이전 페이지: [Oracle] Tablespace와 Data File 관리하기
다음 페이지: [Oracle] Oracle 메모리 관리 기법들
1. Oracle Block 개요
볼펜 100자루를 옮길 때 1자루 씩 옮기게 되면 많은 노력을 요하지만, 박스에 담아 한 번에 옮기게 되면 훨씬 빨리 옮길 수 있습니다. 여기서 Data들의 박스의 역할을 하는 것이 Block입니다.
Oracle에서는 사용자가 입력한 데이터를 디스크에 저장할 때나 저장되어 있는 데이터를 메모리로 복사해 올 때 가장 작은 단위인 Block 단위로 작업합니다.
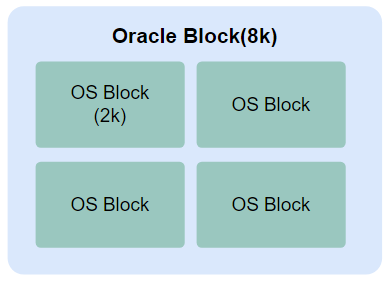
Oracle Block은 OS Block을 1개 이상 합쳐서 생성하게 되며, DB_BLOCK_SIZE로 지정됩니다. DB_BLOCK_SIZE는 CREATE DATABASE할 때 한 번 지정이 되면 그 값은 Database를 재생성하기 전에는 변경할 수 없고, 이 파라미터에서 지정되는 크기 값을 Standard Block Size라고 합니다.
Block의 크기는 최소 2KB부터 4, 8, 16, 32KB가 제공됩니다. OS 종류에 따라 달라지며 64KB를 지원하는 OS도 있습니다.
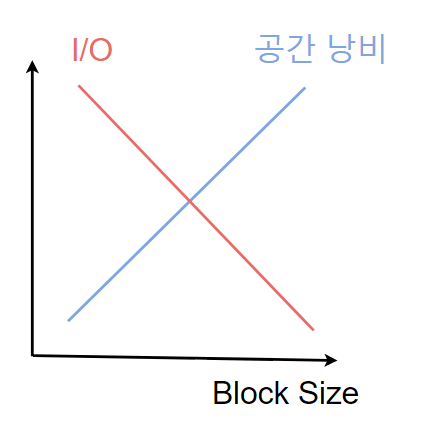
Block Size가 커질 수록 한 번에 담을 수 있는 데이터의 양이 많아져 디스크 I/O는 줄어드나, 데이터가 적을 경우 Block에 공간 낭비가 많이 생길 수 있습니다.
Block Size는 Tablespace를 생성할 때 다르게 지정해서 사용할 수 있습니다. 단, Standard Block Size 외의 Tablespace를 생성할 경우 DB Buffer Cache에도 해당 Block 사이즈 만큼의 공간을 미리 할당해 두어야 에러가 발생하지 않습니다.
-- 에러 발생
SQL> create tablespace test_4k
2 datafile '/ORA19/app/oracle/oradata/ORACLE19/test01.dbf' size 5M
3 blocksize 4k;
create tablespace test_4k
*
ERROR at line 1:
ORA-29339: tablespace block size 4096 does not match configured block sizes
-- DB Buffer Cache에 미리 공간을 할당합니다.
SQL> alter system set db_4k_cache_size=10M;
System altered.
SQL> create tablespace test_4k
2 datafile '/ORA19/app/oracle/oradata/ORACLE19/test01.dbf' size 5M
3 blocksize 4k;
Tablespace created.
