-
✔ 데이터 인코딩이란?
머신러닝 알고리즘은 문자열 데이터 속성을 입력받지 못하며, 모든 데이터는 숫자형으로 입력받아야 한다.
따라서, 문자형 카테고리 속성은 모두 숫자형으로 변환이 되어야 하는데, 이러한 과정을 데이터 인코딩이라 한다. -
데이터 인코딩의 종류
-
Label Encoding
-
범주형 변수의 문자열을 수치형으로 변환
-
예를 들어, 상품이 TV, 냉장고, 전자레인지가 있다고 하면, 이를 TV 0 , 냉장고 1 , 전자레인지 2 로 표현한다.
-
특정 ML 알고리즘 (회귀) 에서 예측 성능이 떨어질 수 있음
-
숫자의 경우 크고 작음에 대한 특성이 작용하기 때문임 ( e.g. 1보다 2가 큰 값이므로 특정 ML 알고리즘에서 가중치가 더 부여되어 더 중요한 변수로 인식될 수 있음)
-
따라서, 선형회귀와 같은 ML 알고리즘에는 적용하면 안 됨
-
트리 계열의 ML 알고리즘은 이러한 특성을 반영하지 않으므로, Label Encoding 을 사용해도 무방함
Label Encoding 에 대한 코드를 살펴보면 다음과 같다.
-
-
from sklearn.preprocessing import LabelEncoder
items = ['TV','냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']
# LabelEncoder를 객체로 생성 후, fit()과 transform()으로 Label encoding 수행
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값 :', labels)인코딩 변환값 : [0 1 4 5 3 3 2 2]
# 순서대로 0, 1, ... 값으로 인코딩 됨
print('인코딩 클래스 :', encoder.classes_)
# 인코딩 된 값을 다시 디코딩
print('디코딩 원본값 :', encoder.inverse_transform([4,5,2,0,1,1,3,3]))인코딩 클래스 : ['TV' '냉장고' '믹서' '선풍기' '전자레인지' '컴퓨터']
디코딩 원본값 : ['전자레인지' '컴퓨터' '믹서' 'TV' '냉장고' '냉장고' '선풍기' '선풍기']
-
One-Hot Encoding
-
입력값으로 2차워 데이터가 필요함 입력 데이터가 리스트라면, 2차원 array로 변환 필요
-
특성의 범주가 너무 많은 경우, 중요치 않은 특성들이 많아질 수 있고, 차원의 저주에 걸릴 수 있음 성능 저하 유발
-
OneHotEncoder 를 이용해 변환한 값이 Sparse Matrix 형태이므로, 이를 toarray( )를 이용해 Dense Matrix 로 변환해야함
-
Sparse Matrix : 0, 1로 구성된 행렬이 있을 때, 대부분 값이 0이 행혈 (전체 공간에 비해 데이터가 있는 공간이 매우 협소한 데이터)
-
Dense Matrix : 0, 1로 구성된 행렬이 있을 때, 대부분 값이 1인 행렬 (전체 공간에 비해 데이터가 있는 공간이 빽빽하게 차있는 데이터)
-
One-Hot Encoding 에 대한 코드를 살펴보면 다음과 같다.
-
from sklearn.preprocessing import OneHotEncoder
import numpy as np
items = ['TV','냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']
# One-Hot Encoding 을 위해 2차원 array로 변환
items = np.array(items).reshape(-1,1)
# One-Hot Encoding 적용
oh_encoder = OneHotEncoder()
oh_encoder.fit(items)
oh_labels = oh_encoder.transform(items)
# OneHotEncoder로 변환한 결과는 Sparse matrix 이므로 toarray()를 이용해 Dense matrix로 변환
print(oh_labels)
print('원-핫 인코딩 데이터 :\n', oh_labels.toarray())
print()
print('원-핫 인코딩 차원 :\n', oh_labels.shape)<8x6 sparse matrix of type '<class 'numpy.float64'>'
with 8 stored elements in Compressed Sparse Row format>
One-Hot Encoding 데이터 :
[[1. 0. 0. 0. 0. 0.][0. 1. 0. 0. 0. 0.][0. 0. 0. 0. 1. 0.][0. 0. 0. 0. 0. 1.][0. 0. 0. 1. 0. 0.][0. 0. 0. 1. 0. 0.][0. 0. 1. 0. 0. 0.][0. 0. 1. 0. 0. 0.]]
One-Hot Encoding 차원 : (8, 6)
-
get_dummies( )
One-Hot Encoding 을 수행할 때, 더 쉬운 방법이 있다. "get_dummies( )" 라는 Pandas API 를 사용하면 숫자 변환 과정을 거치지 않고 더욱 쉽게 수행이 가능하다.
