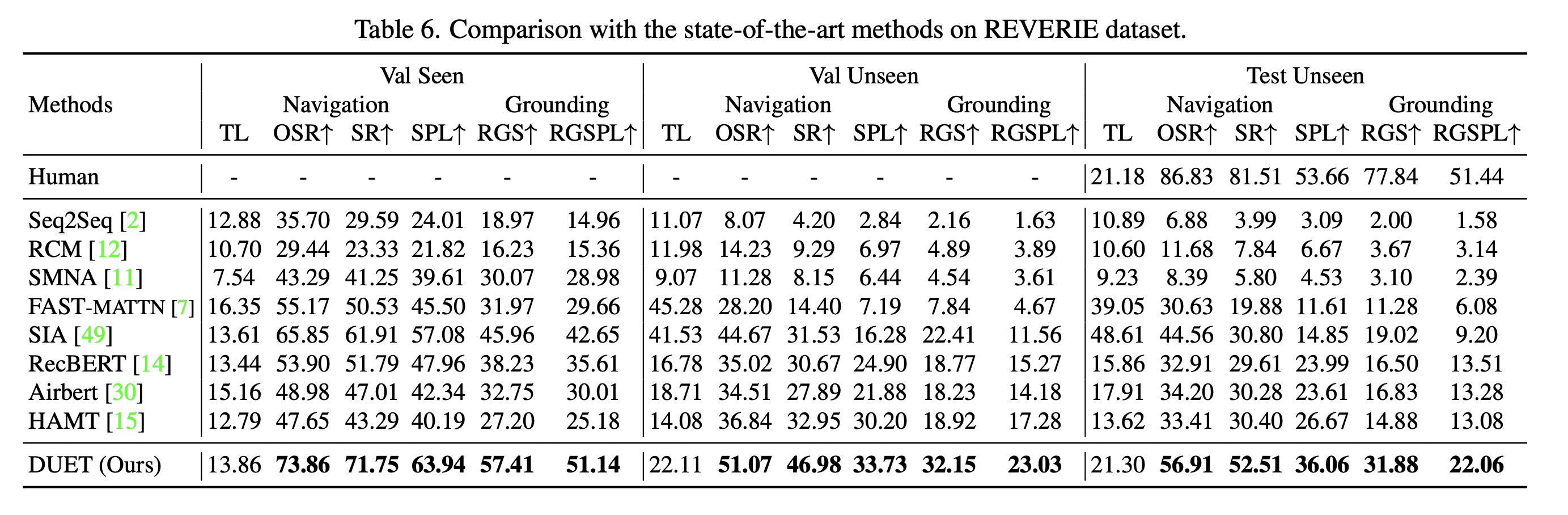
Experiments