
1. ZooKeeper
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination.
무슨말인지 말 모르겠다. 분산처리와 관련되어 사용되는 것 같은데.. 아직 분산처리를 실행해본적이 없어서 경험과 연결되지 않아서 더 난해하다.
Zookeeper it self is allowing multiple clients to perform simultaneous reads and writes and acts as a shared configuration service within the system.
여러 클라이언트들이 동시에 데이터에 접근할 수 있도록 도와주는 시스템인 것 같다.
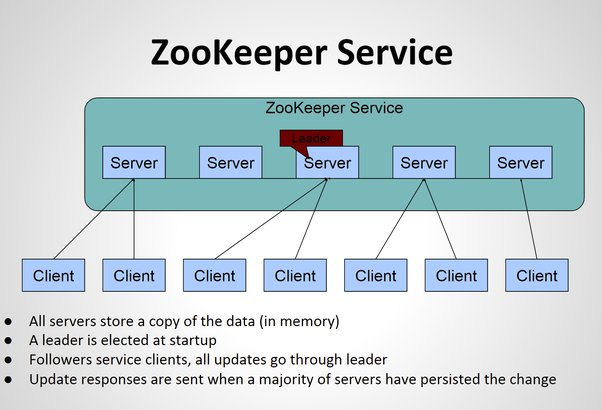
복수의 서버들이 대규모 클라이언트들의 데이터 요청을 처리해주는 서버로 이해가 된다. 이때 데이터의 일관성을 유지하고, 업데이트를 진행하는 방식이 궁금하기는 한데 일단은 이정도로만 이해하고 디테일은 나중에 필요할 때 찾아보면 될 것 같다.
2. Vitess
Vitess is a database solution for deploying, scaling and managing large clusters of open-source database instances. It currently supports MySQL and Percona Server for MySQL. It's architected to run as effectively in a public or private cloud architecture as it does on dedicated hardware. It combines and extends many important SQL features with the scalability of a NoSQL database.
데이터베이스를 배포하고 확장해주는 역할?
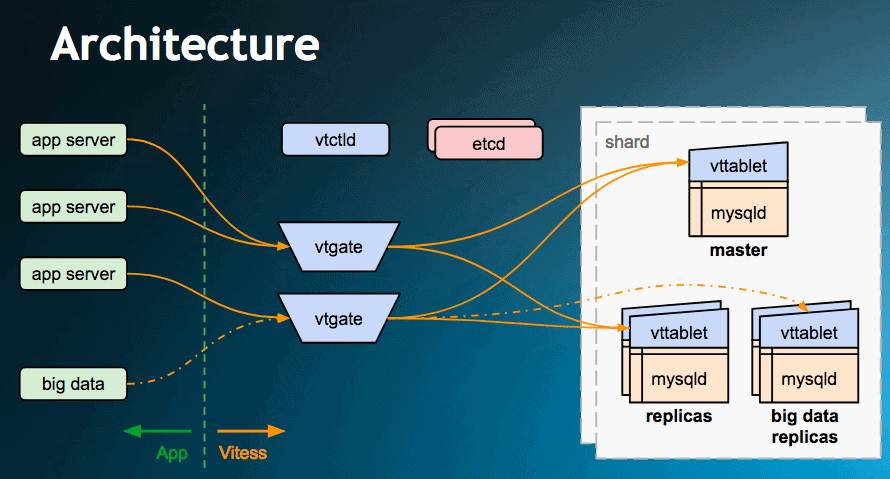
내가 제대로 이해하고있는 건지는 모르겠지만 아키텍쳐 이미지를 보면 그게 어떤 역할을 하는지가 더 잘 이해되는 것 같다. Zookeeper가 대규모 서버접근 요청을 분산적으로 처리해주는 역할을 맡는다면 Vitess는 데이터베이스 접근 요청을 분산적으로 처리해주는 역할을 맡는 듯 하다
3. TimeScaleDB
TimescaleDB is the open-source relational database for time-series and analytics. Build powerful data-intensive applications.
RDB라는건 알겠는데, time-series라는 특징이 어떤점에서 기존 일반적인 DB와 차이점을 만드는걸까?
TimescaleDB offers three key benefits over vanilla PostgreSQL or other traditional RDBMSs for storing time-series data:
- Much higher data ingest rates, especially at larger database sizes.
- Query performance ranging from equivalent to orders of magnitude greater.
- Time-oriented features.
And because TimescaleDB still allows you to use the full range of PostgreSQL features and tools — for example, JOINs with relational tables, geospatial queries via PostGIS, pg_dump and pg_restore, any connector that speaks PostgreSQL — there is little reason not to use TimescaleDB for storing time-series data within a PostgreSQL node.
기존 디비 API를 그대로 활용할 수 있으면서 대규모 시계열 데이터 처리에 유리해서. 음 이런거를 도입할 정도면은 정말 대규모 데이터를 처리해야 해서 자그마한 차이가 엄청난 효과를 줄때 도입을 고려할만 하겠다. 사실 보통의 서비스는 일단 가장 일반적인 프로그램을 활용해서 개발하는게 맞는거 같음.
