Word Embeding
- Word Embeding 이란?
이전 강의에서 배운 bag-of-Words 기법은 단어를 단순히 one-hot-encoding 했기 때문에 단어간의 유사도가 어느정도 인지알 수 없다.
예를 들어 참새,독수리,앵무새,호랑이라는 단어가 주어 졌을 때, 각 단어간의 유사도를 계산하여 활용하고 싶을 때 사용하는 기법이다.
Word Embeding 예시

-
그래서 Word Embedding이 뭔데?
위의 사진을 보자 The Cat purrs, The Cat hunts mice. 라는 두 문장이 있을 때 Cat을 제외한 나머지 문장이 주어졌을 때, 나머지 문장을 보고 유사도를 계산하여 빈칸에 Cat이라는 단어를 넣을 수 있도록 하는 기법이다.Word Embeding

-
유사도는 어떻게 구하는지??
조건부확률 이용한다. 문장이 주어졌을 때, Cat과 유사한 단어들의 확률이 다면, 이는 Cat과 유사도가 높은 단어라고 할 수 있다.
Word Embeding의 wgiht training
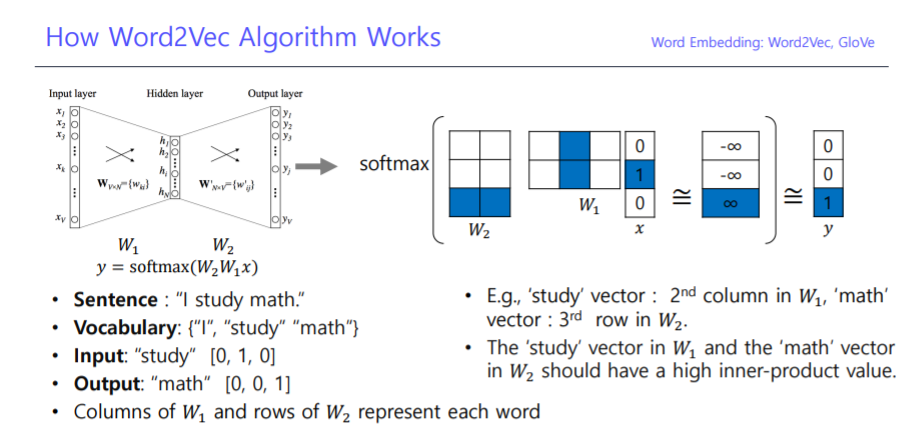
- Embeding Model의 Wight는 어떻게 구해질까???
위 그림을 보자, 입력이 되는 x는 bag-of-word를 이용하여 단어들을 one-hot-encode 형태로 표현한 vector이다. 이 vector들은 hidden layer인 h와 연산을 거치고 활성함수인 Softmax를 거치면서 확률값으로 나타나게 된다. 이 확률값과 ground trus인 y와의 loss를 구하여 w1과 w2를 업데이트 시켜준다. 위와 같은 가정을 여러 epoch을 거치고 나면 입력 x가 들어왔을 때, output이 되는 확률이 우리가 원하는 y의 벡터와 일치할 수 있도록 wgiht가 학습되어지게 된다.
-> 학교에서 word embeding을 배울 때, 이해가 안되서 어려웠던 기억이 있었는데 주재걸교수님이 천천히 어떻게 학습되는지 설명해주셔서 이해할 수 있게되었다. 주재걸교수님 강의력 👍👍
