4. JPA
JPA(Java Persistence API)는 ORM 기술 표준으로 사용하는 인터페이스 컬렉션이다. ORM(Object Relation at Mapping)은 객체와 관계형 데이터베이스에서 사용되는 기술로, 단일 종속성을 강하게 가지던 기존의 객체와 데이터베이스의 관계에서. 의존성을 줄이고 상호 간의 간극을 좁히는 특성을 갖게 된다. 자바에서는 Hibernate가 ORM 도구로써 활용되며 JPA를 구현하는 오픈 소스의 역할을 맡고 있다.
1) JPA의 특징
JPA 이전에는 주로 JDBC를 활용해서 관계형 데이터베이스와의 상호 관계를 맺었다. 하지만, 복잡한 SQL문의 작성과 객체 관계 매핑의 부재로 개발자가 작성할 추가 코드가 많았다.
JPA는 개요에서 언급한 장점들을 통해 JDBC로부터 기인하는 복잡성을 줄이게 되었고 객체지향적 코드 설계를 최대한 준수시키며 각자가 지니는 고유한 특징들을 반영할 수 있게 됐다. 예를 들어서 자바에서는 상속 관계를 지원하지만 데이터베이스는 그런 개념이 존재하지 않는데, 객체(자바 객체)와 관계(관계형 데이터베이스)를 매핑하면서 유사하게 처리할 수 있다. 아래 그림이 해당 예시다.
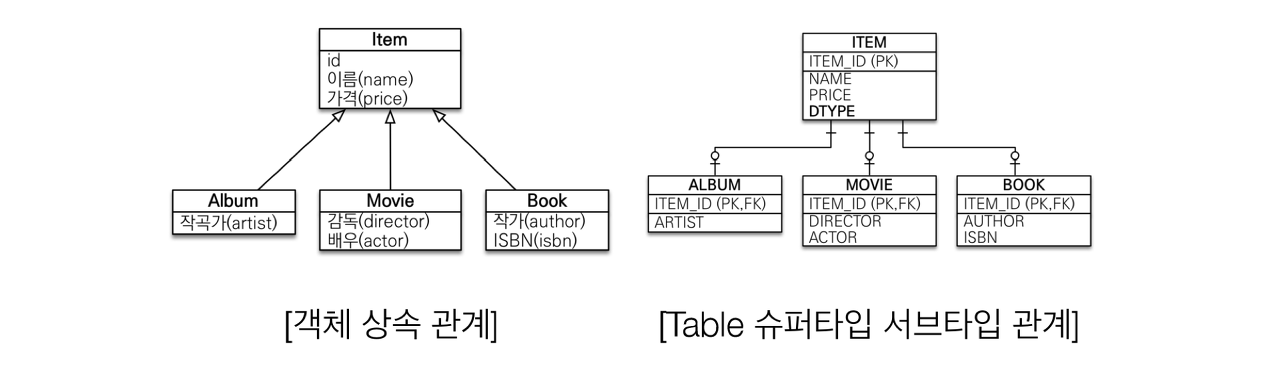 다만, 용어에서도 보이듯이 결국 JPA를 능숙하게 다루기 위한 학습비용이 상당히 비싼 축에 속한다. 결국 공부해야 될 내용이지만... 우선은 JPA를 이루는 기본적인 개념들부터 천천히 시작해볼 예정.
다만, 용어에서도 보이듯이 결국 JPA를 능숙하게 다루기 위한 학습비용이 상당히 비싼 축에 속한다. 결국 공부해야 될 내용이지만... 우선은 JPA를 이루는 기본적인 개념들부터 천천히 시작해볼 예정.
(1) Hibernate
용어 숙지를 조금 명확하게 할 필요가 있다. 스프링에서 흔히 사용하는 것으로 알고있는 JPA는, JPA를 이용하는 spring-data-jpa 프레임워크이지 개념적인 의미의 JPA를 뜻하는 게 아니다.
