1. Schema Registry
-
kafka는 byte 포맷으로 데이터를 전달합니다. 하지만 이러한 데이터를 보내고 받기만 할뿐 해당 데이터가 string인지, integer인지 알지 못하는데 이를 해결하기 위해 Kafka에서 Schema Registry는 데이터의 스키마를 중앙에서 관리하고 버전 관리를 할 수 있는 중요한 요소입니다.
-
Schema Registry를 사용하면 데이터가 스키마와 일치하는지 확인할 수 있으므로, 데이터의 일관성과 유효성을 유지할 수 있습니다. 스키마의 중앙 관리와 데이터 직렬화/역직렬화를 통해 데이터 호환성과 유연성을 제공하면서도 데이터 유효성 검사를 수행할 수 있습니다.
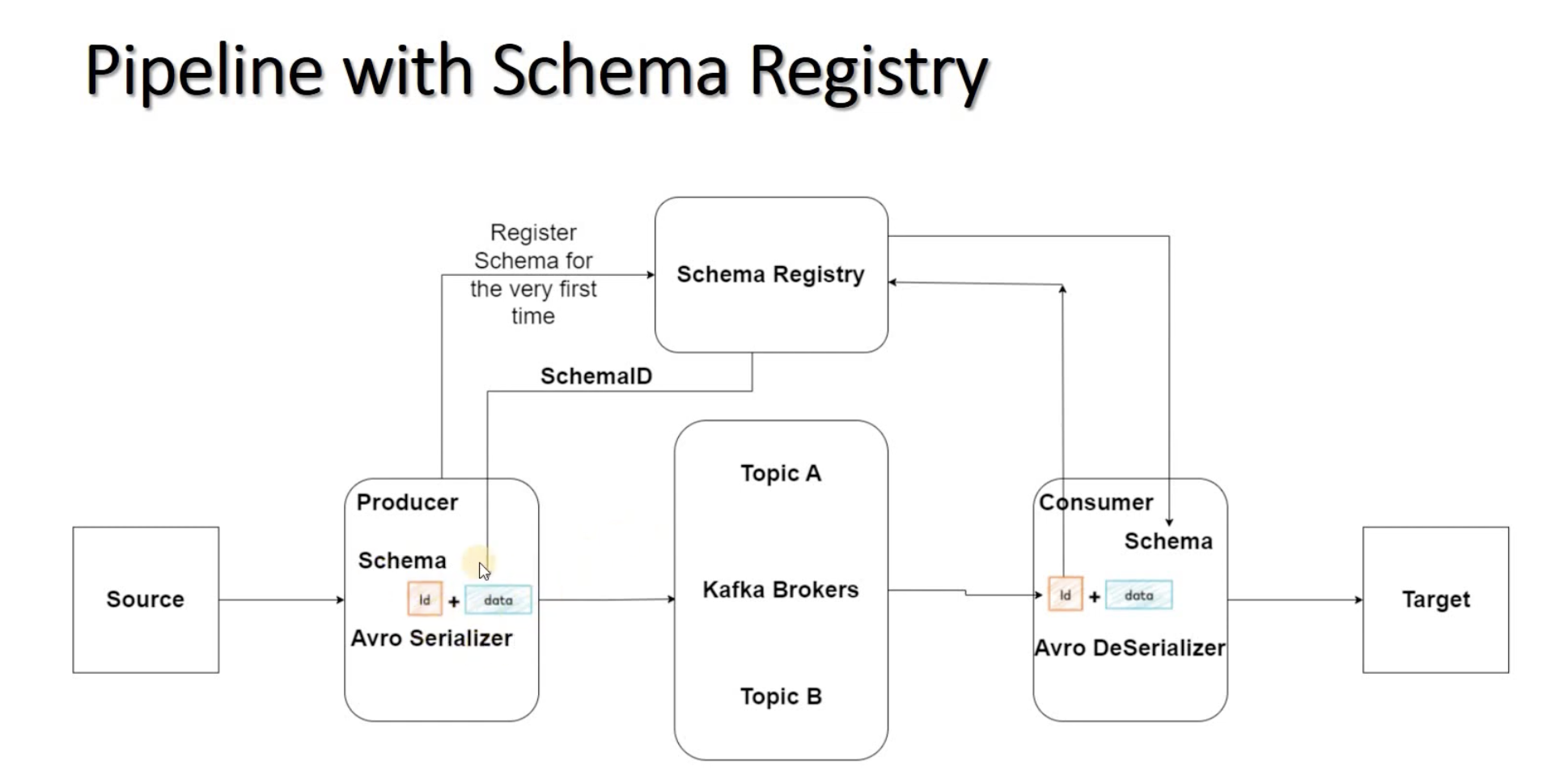
Schema Registry에 스키마를 등록할 때, 각 스키마는 고유한 Schema ID를 부여받습니다. Schema ID는 스키마의 버전 관리와 데이터 직렬화에서 중요한 역할을 합니다.
