최근 스프링 부트 공부를 하다가 데이터 베이스 관리 기법에 대해 궁금증이 생겼다.
1. 데이터베이스 이중화
시스템 오류로 인한 데이터베이스 중단이나 물리적인 손상 발생시 이를 복구하기 위해 데이터 베이스를 복제하여 관리하는 것.
- 데이터베이스 이중화를 수행하면 하나 이상의 데이터 베이스가 항상 같은 상태를 유지하므로 데이터베이스에 문제가 발생하면 복제된 데이터베이스를 이용하여 즉시 문제를 해결 할 수 있음
- 여러 개의 데이터베이스를 동시에 관리하므로 사용자가 수행하는 작업이 데이터베이스 이중화 시스템에 연결된 다른 데이터베이스에도 동일하게 적용됨
- 데이터 베이스 이중화는 애플리케이션을 여러 개의 데이터베이스를 분산시켜 처리하므로 데이터베이스의 부하를 줄일 수 있음
- 데이터베이스 이중화를 이용하면 손 쉽게 백업 서버를 운영할 수 있음.
2. 데이터베이스 이중화의 분류
데이터베이스 이중화는 변경 내용의 전달 방식에 따라 Eager와 Lazy기법으로 나뉜다.
- Eager 기법: 트랜잭션 수행 중 데이터 변경이 발생하면 이중화된 모든 데이터베이스에 즉시 전달하여 변경 내용이 즉시 적용되도록 하는 기법
- Lazy 기법: 트랜잭션 수행이 종료되면 변경 사실을 새로운 트랜잭션에 작성하여 각 데이터베이스에 전달하는 기법으로, 데이터베이스마다 새로운 트랜잭션이 수행되는 것으로 간주
3. 데이터베이스 이중화 구성 방법
데이터베이스의 이중화 구성 방법에는 활동-대기(Active-Standby) 방법과 활동-활동(Active-Active) 방법이 있다.
- 활동-대기(Active-Standby) 방법: 한 DB가 활성 상태로 서비스하고 있으면 다른 DB는 대기하고 있다가 활성 DB에 장애가 발생하면 대기 상태에 있던 DB가 자동으로 모든 서비스를 수행
- 활동-활동(Active-Active) 방법: 두 개의 DB가 서로 다른 서비스를 제공하다가 둘 중 한쪽 DB에 문제가 발생하면 나머지 다른 DB가 서비스를 제공
4. 클러스터링(Clustering)
클러스터링은 두 대 이상의 버서를 하나의 서버처럼 운영하는 기술
-
클러스터링은 서버 이중화 및 공유 스토리지를 사용하여 고가용성을 제공, 클러스터링에는 고가용성 클러스터링과 병렬 처리 클러스터링이 있음
-
고가용성 클러스터링: 하나의 서버에 장애가 발생하면 다른 노드(서버)가 받아 처리하여 서비스 중단을 방지하는 방식
-
병렬 처리 클러스터링: 전체 처리율을 높이기 위해 하나의 작업을 여러개 의 서버에서 분산하여 처리하는 방식
5. Query-off loading
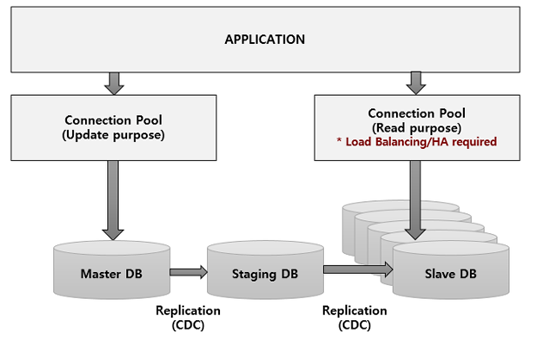
데이터 베이스에서 update 트랜잭션과 Read 트랜잭션을 구분하여 DB처리량을 증가시키는 기술
- Master DB(CDC수행) -> Staging DB(경유지) -> Slave DB(Read only, HA) 로 구성
- Application에서 쓰기 로직과 읽기 로직을 분리하여야 하며 분리된 로직은 쓰기DB로 접근하기 위한 DB Connection과 읽기DB로 접근하기 위한 DB Connection을 별도로 관리하여야 함
- 일반적으로 Appication 서버에서 Connection Pool을 관리하기 때문에 읽기 DB의 경우 N개의 Slave DB로 접근하기 때문에 Load Balancing을 제공하여야 함
6. CDC(Change Data Capture)
-
DBMS는 공통적으로 Create/Update/Delete와 같은 쓰기 작업을 수행할 때 데이터를 저장하기 전에 request 를 BackLog에 저장한다. (Backlog는 일반적으로 local 파일) 이 로그파일은 실제 데이터를 쓰기 전에 에러가 발생하였을 때 Restart를 하면서 BackLog를 읽어 복구하는데 사용
-
CDC는 Backlog를 이용하여 SourceDB에 Backlog를 읽어서 TagetDB에 replay 하는 방식으로 작동한다. 따라서 Master DB에서 Staging DB로 데이터를 복사할 때 Master DB가 수행하는 내용은 없음
CDC를 kafka connect를 활용하여 구현
-
kafka connect: 아파치 카프카의 일부로 포함되어 있으며, 카프카와 데이터스토어 간에 데이터를 이동하기 위해 확장성과 신뢰성 있는 방법을 제공
-
여러 개의 작업 프로세스(worker process)들로 실행된다. 그리고 컨넥터 플러그인을 작업 프로세스에 설치한 후 RestAPI를 사용해서 특정 구성으로 실행되는 컨넥터를 구성하고 관리한다.