또한, JPA를 사용한다고 해서 JDBC를 사용하지 않는 것은 아니다. JPA는 JDBC를 기반으로 동작하고 있다. JPA는 데이터베이스와 상호 작용하는 데에 JDBC를 사용하지만, JDBC의 복잡한 작업들을 추상화하고 보다 객체 지향적인 인터페이스를 제공하기 때문에 개발자가 SQL문으로부터 약간이나마 벗어날 뿐이다.
(2) Entity
JPA의 핵심 키워드는 매핑이다. 결국 서로 연결지어지는 것이고, 데이터베이스의 테이블과 연결지어지는 객체가 바로 엔티티다.
// 음식
@Entity
@Table(name = "food")
public class Food {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private double price;
@ManyToOne
@JoinColumn(name = "user_id")
private User user;
}// 고객
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "user")
private List<Food> foodList = new ArrayList<>();
}저 foodList는 실제로 테이블에 저장되지 않는다. @Column 어노테이션이 없으니깐...
근데 그럼 DB에서 SELECT와 JOIN을 활용해서 조회하며 되지 왜 굳이 서버 코드에서도 저런 식으로 나타내냐면... 객체지향의 장점인 객체 간의 연관관계를 명료화하기 위해서
- DB 테이블에서는 고객 테이블 기준으로 음식의 정보를 조회하려고 할 때 JOIN을 사용하여 바로 조회가 가능하지만 고객 Entity 입장에서는 음식 Entity의 정보를 가지고 있지 않으면 음식의 정보를 조회할 방법이 없습니다.
- 따라서 DB 테이블에 실제 컬럼으로 존재하지는 않지만 Entity 상태에서 다른 Entity를 참조하기 위해 이러한 방법을 사용함다.
<정리>
- DB 테이블에서는 테이블 사이의 연관관계를 FK(외래 키)로 맺을 수 있고 방향 상관없이 조회가 가능합니다.
- Entity에서는 상대 Entity를 참조하여 Entity 사이의 연관관계를 맺을 수 있습니다.
- 하지만 상대 Entity를 참조하지 않고 있다면 상대 Entity를 조회할 수 있는 방법이 없습니다.
- 따라서 Entity(즉, 서버사이드의 자바 코드)에서는 DB 테이블에는 없는 방향의 개념이 존재합니다.
OneToOne
Entity에서 외래 키의 주인은 일반적으로 N(다)의 관계인 Entity 이지만 1 대 1 관계에서는 외래 키의 주인을 직접 지정해야합니다.
외래 키 주인만이 외래 키 를 등록, 수정, 삭제할 수 있으며, 주인이 아닌 쪽은 오직 외래 키를 읽기만 가능합니다.
1 대 1 에서의 양방향 관계에서 외래 키의 주인을 지정해 줄 때 mappedBy 옵션을 사용합니다.
- mappedBy의 속성값은 외래 키의 주인인 상대 Entity의 필드명을 의미
- 즉, 주인이 아닌 쪽에서 주인이 누군지를 명시하는 mappedBy를 쓰는 셈
외래 키의 주인만이 외래 키를 직접 조정할 수 있다.
ManyToOne
상대 엔티티 입장에서는 OneToMany가 된다
그리고 외래키의 주인임을 명시하기 위해 당연히 @mappedBy가 붙는 건 당연지사
설령 외래키 주인이 아닌, 상대 필드에서 리스트를 갖고 있다고 해도, 걔는 @Column이 없다. 즉, 단순 조회의 용도일 뿐이지 상식적으로 데이터베이스의 컬럼에 리스트로 저장될 수 있을 리가 없다.
