텍스트 마이닝

정의
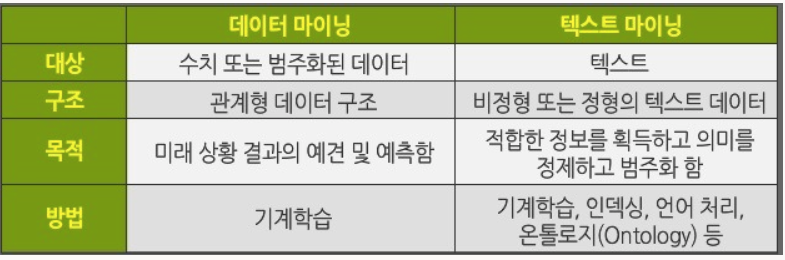
비정형 데이터 마이닝의 유형 중 하나이다. 텍스트마이닝은 비정형 및 반정형 데이터에 대하여 자연어 처리 기술과 문서 처리 기술을 적용하여 유용한 정보를 추출, 가공하는 목적으로 한다. 실생활에서 만들어지는 대부분의 자료는 문서 형태인데, 여러 분야의 논문, 신문 또는 잡지의 기사, 여론조사, 콜센터의 전화 보고서, 이메일, 디지털 형태의 문서 등의 형태를 가지고 있다.문서 형태의 데이터는 기존의 통계분석이나 데이터 마이닝 기법을 적용하기에 부적합한 데이터 형태를 가지고, 대부분 텍스트 데이터베이스에 저장된 데이터는 반 구조적 데이터이다. 이때 반 구조적 데이터란 완전하게 구조적이지도 않고 완전하게 비구조적이지도 않은 데이터를 의미한다. 문서는 제목, 작가, 출판날짜, 길이, 분류 등과 같은 약간의 구조적인 분야들을 포함할 수 있고, 또 문서의 요약, 내용과 같이 크기가 큰 비구조적 텍스트 요소 또한 포함되기 때문에 반 구조적 데이터이다.
기술
1. 자연어 처리
자연어처리 기술(NLP, Natural Language Processing)이란, 컴퓨터가 인간의 언어를 알아들을 수 있게 만드는 학문 분야다. 인공지능의 하위 분야로, 1960년 일반적인 인공지능을 만들려던 시도가 실패한 후 인간의 언어를 분석하고 해석하여 처리하는 인공지능이 세분화되면서 생긴 학문 분야이다. 흔히 우리가 아는 말하는 인간과 대화하는 컴퓨터 관련 기술이 이쪽에 속한다. 언어 공학, 컴퓨터과학, 인공지능, 전산언어학(Computational Linguistics)의 연구 분야이며, 자연어를 컴퓨터로 해석하고, 의미를 분석하여 이해하고, 자동으로 생성하는 것 등에 관련된 분야다. 자연어는 프로그래밍 언어와 같이 사람이 인공적으로 만든 언어가 아닌, 사람이 일상생활과 의사소통에 사용해 온 한국어, 영어와 같이 오랜 세월에 걸쳐 자연적으로 만들어진 언어라는 의미로, 우리가 흔히 말하는 언어를 뜻한다.
언어모델링
언어 모델(Language Model)이란, 언어라는 현상을 표현, 모델링하는 모델을 말한다. 언어라는 현상을 표현한다는 것은 다르게 말하면 기계가 자연어를 생성(NLG, Natural Language Generation)하는 일들을 한다는 것이다. 언어 모델은 자연어 생성 작업에 속하는 음성 인식, 기계 번역, 광학 문자 인식(OCR, Optical Character Recognition), 검색어 자동 완성, 문서 요약과 같은 일들을 수행한다. 조금 더 구체적으로 표현하자면, 언어 모델은 문장(단어 시퀀스)의 확률을 예측하는 모델이다. 언어 모델이 하는 일은 문장의 확률을 예측하는 일을 한다. 이전 단어들을 줬을 때 다음 단어가 나올 확률을 예측한다.
머신 러닝
데이터를 이용해서 컴퓨터를 학습시키는 방법론이다. 머신 러닝 알고리즘은 크게 세 가지 분류로 나눌 수 있다.
1. 지도학습(Supervised Learning) : 데이터에 대한 레이블(label), 즉 정답이 주어진 상태에서 컴퓨터를 학습시키는 방법론이다. 즉, '데이터, 레이블'의 형태로 학습을 진행한다.
