0. 어째서 파이썬인가
원래 자료구조 및 알고리즘 공부를 할 때, 직접 구현하고 테스트해보면서 동작 로직을 익히며 이해하는 공부를 하였다. 그때 채택했던 언어는 자바였다.
당시의 채택 근거는 아래와 같았다.
- 나는 자바를 공부하고 있는 과정이므로 문법 활용에 도움이 된다
- 단순히 구현에만 치중하는 것이 아닌(모든 로직을 정적으로 짜는...), 객체지향과 연계해서 고려한다
- 중첩 클래스를 활용해서 노드의 의의까지 구현한다
실제로 스택, 큐, 연결 리스트, 그래프를 구현하면서 중첩 클래스 및 접근 제한, 그를 통한 객체지향에 대한 고찰에 큰 도움이 됐다. 그리고 그것들 중, 그래프를 바탕으로 dfs와 bfs를 기반으로 한 목적지 탐색 메소드를 구현하는 것 또한 성공했었다.
그렇지만 파이썬을 우연찮게 접하고, 리트코드와 백준에서 파이썬을 활용해서 문제를 푸니까 동적 타입에 가독성이 뛰어나고 수학 관련 도구들이 많아서 자바의 세세한 타입 지정부터 변수 할당까지 소비되던 시간들이 절약되는 느낌이었다.
파이썬을 선택한 이유는 다음과 같다
- 가독성이 너무나도 뛰어나다. 즉, 코드 작성에 있어 시간 절약이 된다
- 기본 라이브러리의 활용에 있어 자바보다 매우 직관적이며 풍부하다
- 동적 언어에 변수 선언이 불필요하다
그렇다고 자바를 통한 문제풀이 혹은 알고리즘 공부를 그만두는 것은 아니다. 기왕이면 병행하는 것이 가장 베스트지만, 우선은 파이썬을 중점으로 문제를 풀어보고 향후 복습 및 여유가 있는 때에 자바로 리팩토링을 시도할 생각이다(심지어 자바스크립트로 리팩토링을 생각하고 있다. 아 힘들어)
그리고... 어차피 인공지능 공부할 거잖아? 미리미리 파이썬 익숙해두는 것도 나쁘지 않지.
1. 파이썬의 기본 문법
주의할 점은, 나는 파이썬을 주특기 언어로 삼은 시점이 아니라는 것이다. 물론 훗날에는 파이썬, 기타 언어가 또다른 주특기가 되는 시점이 분명 오지만 그건 그때고... 지금은 자료구조와 알고리즘을 공부하는 데에 있어 선택한 수단에 불과하다.
그렇지만 나는 파이썬이 처음(물론 문법이 유사한 타입스크립트와 자바의 경험이 있으므로 빗대서 이해하기는 쉬웠지만)이기 때문에, 알고리즘 문제 풀이에 있어 빈번하게 쓰일, 그리고 유용하게 쓰일 문법 정도는 정리하고 다음 글부터 공부 내용을 정리해야지.
1) 타입 힌팅
자바는 정적 언어에 선언부터 모든 것이 타입 지정으로 시작되므로 별 상관 없지만 자바스크립트는 대표적인 동적 언어여서 타입 선언과 변수 할당에 있어 매우 자유로운 편이다. 그럼에도 자바스크립트의 슈퍼셋 언어인 타입스크립트는 자바스크립트의 동적 특징을 타입 지정으로 안정성까지 겸비시키는 강력한 언어라고 평가받는다.
개인적으로 파이썬은 자바와 자바스크립트 그 중간의 특징을 지녔다는 느낌을 받았다(아님 말고) 심지어 변수 선언이 불필요한 점은 자바스크립트보다 더했으면 더했지 덜 하지는 않았다. 그럼에도 파이썬 코드 작성에 있어서 안정성을 부여하기 위한 기능이 있다. 바로 타입 힌트다.
a = "1"
b = 1
b = "one"사실 이렇게 코드 작성해도 파이썬에서는 별 문제 없다. 하지만 내가 이걸 왜 처음 마주했냐면 문제풀이를 수행하는 리트코드에서 타입 힌트를 통해 반환 타입을 지정하는 경우가 대다수였기 떄문이다.
a: str = "1"
b: int = 1타입 지정은 매우 간단하다. 타입스크립트와 거의 유사하다고 봐도 무방할 정도.