-
컨넥터에서 소스(source) 컨넥터와 싱크(sink) 컨넥터 두 종류가 있다.
-
소스 컨넥터: 소스 시스템으로 부터 데이터를 읽어서 컨넥트 데이터 객체로 work process에 제공
-
싱크 컨넥터: work process로부터 컨넥트 데이터 객체를 받아서 대상 시스템에 쓴다.
(컨버터를 사용해서 다양한 형식의 데이터 객체들을 저장할 수 있음(JSON등))
-- 예시 --
- 필자는 connect distributed 모드했으며 connect-distributed.properties 파일에 connector가 사용할 plugin path를 지정해줘야 한다. debezium-connector-mysql를 사용했으며 아래 명령어로 실행한다.
bin/connect-distributed.sh config/connect-distributed.properties
- connector 실행 확인
# connector 기본 포트 8083 curl -s localhost:8083 # 결과 {"version":"3.0.0","commit":"8cb0a5e9d3441962","kafka_cluster_id":"Gdsb3jSNTvSCBgB-8jixlw"}
- 사용할 수 있는 플러그인 확인
curl --location --request GET 'localhost:8083/connector-plugins' # 결과 [{"class":"io.debezium.connector.mysql.MySqlConnector","type":"source","version":"1.5.4.Final"}, {"class":"org.apache.kafka.connect.file.FileStreamSinkConnector","type":"sink","version":"3.0.0"}, {"class":"org.apache.kafka.connect.file.FileStreamSourceConnector","type":"source","version":"3.0.0"}, {"class":"org.apache.kafka.connect.mirror.MirrorCheckpointConnector","type":"source","version":"1"}, {"class":"org.apache.kafka.connect.mirror.MirrorHeartbeatConnector","type":"source","version":"1"}, {"class":"org.apache.kafka.connect.mirror.MirrorSourceConnector","type":"source","version":"1"}]
- REST API로 컨넥터 등록을 할 수 있으며 json으로해 봤다.
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d '{ "name": "inventory-connector", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": {dbserver}, "database.port": "3306", "database.user": {user}, "database.password": {password}, "database.server.id": "18405", "database.server.name": "pettit", "database.include.list": "pettit", "database.history.kafka.bootstrap.servers": "localhost:9092", "database.history.kafka.topic": "dbhistory.pettit" } }'
- connector 등록됨과 동시에 topic도 알아서 생성해준다.
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
- 데이터베이스 변경을 하면 해당 topic에 알아서 메시지를 보낸다
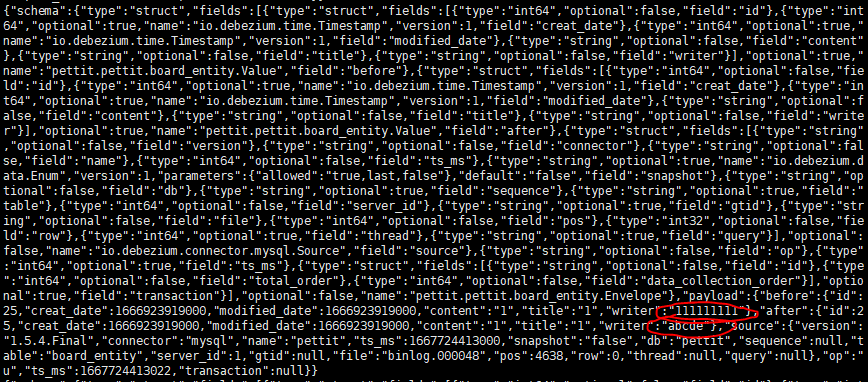
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic pettit.pettit.board_entity --from-beginning
- 실제로 반영되는지 확인해보기
- 1111111로 표기된 것을 abcde로 변경해보았다
- 실제로 connector log에 basesource에서 task가 감지됨을 보여준다
- 해당 토픽을 읽어보면, 보기는 힘들지만 바뀐 것에 대한 정보가 표시되는 것을 볼 수 있다.