NA & NULL
- NA 와 NULL 모두 결측 값을 의미한다.
NA(Not Available)
- 공간을 차지하는 결측값을 의미
- 비교할 값이 존재하지 않으므로 어떤 것과 비교를 하더라도 NA를 반환
즉, 연산을 할 때 에러를 띄우진 않는다. 모두 NA를 반환할 뿐.
NULL
- 공간을 차지하지 않는 결측값을 의미
NaN
- Not a Number : 음수의 제곱근을 구하려고 시도하는 것과 같은 경우에 오류와 함께 숫자가 아님을 반환한다.
산술 연산자
- 생각보다 헷갈리는 것들이 있다.
| 산술 연산자 | 내용 |
|---|---|
| + | 덧셈 |
| - | 뺄셈 |
| * | 곱셈 |
| / | 나눗셈 |
| %/% | 두 숫자의 나눗셈의 몫 |
| %% | 두 숫자의 나눗셈의 나머지 |
| ^, ** | 거듭제곱 |
| exp() | 자연상수의 거듭제곱 |
벡터
-
타입이 같은 여러 데이터를 하나의 행으로 저장하는 1차원 데이터 구조
-
c(1,2,3,4,5), c("a", "b", "c") c(1:3) = c(1,2,3)
행렬
-
2차원 구조를 가진 벡터
-
벡터의 성질을 가지므로 행렬에 저장된 모든 데이터는 같은 타입이어야 한다
m1 = matrix(c(2,3,4,5), nrow = 2); m1 # 기본적으로 열부터 들어간다결과

- byrow=True 조건을 주면 행으로 저장된다.
배열
-
3차원 이상의 구조를 갖는 벡터
-
array를 사용하여 배열을 만들 수 있으나 몇 차원 구조를 갖는지 dim옵션에 명시해야 한다.
-> 그렇지 않으면 1차원 벡터가 생성된다. -
2행 2열 행렬이 3차원으로 이루어진 배열
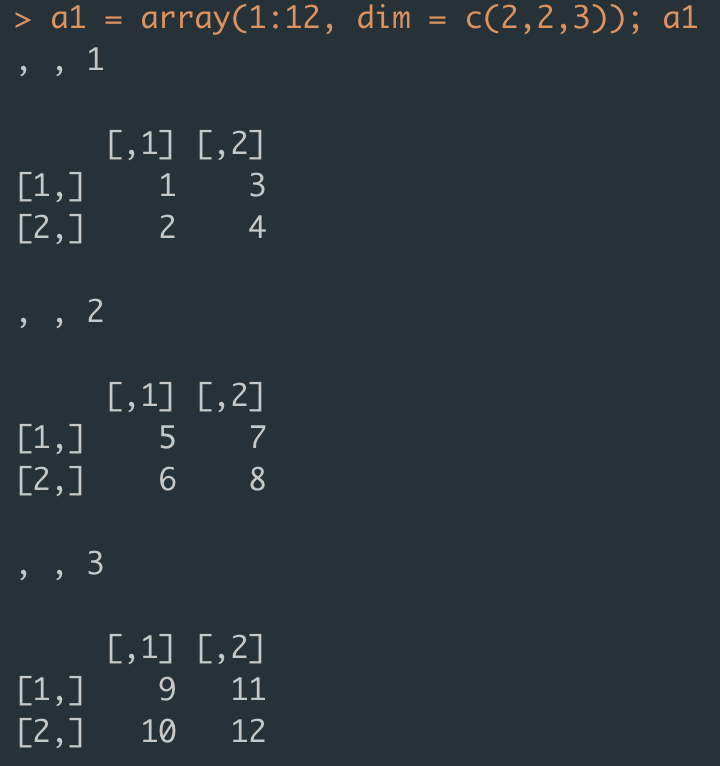
리스트
- 데이터 타입/구조에 상관없이 사용자가 원하는 모든 것을 저장할 수 있는 자료구조
첫 번째 성분 l1[[1]] : a, 숫자형 데이터
두 번째 성분 l1[[2]] : test1, 백터
세 번째 성분 l1[[3]] : m1, 2행 2열 행렬
네 번째 성분 l1[[4]]: a1, 2행 2열 행렬이 3차원으로 이루어진 배열
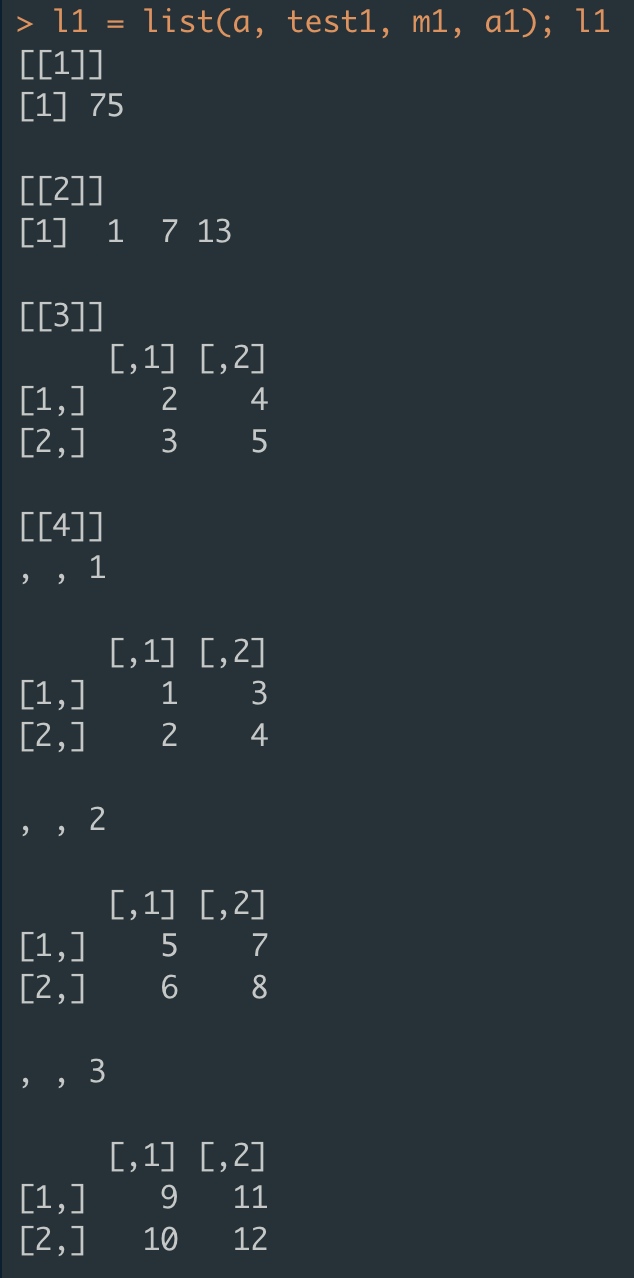
- 리스트의 각 성분들을 인덱싱하는 방법
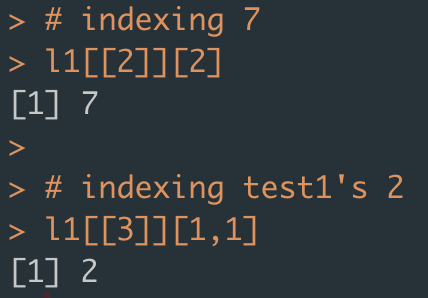
데이터 프레임
-
데이터 분석을 위한 2차원 구조
-