1) 스키마 버전 관리
: 각 스키마는 고유한 Schema ID를 가지고 있으며, 이를 통해 스키마의 버전 관리가 가능해집니다. 동일한 스키마를 여러 번 등록하더라도 Schema ID는 고정되어 유일하게 식별됩니다. 따라서 스키마가 변경될 때마다 새로운 버전의 스키마가 등록되고, 이전 버전의 스키마와 구분될 수 있습니다.
2) 데이터 직렬화와 역직렬화
: 프로듀서가 메시지를 직렬화할 때, 메시지에는 해당하는 스키마의 Schema ID가 포함됩니다. 컨슈머는 메시지를 역직렬화할 때 Schema ID를 사용하여 적절한 스키마를 식별하고, 메시지를 원래의 데이터 형식으로 변환합니다. 따라서 Schema ID를 사용하여 데이터의 일관성과 호환성을 유지할 수 있습니다.
요약하면, Schema ID는 스키마의 고유 식별자로서 버전 관리, 데이터 직렬화와 역직렬화, 스키마 호환성 관리 등에 사용됩니다. Schema ID를 통해 스키마를 효율적으로 관리하고 데이터 호환성을 유지할 수 있습니다.
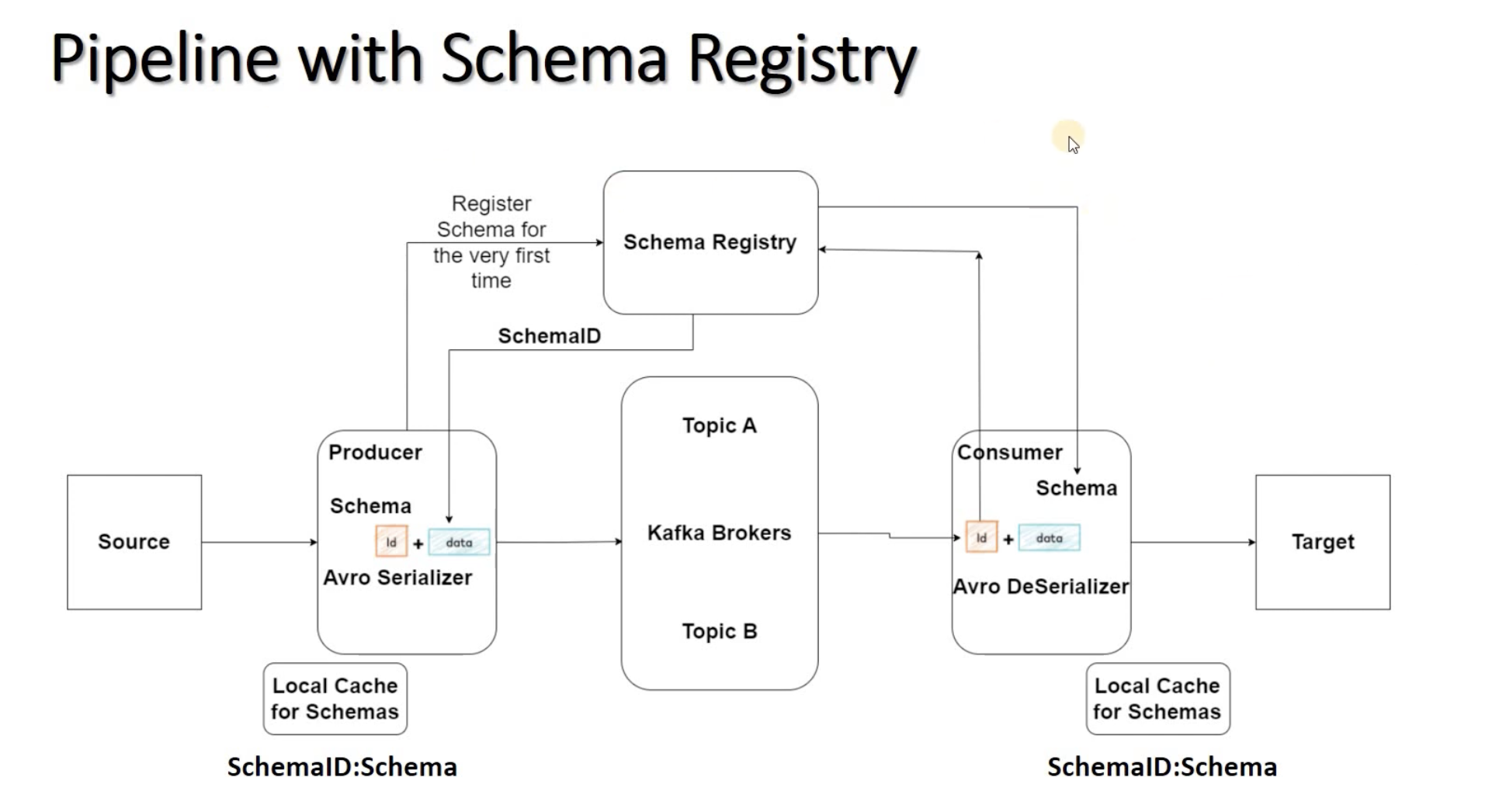
그러나 매번 producer와 consumer가 schema registry를 확인하는 작업은 지연을 초래하므로 local cahce에서 매핑되는 schema 및 schemaId를 찾아 해결할 수 있다.
로컬 캐시는 스키마 검색 속도를 향상시키고 네트워크 지연을 줄여 전반적인 성능을 향상시킵니다. 그러나 주의할 점은 로컬 캐시가 항상 최신 상태의 스키마를 보장하지는 않으며, 캐시 갱신 정책에 따라 일정 시간 동안은 이전 버전의 스키마를 반환할 수 있다는 점입니다.
2. Schema Evolution and Compatibility
Kafka에서 Schema Evolution은 스키마 변경에 따른 데이터 호환성을 관리하는 개념입니다. 이를 통해 이전 버전의 스키마와 새로운 버전의 스키마를 함께 사용하고 데이터의 호환성을 유지할 수 있습니다. Schema Registry를 사용하여 스키마를 등록하고 버전 관리를 할 수 있습니다.
Compatibility 예시
: 스키마의 Backward Compatibility를 유지한다면, 이전 버전의 메시지를 새로운 스키마로 업데이트하거나 새로운 스키마를 사용하여 이전 버전의 컨슈머가 성공적으로 처리할 수 있습니다.
아래는 Schema Evolution과 Compatibility를 보여주는 예제입니다. 예를 들어, 사용자 정보를 포함하는 Kafka 메시지를 다루는 상황을 가정해보겠습니다.
// 초기 스키마
{
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "email", "type": "string"}
]
}// 스키마 변경: 이메일 필드를 선택적으로 변경
{
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "email", "type": ["null", "string"], "default": null}
]
}// 스키마 변경: 전화번호 필드 추가
{
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "email", "type": ["null", "string"], "default": null},
{"name": "phone", "type": ["null", "string"], "default": null}
]
}새로운 필드를 추가하거나 필드를 변경할 수 있으면서 이전 버전의 데이터와 호환성을 유지할 수 있습니다. 이를 통해 Kafka에서 유연하고 확장 가능한 데이터 파이프라인을 구축할 수 있습니다.
참고)
https://docs.confluent.io/platform/current/schema-registry/fundamentals/schema-evolution.html