2. 비지도학습(Unsupervised Learning) : 데이터에 대한 레이블을 주지 않는 상태에서 컴퓨터를 학습시키는 방법론이다. 즉, '데이터'의 형태로만 학습을 진행한다.
3. 강화학습(Reinforcement Learning) : 지도학습과 비지도학습과는 다른 학습 알고리즘이다. 지도학습과 비지도학습과는 달리 주어진 환경에 대해 어떤 행동을 취하고 이로부터 어떤 보상을 얻으면서 학습을 진행하는 방식이다.
데이터마이닝
데이터마이닝(Data Mining)이란, 대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 패턴을 찾아내는 것이다. 또한, 통계학에서 패턴 인식에 이르는 다양한 계량 기법을 사용한다. 데이터마이닝 기법은 통계학 쪽에서 발전한 탐색적자료 분석, 가설 검정, 다변량 분석, 시계열 분석, 일반 선형모형 등의 방법론과 데이터베이스 쪽에서 발전한 온라인 분석 처리(OLAP, On-Line Analytic Processing), 인공지능 진영에서 발전한 자기 조직화 지도(SOM, Self-Organizing Map), 신경망, 전문가 시스템 등의 기술적인 방법론이 쓰인다. 응용 분야로는 신용평점 시스템(Credit Scoring System)의 신용평가모형 개발, 사기탐지시스템(Fraud Detection System), 장바구니 분석(Market Basket Analysis), 최적 포트폴리오 구축과 같이 다양한 산업에서 광범위하게 사용되고 있다. 데이터 마이닝 기술의 적용 분야는 다음과 같다.
- 분류(Classification) : 일정한 집단에 대한 특정 정의를 통해 분류 및 구분을 추론한다.
- 군집화(Clustering) : 구체적인 특성을 공유하는 군집을 찾는다.
- 연관성(Association) : 동시에 발생한 사건 간의 관계를 정의한다.
- 연속성(Sequencing) : 특정 기간에 걸쳐 발생하는 관계를 규명한다.
- 예측(Forecasting) : 대용량 데이터 집합 내의 패턴을 기반으로 미래를 예측한다.
텍스트 마이닝 4가지 기능
- 문서 요약
- 문서 분류
- 문서 군집
- 특성 추출
분석 절차
1. 데이터 수집
데이터 크롤링 위주로 데이터를 수집한다.
2. 데이터 전처리
- Cleansing (remove stopword/ punctuation/ whitespace/ …)
- Corpus 생성
- tm_map() 함수의 적용
3. 자연어처리
- Tokenization/ Normalization
- Stemming
- 한글처리
4. TDM(Term Document Matrix) 구축
5. 텍스트 분석
- 빈도분석 (토픽 분석)
- 군집분석 (유사 단어들 또는 문서들간의 분석)
- 연관분석 (연관 단어 추출, 단어 네트워크 분석)
- 감성분석 (단어 분석)
- 분류 (classification)
- 주요 키워드의 추출
- 토픽 트렌드 분석, 이상치 분석 (normality)
시각화
- 워드 클라우드 (단어 출현 빈도)
- 빈도 막대 그래프 (단어 출현 빈도)
- 연관성 네트워크 (동시 출현 빈도; 기준단어로 데이터 탐색)
[출처 : https://blog.naver.com/PostView.nhn?blogId=jinis_stat&logNo=221671837442]
문제점
텍스트 마이닝의 문제점은 크게 두 가지가 있다.
1. 자연어에 영향을 많이 받는다는 것인데, 자연어란 사람이 쓰는 말로 한국어, 일본어, 독일어, 영어 등을 의미한다. 자연어 중 한글이나 한국어 처리에서 문제가 있는 분야는 광학 문자판독, 음성인식 그리고 감성 분석 등이 있다.
2. 분석 결과물 자체로 어떤 성과를 보기 어렵다는 것이다. 이는 분석 결과물 자체를 그대로 비즈니스 모델에 적용해서 뭔가를 만들어 성과를 보기 어렵다는 의미이다.
[출처: http://wiki.hash.kr/index.php/%ED%85%8D%EC%8A%A4%ED%8A%B8%EB%A7%88%EC%9D%B4%EB%8B%9D]