행렬과 같은 모양이지만 여러 개의 벡터로 구성, 각 열은 서로 다른 타입의 데이터를 가질 수 있다.
R 내장 함수
- paste() : 문자열을 이어 붙인다.

-
seq() : 시작값, 끝값, 간격으로 수열을 생성한다.
-
rep() : 주어진 데이터를 일정 횟수만큼 반복한다.
-
rm() : 대입 연산자에 의해 생성된 변수를 삭제한다.
-
ls() : 현재 생성된 변수들의 리스트를 보여준다.
-
print() : 값을 콘솔창에 출력한다.
날짜를 다루는 함수
-
format(Sys.Date(), ‘%a’) : 요일조회
-
format(Sys.Date(), ‘%b’) : 축약된 월 이름 조회 (fab)
-
format(Sys.Date(), ‘%B’) : 전체 월 이름 조회 (faburary)
-
format(Sys.Date(), ‘%d’) : 두자리 숫자의 일조회
-
format(Sys.Date(), ‘%m’) : 두자리 숫자의 월조회
-
format(Sys.Date(), ‘%y’) : 두자리 숫자의 연도 조회
-
format(Sys.Date(), ‘%Y’) : 네자리 숫자의 연도 조회
데이터프레임에 활용되는 함수들
-
data.frame(벡터, 벡터, 벡터,…) : 벡터들을 통해 데이터프레임 생성. 이때 벡터들은 서로 다른 타입일 수 있음
-
rbind(df1, df2) : 두 데이터프레임을 행으로 결합
-
cbind(df1, df2) : 두 데이터프레임을 열로 결합
-
new[newdata$a=1]: new 데이터프레임에서 a=1인 값만 조회
new[new$변수1>4 & new$변수2 > 5, c(변수3, 변수4)]: 데이터셋의 변수1과 변수2가 각각 4보다 크고 5보다 큰 조건을 만족하는 경우 변수3과 변수4만을 조회 -
subset(df, select=열이름) : df에서 열이름만 선택
-
subset(df, select=c(열이름, 열이름,…,열이름) : df에서 나열된 열을 모두 선택
-
subset(df, select=열이름, subset=(조건)) : 조건에 맞는 행의 열이름만 선택
-
subset(df, select=-”열이름") : 해당 열만 제거
-
colnames(df)=newnames : df의 열이름 변경
-
rownames(df)=newnames : df의 행이름 변경
-
NA_cleaning <- na.omit(df) : df에 NA가 들어있는 행 삭제
