[Point Review] PlaneRCNN: 3D Plane Detection and Reconstruction from a Single Image
0
Point Review
목록 보기
13/26
Introduction

- Single RGB 이미지로부터 3D plane reconstruction을 하는 것은 매우 어려운 문제로 많은 prior가 필요하며 texture가 부족한 부분을 추출하기 위해 global 정보를 활용해야 한다는 challenge가 있다.
- CNN을 활용한 PlaneNet, PlaneRecover 등이 해당 task를 풀어냈지만 다음과 같은 limitation이 존재한다.
- 면적이 작은 표면들을 잡아내지 못한다.
- Plane의 maximum 수를 요구한다.
- Domain에 일반화되지 못해 inddor에서 학습한 경우 outdoor에서 성능이 좋지 않다.
- PlaneRCNN은 3개의 components로 구성된 네트워크를 통해 위의 한계점들을 해결한다.
Approach
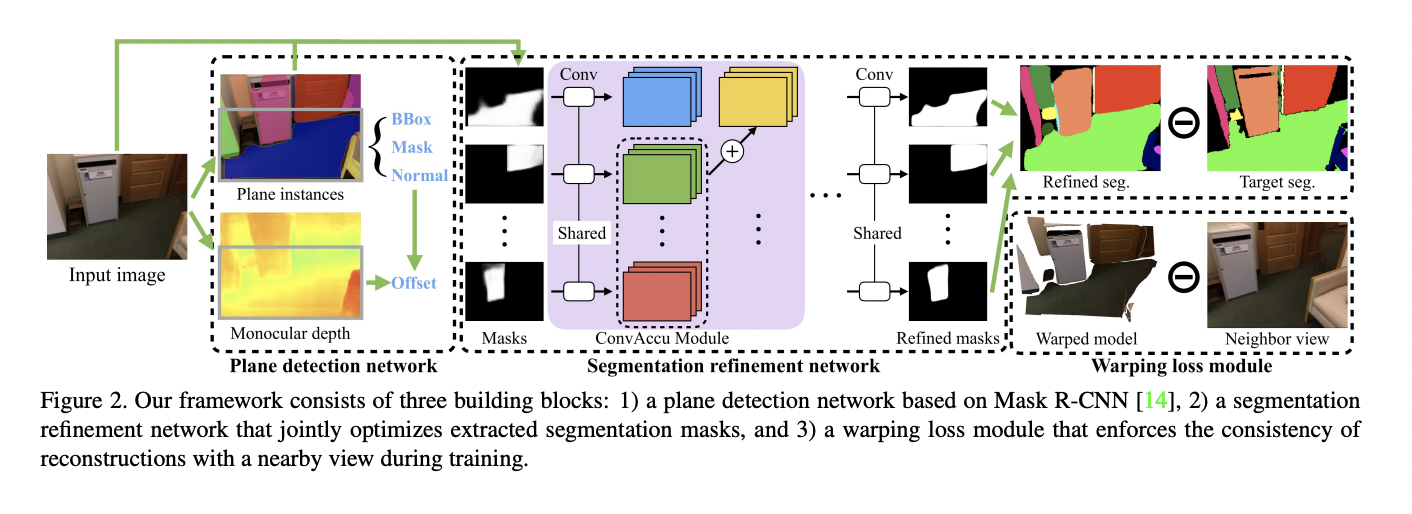
Plane Detection Network
Plane normal estimation
- Mask R-CNN을 베이스로 하며 "plane", "non-plane" 두 개의 category만으로 구분한다.
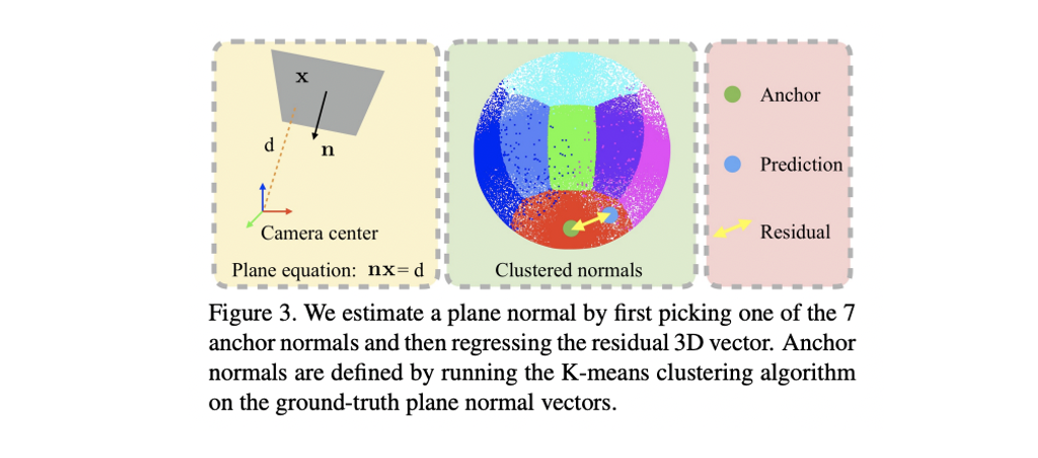
- Anchor normal는 training data에서 10,000개의 plane normal을 뽑아 로 kmeans clustering 했을 때 각 클러스터의 center이다.
- 각 plane 영역을 object instance로 보며 object category prediction에서 anchor ID를 예측한다.