OneToMany
가장 난해하고 어렵고 짜증나는 존재
분명 외래키의 주인은 One인 나지만, 실제 외래키는 상대 엔티티가 갖고 있다. 결국 One에 해당하는 주인 엔티티에서 상대 엔티티의 리스트(조회용)를 필드로 둬야 함
심지어 @JoinColumn(name = '나의 아이디')가 된다. 왜냐하면 상대 엔티티가 실제 외래키를 갖고 있는데, 그 키가 상대의 엔티티 아이디면 좀 이상하잖아? 상식상 나의 아이디를 갖고 있는 것이 맞긴 한데...
1대 다 관계다 보니까, INSERT 한 방으로 처리할 수 있는 걸, 리스트를 업데이트 하는 식으로 이뤄지다 보니 상대 엔티티에서의 UPDATE가 추가적으로 발생하게 된다.
심지어 1대 N 양방향 관계는 JPA에서 케이스를 제공하지도 않음
뭔말인고 하니, @ManyToOne 어노테이션의 속성으로 mappedBy 옵션을 제공하지 않는다는 거임
ManyToMany
N : M 관계는 중간 테이블을 만들어서 처리해야 함
단, 직접 테이블에 해당하는 엔티티를 생성할 필요가 없을 수 있음
@ManyToMany
@JoinTable(
// 중간 테이블 생성
name = "orders",
// 현재 위치인 Food Entity(외래 키 주인)에서 중간 테이블로 조인할 컬럼 설정
joinColumns = @JoinColumn(name = "food_id"),
// 반대 위치인 User Entity(노비 엔티티) 에서 중간 테이블로 조인할 컬럼 설정
inverseJoinColumns = @JoinColumn(name = "user_id"))
private List<User> userList = new ArrayList<>();중간 테이블 생성은 자바 코드가 아닌 JPA에 의해 이뤄지므로 PK가 없음
그래서 변경 사항이 있을 때 다루기가 상당히 어려움
- 갑자기 공부하다가 생각난 건데... 양방향의 의의는 노비 엔티티도 외래키 주인 엔티티에 대해 조회는 가능하도록 하는 것일.. 듯?
- 즉, 방향의 의미는 바라볼 수 있는 방향이라는 뜻이 아닐까
N대 M은 뭔가 생각할 거리가 상당히 많은 듯
우선은 기본 원칙인, 외래키 주인 아닌 노비가 주인 할 일(데이터베이스에 추가(+ 수정, 삭제..))을 대신 할 수는 없다.무엄하다
중간 테이블이 생기면(즉, 중간 테이블에 해당하는 엔티티를 선언하면) 외래키의 주인이 중간 테이블로 가네???
mappedBy는 외래키의 주인을 지정하고, 외래키의 주인이 갖고 있는 필드 명들을 옵션에 추가해줘야 한다.
지연 로딩
“아보카도 피자”의 가격을 조회하려고 했을 뿐인데 자동으로 JOIN 문을 사용하여 연관관계가 설정되어있는 고객 테이블의 정보도 가져오고 있습니다.
-
JPA는 연관관계가 설정된 Entity의 정보를 바로 가져올지, 필요할 때 가져올지 정할 수 있습니다.
- 즉, 가져오는 방법을 정하게되는데 JPA에서는 Fetch Type이라 부릅니다.
- Fetch Type의 종류에는 2가지가 있는데 하나는
LAZY, 다른 하나는EAGER입니다. LAZY는지연 로딩으로 필요한 시점에 정보를 가져옵니다.EAGER는즉시 로딩으로 이름의 뜻처럼 조회할 때 연관된 모든 Entity의 정보를 즉시 가져옵니다.
-
기본적으로 @OneToMany 애너테이션은 Fetch Type의 default 값이
LAZY로 지정되어있고 반대로 @ManyToOne 애너테이션은EAGER로 되어있습니다. -
다른 연관관계 애너테이션들도 default 값이 있는데 이를 구분하는 방법이 있습니다.
- 애너테이션 이름에서 뒤쪽에 Many가 붙어있으면 설정된 해당 필드가 Java 컬렉션 타입일 것입니다.
