오늘 배운 것들
선형대수학이 왜 필요한가?
수학에서 쓰이는 표현을 구체화하여 선형화시킨 후, 그 선형화된 관계를 숫자로 계산하는 과정에서 선형대수는 필연적이다.
스칼라: 크기 벡터: 방향+크기
벡터를 통해 알 수 있는 것 data의 location
차원(Dimension)
차원이 늘어나면 좋은점
- 입체감이 늘어난다.
- data를 보는 perspective가 다양해진다.
차원을 줄이는 이유
- overfitting 방지를 위해서(accuracy가 떨어짐)
- 모델 간단하게 하여 안정적 결과를 위해서
- 시간 복잡도, 공간복잡도를 줄어주어 효율적으로 만든다.
ex) PCA, Matrix Factorization(행렬 인수분해)
내적 vs 외적 (벡터일 때)
내적의 결과값은 스칼라이고 외적의 결과 값은 벡터이다.
내적곱을 하게되면 차원이 다 없어지고 스칼라값만 남게 되는데,
차원이 다 없어지는 것은 데이터 분석에서 기피한다.
신경망을 구현하기 위해 행렬 연산을 표현해야 하는데, 이때 벡터의 외적곱 연산을 알고 있어야 한다.
내적곱
= inner product
= dot product
= scalar product

A @ B or numpy.dot(A,B)
외적곱(⊗)
= vector product
= cross product


numpy.outer(A,B)
행렬곱 vs 아다마르곱(요소곱) (행렬일 때)
일반 행렬곱은 m x n과 n x p의 꼴의 두 행렬을 곱하지만, 아다마르 곱은 m x n과 m x n의 꼴의 두 행렬을 곱한다.
행렬곱
A @ B
아다마르곱(∘)


A*B
Norms

머신러닝에서 L2 Norm(유클리디안 디스턴스/square root error)를 쓰는 이유
절대적인 값만 양수로 바꿔주는 L1 Norm(맨허튼 디스턴스)에 비해, L2 Norm은 제곱을 해주기 때문에 error의 미세한 차이를 극대화해준다.
머신러닝 모델에서는 절대값보다 square root error 형식을 많이 쓴다.
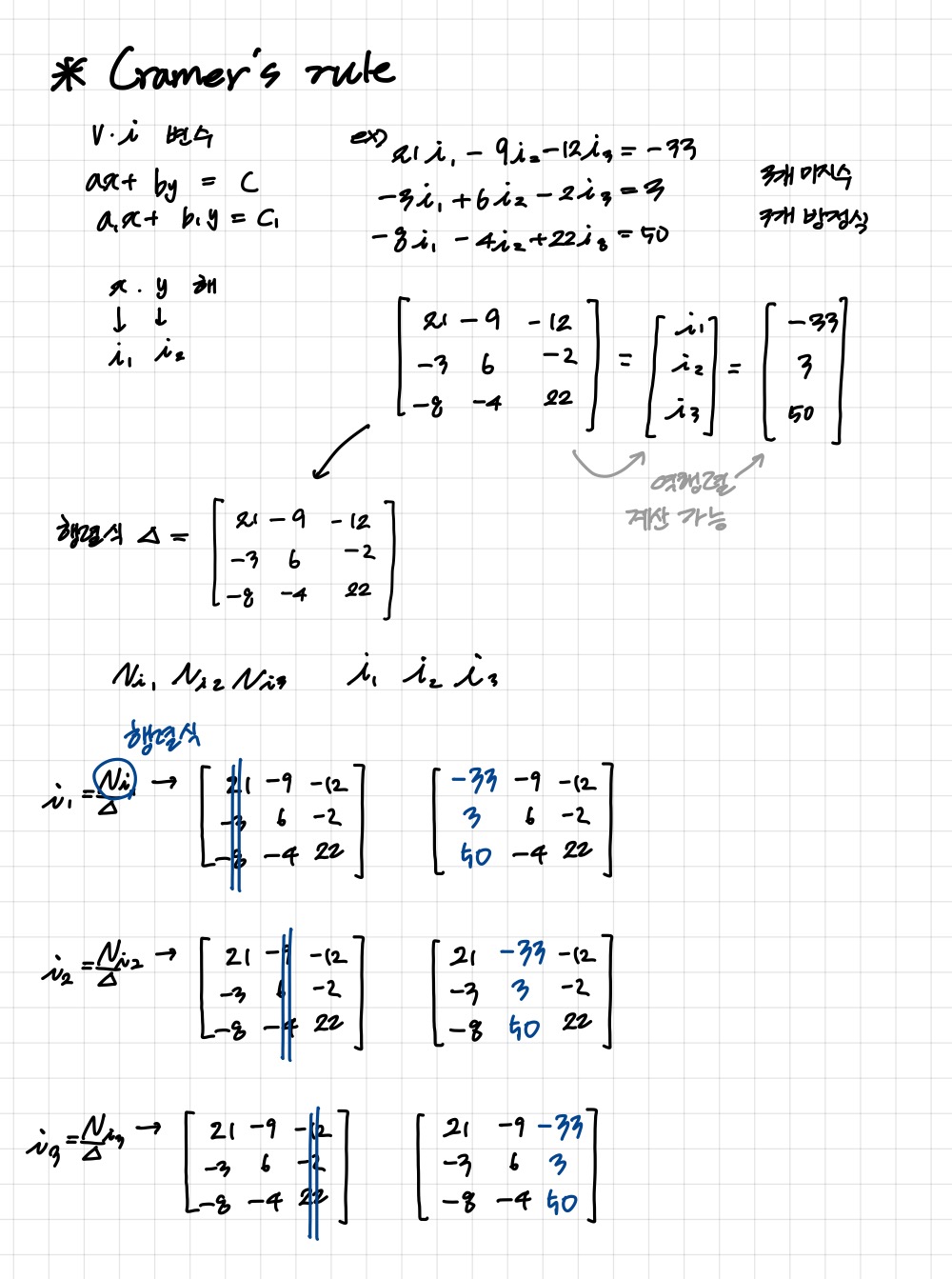
Cramer's rule