- 추가적인 FC layer는 3D residual vector를 anchor normal에 대해 regression 한다.
Depth estimation
- Depth map을 추정하기 위해 MASK R-CNN의 FPN 뒤에 decoder를 붙인다.
Plane offset estimation
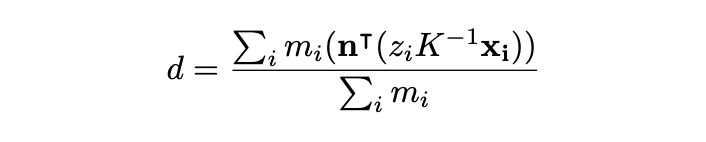
- plane normal 이 주어졌을 때 plane offset 의 위와 같이 추정한다.
- 는 camera intrinsic matrix, 는 번째 pixel coordinate, 는 predicted depth value, 는 pixel이 plane에 속하면 1인 indicator variable
Segmentation Refinement Network
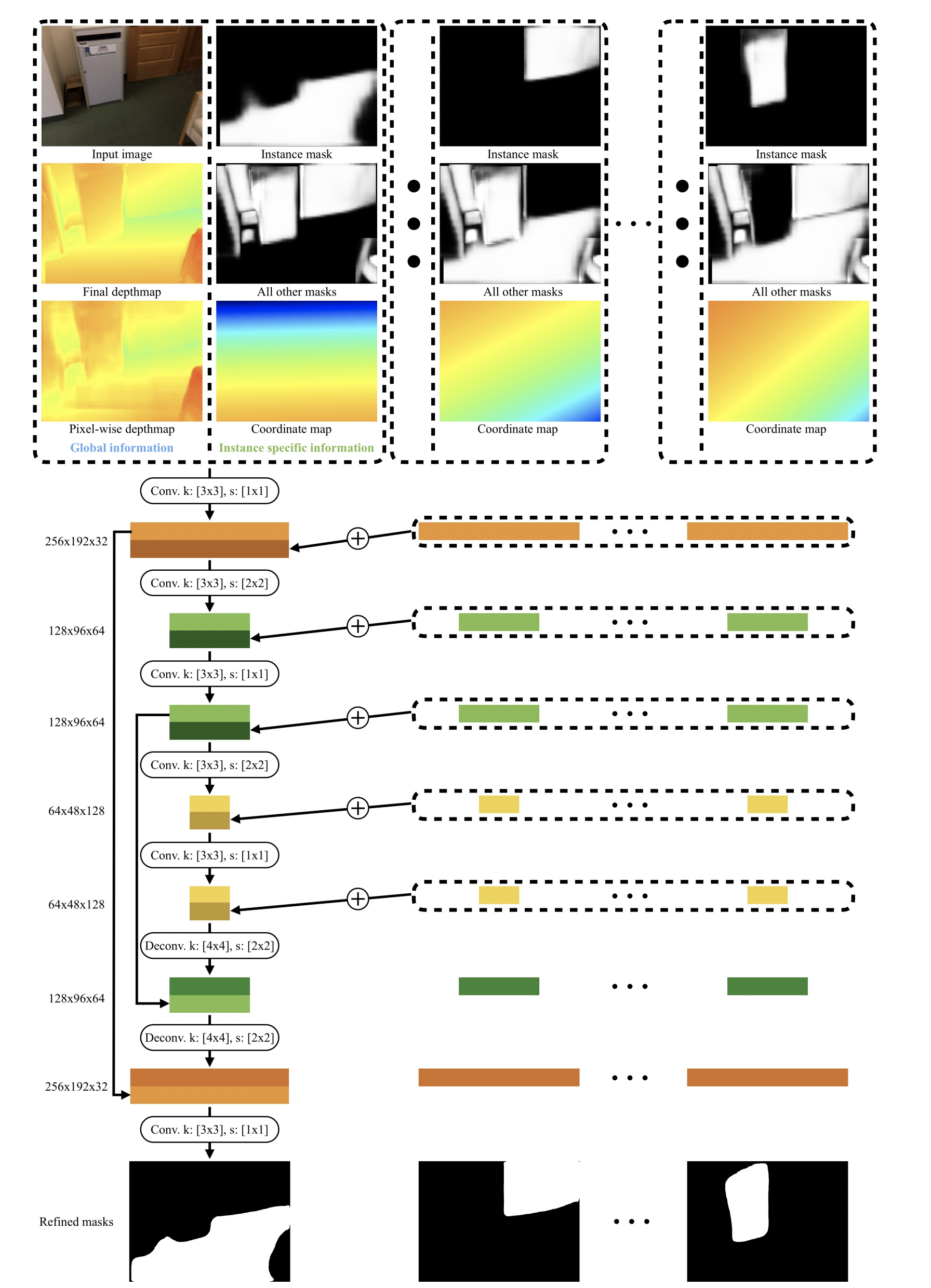
- ConvAccu를 통해 모든 mask들을 jointly optimize 한다.
Warping Loss Module
- Reconstruction된 3D plane과 nearby view의 consistency를 높여주는 역할
- Depth map을 3D coordinate map으로 변환시켜 현재 frame의 map을 , 주변 frame의 map을 이라 한다.
- 의 3D coordinate 들을 camera pose를 통해 nearby view로 투영시킨 후 과의 L2 norm을 loss로 활용한다.
Results