- 즉, 해당 Entity의 정보가 여러 개 들어있을 수 있다는 것을 의미합니다.
- 따라서 효율적으로 정보를 조회하기 위해
지연 로딩이 default로 설정되어있습니다.
- 반대로 이름 뒤쪽이 One일 경우 해당 Entity 정보가 한 개만 들어오기 때문에 즉시 정보를 가져와도 무리가 없어
즉시 로딩이 default로 설정되어있습니다.
- 애너테이션 이름에서 뒤쪽에 Many가 붙어있으면 설정된 해당 필드가 Java 컬렉션 타입일 것입니다.
뭔가 댓글 리스트도 전부 효율적으로 조회시켜주려면 지연 로딩 시켜줘야 할듯
근데 얘 댓글 리스트를 갖고 있는 게 아마 강의이려나
강의라면 댓글 리스트를 OneToMany로 갖고 있을 테니
디폴트로 되어있지만 Lazy로 세팅되어 있어야 하겠네여기서 지연 로딩이 된(아까 댓글리스트 같은) 엔티티를 조회할 때는 트랜잭션이 필수임(원래 조회할 땐 트랜잭션 필수가 아녔자나?)
내가 엔티티의 지연 로딩된 데이터를 조회하고 싶다면, 반드시 트랜잭션이 적용되어 있어야(영속성 컨텍스트가 적용되어 있어야) 한다.
지연 로딩도 영속성 컨텍스트의 기능 중 하나임
영속성 전이
userRepository.save(user);
foodRepository.save(food);
foodRepository.save(food2);
Robbie가 음식을 주문하기 위해서는 위 처럼 user, food, food2 모두 직접 save() 메서드를 호출하면서 영속화해야합니다.
JPA에서는 이를 간편하게 처리할 수 있는 방법으로 영속성 전이(CASCADE)의 PERSIST 옵션을 제공합니다.
- 영속성 전이란?
- 영속 상태의 Entity에서 수행되는 작업들이 연관된 Entity까지 전파되는 상황을 뜻합니다.
- 영속성 전이를 적용하여 해당 Entity를 저장할 때 연관된 Entity까지 자동으로 저장하기 위해서는 자동으로 저장하려고 하는 연관된 Entity에 추가한 연관관계 애너테이션에 CASCADE의 PERSIST 옵션을 설정하면됩니다.
@Test
@DisplayName("영속성 전이 저장")
void test2() {
// 고객 Robbie 가 후라이드 치킨과 양념 치킨을 주문합니다.
User user = new User();
user.setName("Robbie");
// 후라이드 치킨 주문
Food food = new Food();
food.setName("후라이드 치킨");
food.setPrice(15000);
user.addFoodList(food);
Food food2 = new Food();
food2.setName("양념 치킨");
food2.setPrice(20000);
user.addFoodList(food2);
// 별도의 음식 레포에 대한 세이브 과정이 없네
// 만약 영속성 전이를 쓰지 않았다면 작성된 댓글(강의 엔티티에서는 수정이려나)을 또 별개로 댓글 레포에 저장해야 되려나
// 그걸 간편하게 하려면 영속성 전이 써먹어서 그냥 강의 레포의 댓글리스트 관련해서 세팅만 하면 자동으로 댓글 레포에 저장되려나
userRepository.save(user);
}삭제도 마찬가지(이거 회원탈퇴, 댓글 삭제시 대댓글 삭제 등에 써먹을 수 있겠는데)
@Test
@Transactional
@Rollback(value = false)
@DisplayName("영속성 전이 삭제")
void test4() {
// 고객 Robbie 를 조회합니다.
User user = userRepository.findByName("Robbie");
System.out.println("user.getName() = " + user.getName());
// Robbie 가 주문한 음식 조회
for (Food food : user.getFoodList()) {
System.out.println("food.getName() = " + food.getName());
}
// Robbie 탈퇴
userRepository.delete(user);
}