2) 리스트 컴프리헨션
만약 0 제곱부터 9 제곱까지 리스트에 담아서 출력하려면 기본적으로 반복문이 있다.
squares = []
for i in range(10): # range(i 개수)
squares.append(i ** 2)
print(squares)늘 언제나 가독성을 저해하는 대표적인 요소는 이런 반복문이라고 생각하던 와중에 파이썬에 마침 딱 좋은 기능이 있었다. 바로 리스트 컴프리헨션(list comprehension)이었다.
comprehension_square = [i**2 for i in range(10)]
print(comprehension_square)또한 조건문까지 추가가 가능하다. 단, if-else 구문은 for 구문 앞에 위치시켜야 한다는 점을 명심해야 한다.
## if만 사용(짝수 제곱만)
if_comprehension = [i**2 for i in range(10) if i % 2 ==0]
print(if_comprehension)
## if else 사용(for문 앞에 위치시키기, 4와 홀수는 그냥 나타내기)
if_else_comprehension = [i**2 if i % 2 == 0 and i != 4 else i for i in range(10)]
print(if_else_comprehension)알아둬야 할 점은, 리스트 컴프리헨션은 성능상의 이점이 존재하지 않는다. 즉, 단순히 가독성을 향상시키기 위한 수단일 뿐이지 메모리나 시간 복잡도 측면에서 향상성을 제공하는 것은 전혀 아니다.
Python 2.7 이후부터는 리스트 컴프리헨션이지만, 딕셔너리에도 적용이 가능해졌다. 이전에는 단순 반복문을 통해 순회하면서 key와 value에 직접 할당하는 식으로 딕셔너리에 값을 채워넣었다.
original = {1: "one", 2: "two", 3: "three", 4: "four"}
dictionary = {}
for key, value in original.items():
dictionary[key] = value
print(dictionary)하지만 이를 리스트 컴프리헨션을 활용하면 이렇게 표현이 된다. 리스트 대신 딕셔너리이므로 중괄호({})를 사용해서 표현한다. 그리고 위에서 주의점으로 언급했던 if-else 구문은 for 구문 앞에 위치해야 한다는 점 역시 딕셔너리를 대상으로 한 리스트 컴프리헨션에서도 적용된다.
comprehension_dictionary = {key: value for key, value in original.items()}
print(comprehension_dictionary)
if_comprehension_dictionary = {key: value for key, value in original.items() if len(value) > 3}
print(if_comprehension_dictionary)
if_else_comprehension_dictionary = {key: value if len(value) > 3 else value + " is no korean" for key, value in original.items()}
print(if_else_comprehension_dictionary)3) 제너레이터
제너레이터는 매우 큰 데이터셋에서 실질적으로 활용할 부분이 서브 데이터셋일 때 유용한 기능이다. 예를 들어서 0부터 10억까지의 수열을 리스트화하는 과정이 문제풀이에 있어 필수적이지만 실제 정답을 구하는 부분은 9억에서 9억 1천까지라고 하면, 일반적으로 이런 의사코드가 짜여질 것이다.
# for문으로 우선 0부터 10억까지 담은 리스트를 생성하고...
# 이제 그 내부에서 9억에서 9억 1천까지에 있어 로직을 적용시켜야지...근데 이렇게 되면 문제점이, 0부터 10억까지 리스트에 담아 생성하는 게 분명 정답을 도출하는 과정에 있어 필수적이긴 하지만 정작 실질적으로 활용하지 않는 부분이 크게 메모리와 시간을 잡아먹게 된다.
아래 코드를 확인해보자
# 리스트 생성 함수
def create_list(n):
result = []
for i in range(n):
result.append(i)
return result
# 제너레이터를 생성하는 함수
def create_generator(n):
for i in range(n):
yield i제너레이터는 함수와 유사한 구조를 지녔고 정의에 있어 함수처럼 작성하지만 return이 아닌 yield를 사용한다는 점이다. 제너레이터가 생성됐을 때 이터레이션을 통해 값을 하나씩 제공할 수 있게 된다.
