쿠버네티스를 작년 초에 살짝 건드려보기만 한 정도라, 다시 리마인드겸 복습차 블로그를 작성하게 되었다. 추후 spark + kubernetes에 대해 지속적으로 공부해 나갈 예정이다.
🚩쿠버네티스 아키텍처
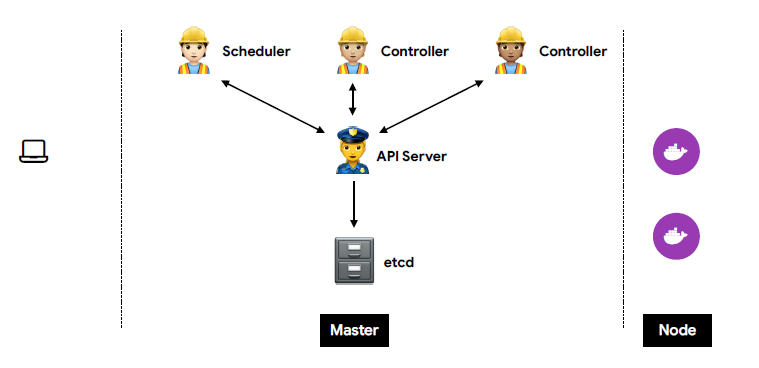
1. Master 상세
🟥 etcd
- 모든 상태와 데이터를 저장
- 분산 시스템으로 구성하여 안정성을 높임 (고가용성)
- 가볍고 빠르면서 정확하게 설계 (일관성)
- key-value 형태로 데이터를 저장
- TTL(time to live), watch와 같은 다양한 기능 제공
🟧 API server
- 상태를 바꾸거나 조회를 하는 역할을 하며 etcd와 유일하게 통신하는 모듈이
- REST API 형태로 제공, 권한을 체크하여 적절한 권한이 없을 경우 요청을 차단
- 관리자 요청 뿐 아니라 다양한 내부 모듈과 통신
- 수평으로 확장되도록 디자인
🟨 Scheduler
- 새로 생성된 Pod를 감지하고 실행할 노드를 선택
- 노드의 현재 상태와 Pod의 요구사항을 체크
- 노드에 라벨 부여
🟩 Controller
- 논리적으로 다양한 컨트롤러가 존재 (복제 컨트롤러, 노드 컨트롤러, 엔드포인트 컨트롤러 ...)
- 끊임 없이 상태를 체크하고 원하는 상태를 유지
- 복잡성을 낮추기 위해 하나의 프로세스로 실행
2. Node 상세
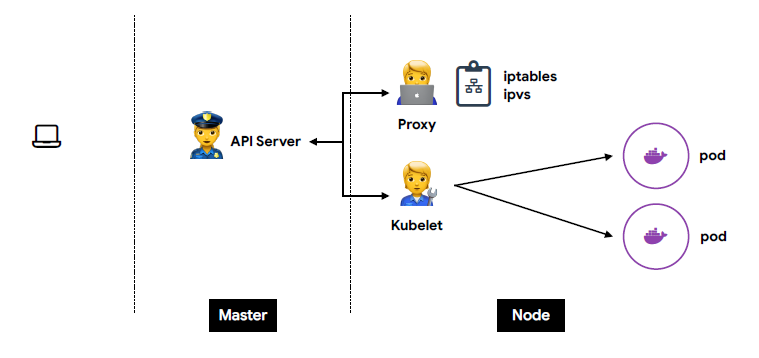
🟥 kubelet
- 각 노드에서 실행
- Pod을 실행/중지하고 상태를 체크
- CRI(Container Runtime Interface)
-docker
-Containerd
-CRI-O
-...
🟧 proxy
- 네트워크 프록시와 부하 분산 역할
- 성능상의 이유로 별도의 프록시 관리 프로그램 대신 iptables 또는 IPVS를 사용 (설정만 관리)
🚩쿠버네티스 오브젝트
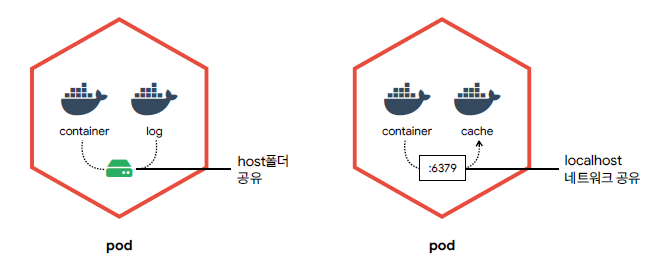
🟥 Pod
- 가장 작은 배포 단위
