GELU
Gaussian Error Linear Unit 활성화 함수를 의미한다.
BERT 모델을 기반으로 한 많은 모델에서 사용중이다.
CNN에서는 Tranformer를 사용한 VIT 모델이 개발된 이후 활성화 함수로 주로 사용된다.
## Google Bert
def gelu(x):
"""Gaussian Error Linear Unit.
This is a smoother version of the RELU.
Original paper: https://arxiv.org/abs/1606.08415
Args:
x: float Tensor to perform activation.
Returns:
`x` with the GELU activation applied.
"""
cdf = 0.5 * (1.0 + tf.tanh(
(np.sqrt(2 / np.pi) * (x + 0.044715 * tf.pow(x, 3)))))
return x * cdf
## OpenAI GPT-2
def gelu(x):
return 0.5*x*(1+tf.tanh(np.sqrt(2/np.pi)*(x+0.044715*tf.pow(x, 3))))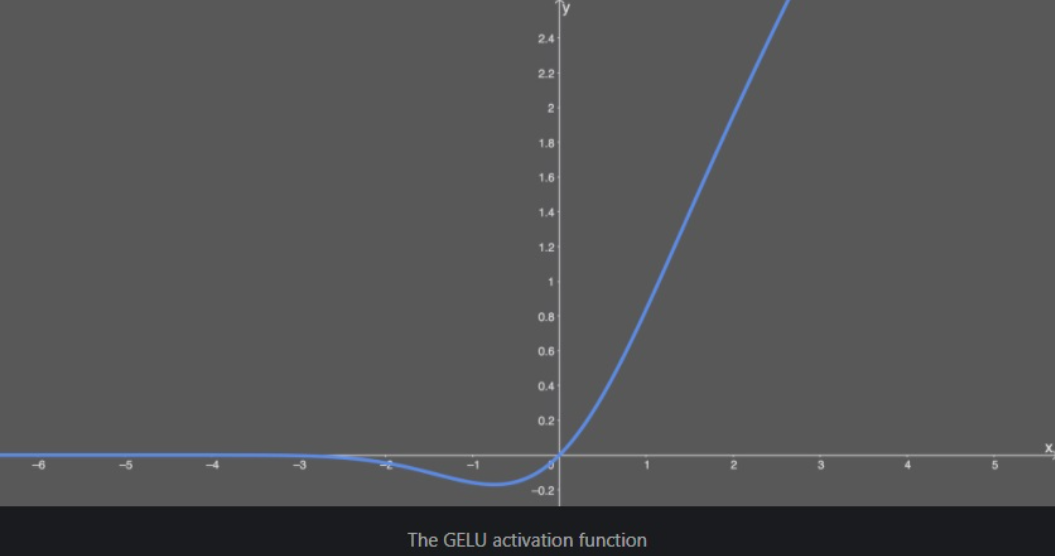
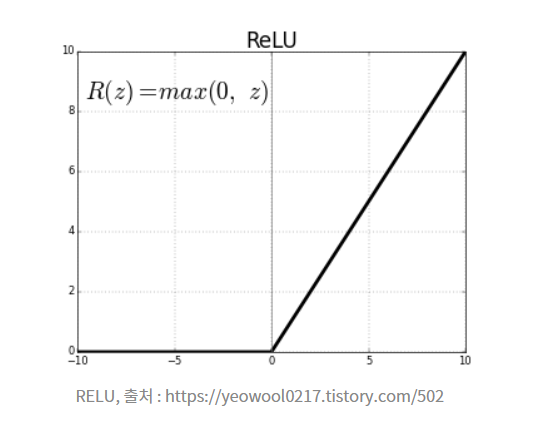
초기 신경망에서는 이진법 단위를 이용해서 sigmoid 함수에 의해 평준화 되었으나 네트워크 층이 깊어짐에 따라 RELU를 주로 사용하였다.
GELU로 기본적인 함수의 사용목적은 RELU와 흡사하다.
RELU는 0이하는 버리고 0이상은 그대로 취하는 형태를 가진다.
0이상의 값은 input을 그대로 가져간다고 생각한다.
GELU는 dropout + zoneout + RELU를 조합하는 형태이다.
Dropout은 0~1까지 일정 확률로 마스킹 하는 여ㅛㄱ할을 한다.
이 과정을 distribution 함수와 Relu의 곱으로 표현한 것이다 GELU이다. 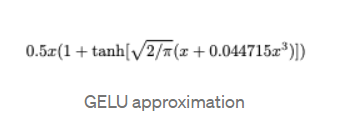
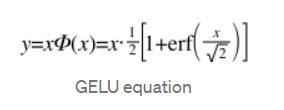
아래가 실제 식이지만 근사식을 사용하는 것이 속도 정확도 측면에서도 더욱 편리하기 때문에 실 사용시에는 근사식을 사용한다.

매일 1%씩 성장하는 개발 공부 블로그 입니다.