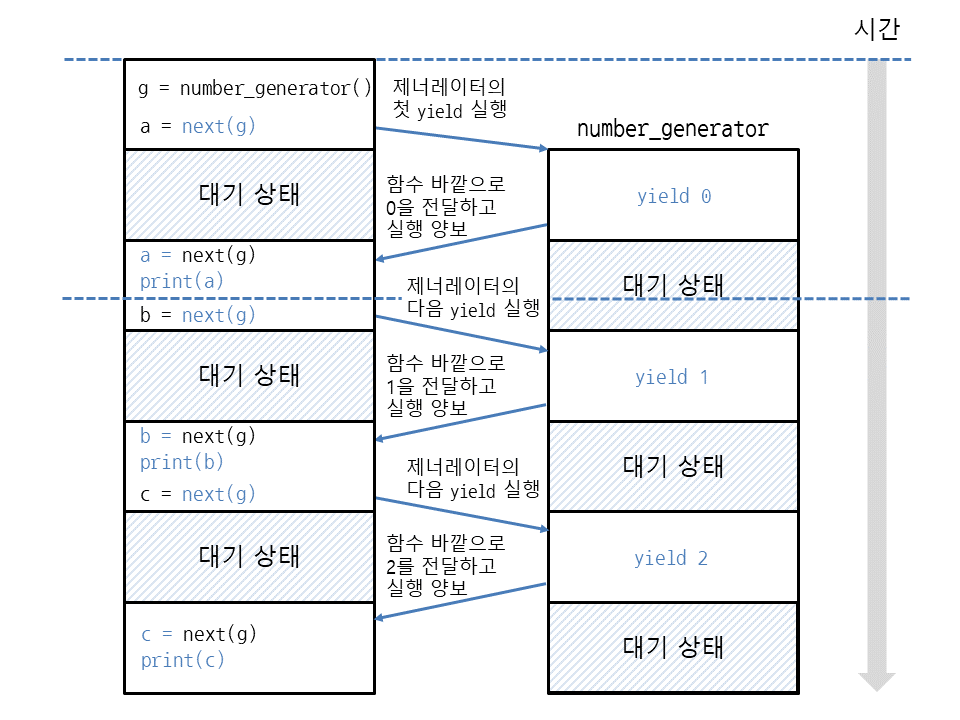
실제로 코드의 시간 소요를 비교하면 아래와 같은 결과가 나온다.
# 리스트 생성 함수
def create_list(n):
result = []
for i in range(n):
result.append(i)
return result
# 제너레이터를 생성하는 함수
def create_generator(n):
for i in range(n):
yield i
# 시간 측정을 위한 함수
def measure_time(func, *args): # *args는 자바의 int... nums랑 같(가변 인자)
start_time = time.time()
func(*args)
end_time = time.time()
return end_time - start_time
# 실행 시간 측정
list_time = measure_time(create_list, 100000000)
generator_time = measure_time(create_generator, 100000000)
# 리스트 생성 시간: 11.826366901397705
# 제너레이터 생성 시간: 1.3113021850585938e-05참조 링크
https://dojang.io/mod/page/view.php?id=2412
range()
제너레이터를 활용하는 대표적인 함수로 range()가 있다. range()는 range 클래스를 리턴한다. for 문을 사용할 경우, 제너레이터의 next()를 호출하듯이 매번 다음 숫자를 생성한다. 제너레이터를 리턴하듯 range 클래스만 리턴하면, 즉 생성 조건만 정하고 나중에 필요할 때 쓸 수 있게 된다.