import pandas as pd
df = pd.DataFrame({'item' : ['TV','냉장고','전자레인지',
'컴퓨터','선풍기','선풍기','믹서','믹서']})
pd.get_dummies(df)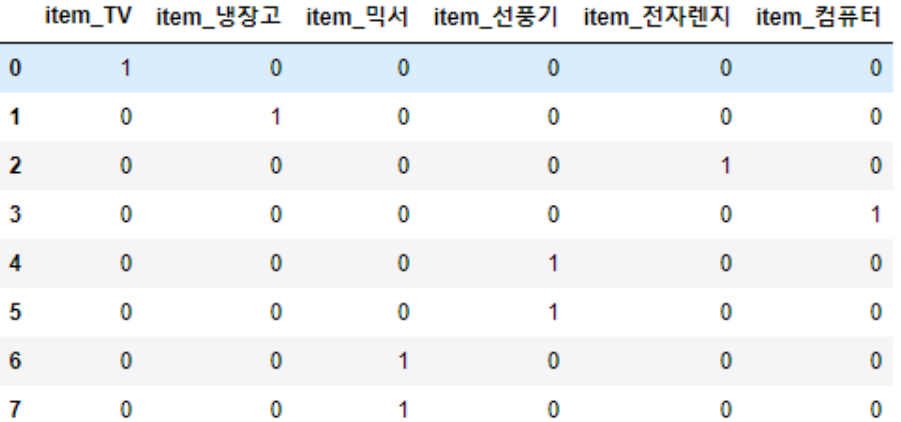
-
Ordinal Encoding
-
변수의 순서를 유지하는 인코딩 방식 순서가 중요한 특성에 대해 사용되어야 함
-
Label Encoding 과 유사하지만, Label Encoding 의 경우, 변수에 순서가 있음을 고려하지 않고 각 범주에 정수를 지정하는 것이므로 약간 다르다.
-
데이터 셋에 등장하는 순서 혹은 알파벳 순서대로 매핑하는 Label Encoding 과 달리 변수의 순서 정보를 담을 수 있음
Ordinal Encoding 에 대한 코드를 살펴보면 다음과 같다. 크게 2가지 방법이 있다.
-
from category_encoders import OrdinalEncoder
# 예시용 데이터셋 작성
df = pd.DataFrame(
{'Fruit': ['시과', '딸기', '바나나', '수박', '포도',
'메론','자두','체리','화이트베리', '무화과'],
'color':['red1','red2','yellow','red1','purple','green','light red','pink','white','brown'],
'price': [2000,300,400, 30000, 150, 8000,1000,100,300,800]})
enc1 = OrdinalEncoder(cols = 'color')
df2 = enc1.fit_transform(df)
print(df)
print(df2)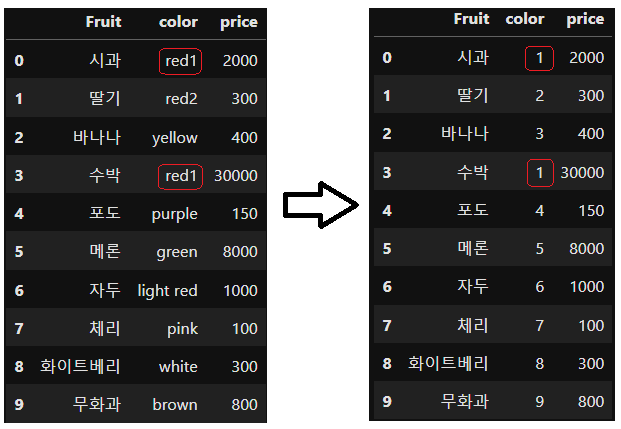 Ordinal Encoding 을 진행하고 싶은 컬럼인 'color' 컬럼을 지정하여 진행하였다. 기존 DataFrame 에 들어가 있는 데이터 순서대로 숫자가 지정되어 인코딩이 이루어진다. 단, 변환이 0부터 시작되는 Label Encoding, One-Hot Encoding 과는 다르게, Ordinal Encdoing 은 1부터 시작된다.
Ordinal Encoding 을 진행하고 싶은 컬럼인 'color' 컬럼을 지정하여 진행하였다. 기존 DataFrame 에 들어가 있는 데이터 순서대로 숫자가 지정되어 인코딩이 이루어진다. 단, 변환이 0부터 시작되는 Label Encoding, One-Hot Encoding 과는 다르게, Ordinal Encdoing 은 1부터 시작된다.
또한, 직접 Mapping 을 만들어 주어서 Ordinal Encoding 을 수행할 수 있다. 코드는 다음과 같다.
df = pd.DataFrame(
{'Fruit': ['시과', '딸기', '바나나', '수박', '포도',
'메론','자두','체리','화이트베리', '무화과'],
'color':['red1','red2','yellow','red1','purple','green','light red','pink','white','brown'],
'price': [2000,300,400, 30000, 150, 8000,1000,100,300,800]})
color_dict = {'red1' : 1, 'red2' : 2, 'yellow' : 3, 'purple' : 4, 'green' : 5,
'light red' : 6, 'pink' : 7, 'white' : 8, 'brown' : 9}
df['color_ordinal'] = df['color'].map(color_dict)
df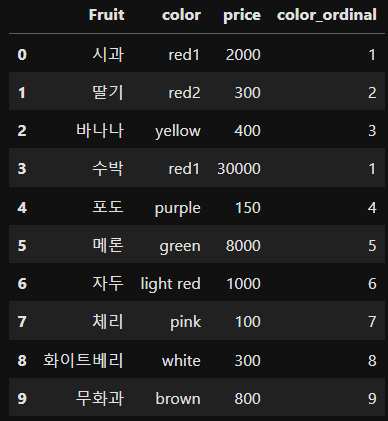
-
요약
-
선형 모델에서는 Label Encoding 을 사용하는 것이 위험하다. 숫자의 경우 크고 작음의 특성이 반영될 수 있기 때문이다. One-Hot Encoding 이 유용할 수 있음
-
트리 기반 모델에서는 Label Encoding 이 유용하다.
-
변수의 순서를 반영한 Label Encoding 을 수행하고 싶을 경우에, Ordinal Encoding 을 사용한다.
-