- 전체 클러스터에서 고유한 IP를 할당
- 여러개의 컨테이너가 하나의 Pod에 속할 수 있음
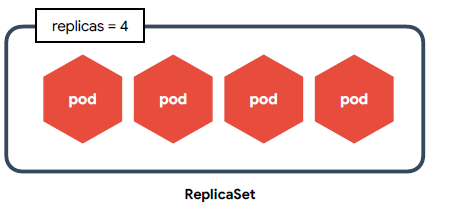
🟧 ReplicaSet
- 여러개의 Pod을 관리
- 새로운 Pod은 Template을 참고하여 생성
- 신규 Pod을 생성하거나 기존 Pod를 제거하여 원하는 수(Replicas)를 유지
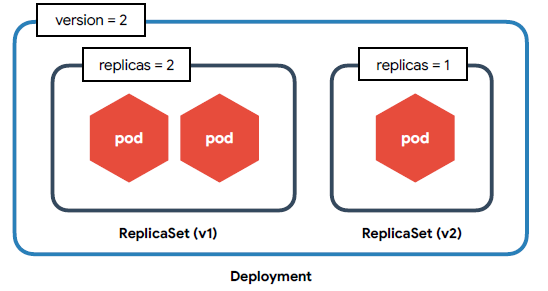
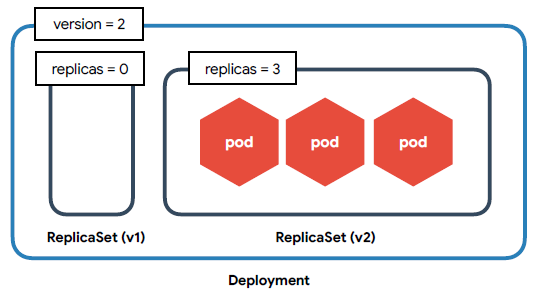
🟨 Deployment
- 내부적으로 ReplicaSet을 이용 -> 버전 관리
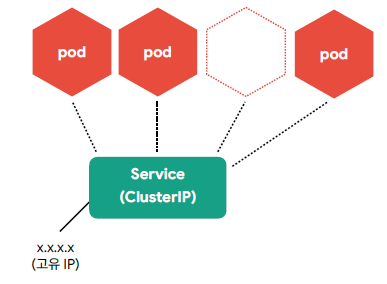
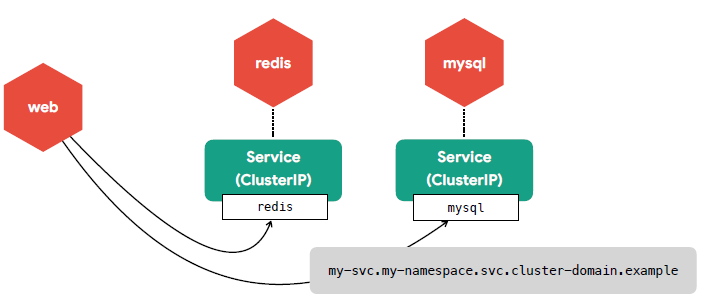
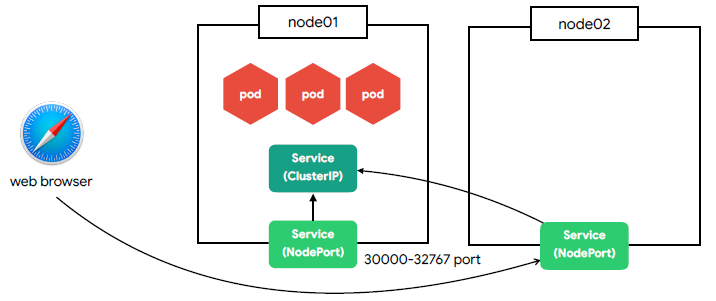
🟩 Service - ClusterIP
- 클러스터 내부에서 사용하는 프록시
- Pod은 동적이지만 서비스는 고유 IP를 가짐
- 클러스터 내부에서 서비스 연결은 DNS를 이용
🟦 Service - NodePort
- 노드(host)에 노출되어 외부에서 접근 가능한 서비스
- 모든 노드에 동일한 포트로 생성
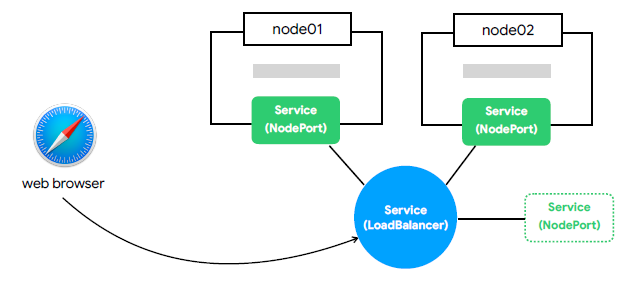
🟪 Service - LoadBalancer
- 하나의 IP주소를 외부에 노출
- 균등한 배분, 접근 ...
🟫 그외
- Ingress - 도메인 또는 경로별 라우팅 (Nginx, HAProxy, ALB ...)
- Volume - Storage(EBS, NFS ...)
- Namespace - 논리적인 리소스 구분
- ConfigMap/Secret - 설정
- ServiceAccount - 권한 계정
- Role/ClusterRole - 권한 설정 (get, list, watch, create ...)
🚩전반적인 일반 구성
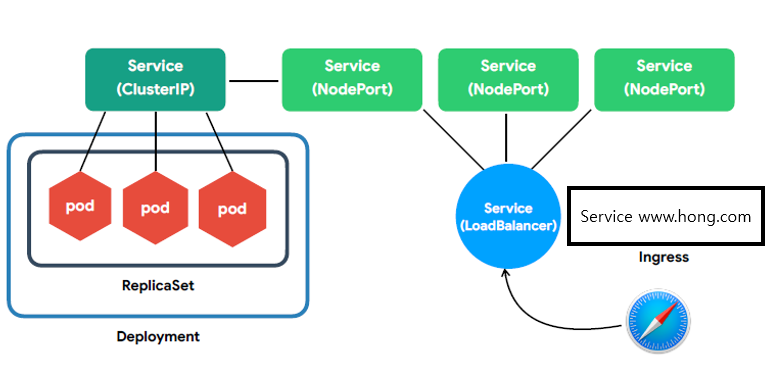

열심히 살자