def measure_time(func, *args): # *args는 자바의 int... nums랑 같(가변 인자)
start_time = time.time()
func(*args)
end_time = time.time()
return end_time - start_time
start_time = time.time()
a = [i for i in range(1000000000)] # 리스트 전체를 메모리에 저장(이미 생성된 값이 담겨져 있음)
end_time = time.time()
print('a의 생성 시간: ' + str(end_time - start_time)) # a의 생성 시간: 54.24660611152649
start_time = time.time()
b = range(1000000000) # 필요 요소를 생성할 때만 메모리 사용(생성 조건만 그저 존재할 뿐)
end_time = time.time()
print('b의 생성 시간: ' + str(end_time - start_time)) # b의 생성 시간: 1.52587890625e-05
print(len(a) == len(b)) # True
print('a의 메모리 점유율: ' + str(sys.getsizeof(a))) # a의 메모리 점유율: 8058558872
print('b의 메모리 점유율: ' + str(sys.getsizeof(b))) # b의 메모리 점유율: 48
# for 루프의 in 키워드 뒤에 사용되는 range() 함수는 정수 범위를 생성
# 이 범위는 반복문에서 순회되며, for 루프가 각각의 요소에 대해 실행될 때 사용
# 느낌이 뭔가 크게 잡을 범위는 range로 딱 잡아만 두고, 그 내부에서 필요한 걸 이제 세세한 로직을 짜는거
# 처음부터 for문으로 전부 생성하는 것이 아니고4) 열거
리스트를 순회할 때, 리스트의 인덱스도 같이 접근해야 하는 경우도 있다. 물론 단순 반복문에 있어서 로직을 짬으로써 쉽게 접근이 가능하긴 하다.
index = 0
for el in ['A', 'B', 'C']:
print(index, el)
index += 1근데 이러면 코드가 네임 스페이스에 남아서 이상적이지 않다. 그래서 len() 함수를 이용하는 것도 생각할 수도 있긴 하다.
letters = ['A', 'B', 'C']
for index in range(len(letters)):
letter = letters[index]
print(index, letter)근데 이러면 파이썬답지 않은 코드라고 하는데... 사실 이 부분은 명확히 어떤 표현인지 이해를 못 했다. 여튼 파이썬스럽게 코드를 짠다면 enumerate()를 활용하는 것이다.
for entry in enumerate(letters):
print(entry)
# 인덱스랑 해당 요소 별개로 취급도 가능
for index, element in enumerate(letters):
print(index, element)
# 시작 인덱스 기준 변경 가능(예시는 0이 아닌 1에서 시작해서 2가 아닌 3까지 출력되도록)
for index, element in enumerate(letters, start=1):
print(index, element)참조 링크
https://www.daleseo.com/python-enumerate/
5) print()
사실 콘솔에 출력하는 것은 자바나 자바스크립트 때에 많이 해오던 거라서... 크게 논할 부분은 없고 다만 포맷팅 관련 문법이 어떤 지에 대해서 간략하게 확인만 하고 넘어가는 것으로...
# print는 한 칸 공백이 디폴트로 설정되어 있다
print('A', 'B') # A B
# 구분자를 지정할 수 있다
print('A', 'B', sep=',') # A,B
print('A', 'B', sep='/') # A/B
# print는 줄바꿈이 디폴트 세팅이다
# 그래서 end를 활용해서 줄바꾸지 않고 이어쓰기가 가능하다
print('A', end='')
print('B') # AB
# 리스트를 출력할 때는 join을 활용한다.
# join 앞에 요소 별 사이에 이을 문자열 지정
list = ['A', 'B', 'C', 'D']
print(''.join(list)) # ABCD
print(' '.join(list)) # A B C D
print(', '.join(list)) # A, B, C, D
print()
# print에서의 포맷팅
idx = 0
fruit = 'apple'
print('{0}: {1}'.format(idx + 1, fruit))
# {0}, {1}은 위치 지정자. 각각 idx + 1과 fruit이 들어갈 자리
# format에 의해 문자열에 포맷팅 적용
print('{}: {}'.format(idx + 1, fruit))
# 위치 지정자 내부의 인덱스 생략도 가능
print(f'{idx + 1}: {fruit}')
# 요건 f-string6) locals()
로컬에 선언된 모든 변수의 정보를 확인해야 할 때도 있다. 그럴 때 사용하는 메소드가 locals()다. 여담으로 로컬이란 뜻은 메소드 내부에 해당 메소드를 선언해서 확인하면 메소드 내부의 변수 정보들만 확인할 수 있는 것이다.
import pprint
a = 'A'
b = 1
c = [100, 200, 300, 400]
d = ['def', 'py', 'th', 'on']
e = {0: '가', 1: '나', 2: '다', 3: '라'}
# locals()는 로컬에 선언된 모든 변수를 확인
# 로컬 스코프로 제한해서 확인 가(메소드 내부에서 호출하면 메소드 내부의 변수들만)
# 주로 pprint와 같이 씀
pprint.pprint(locals())