2. Oracle Data Block 상세 구조
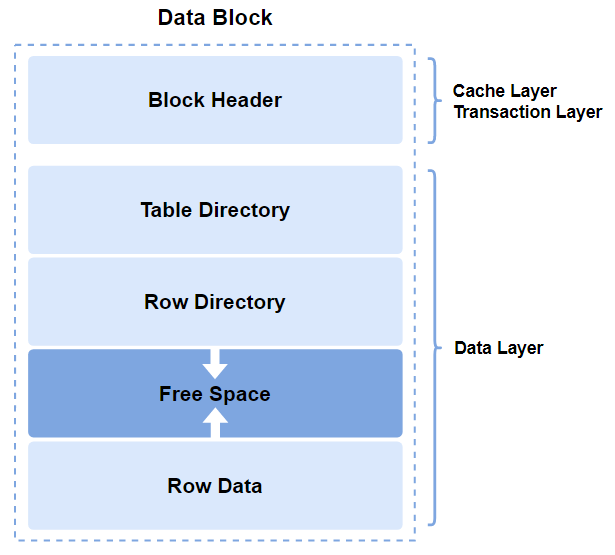
위 그림은 Oracle에서의 Data Block의 구조를 알려주고 있습니다. Block 의 가장 윗부분에는 Block의 Header 부분이 위치하고 있고 Block Header는 Cache Layer와 Transaction Layer로 나누어져 있습니다. 아래는 Data Layer로 Table Directory, Row Directory, Free space, Row data로 나뉘어져 있고, Free space와 Row data에 데이터가 직접 저장됩니다.
각 부분의 크기를 조회하는 방법은 아래와 같습니다.
SQL> select component, type, description, type_size
2 from v$type_size
3 where component in ('KCB', 'KTB');
COMPONEN TYPE DESCRIPTION TYPE_SIZE
-------- -------- -------------------------------- ----------
KCB KCBH BLOCK COMMON HEADER 20
KTB KTBIT TRANSACTION VARIABLE HEADER 24
KTB KTBBH TRANSACTION FIXED HEADER 48
KTB KTBBH_BS TRANSACTION BLOCK BITMAP SEGMENT 8
Block Header
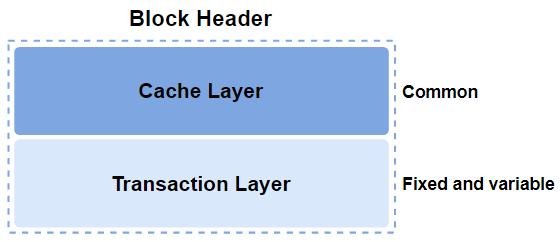
Cache Layer는 v$type_size에서 KCBH로 조회됩니다.
Cache Layer에는 다음과 같은 주요 정보가 들어갑니다.
- Data Block Address(DBA)
- Block Type(ex. Table, Index, Undo, ...)
- Block Format(ex. v6, v7, v8, ...)
- System Change Number(SCN: 복구작업 등에 사용됨)
직접 dump를 수행해서 확인해보겠습니다.
SQL> alter session set tracefile_identifier='BBB';
Session altered.
SQL> alter system dump
2 datafile '/ORA19/app/oracle/oradata/ORACLE19/system01.dbf' block 2;
System altered.
SQL> !
$ cd /ORA19/app/oracle/diag/rdbms/oracle19/oracle19/trace
$ ls *BBB*
oracle19_ora_14320_BBB.trc oracle19_ora_14320_BBB.trm
$ vi oracle19_ora_14320_BBB.trc
(중간 생략)
(이하 생략)위 내용에서 rdba는 Relative Data Block Address, seq는 Sequence Number 입니다. tail은 Block의 마지막 4bytes와 관련이 있으며, 해당 Block의 문제유무를 체크하는 checksum 용도로 사용됩니다.

Transaction Layer는 fixed와 variable로 나뉩니다.
먼저 fixed(고정) 영역은 v$type_size에서 KTBBH로 조회됩니다.
fixed(고정) 영역에는 다음과 같은 정보가 들어갑니다.
- Block Type
- 마지막으로 수행된 Block Cleanout 시간
- ITL Entries 정보
- Free List Link 정보
- Free space Lock 정보
variable(가변) 영역은 v$type_size에서 KTBIT로 조회됩니다.
variable(가변) 영역에는 다음과 같은 정보가 들어갑니다.
- 해당 Block에 있는 Row를 변경하길 원하는 ITL 관련 정보
ITL(Interested Transaction List): 대기자 명단입니다. Oracle에서 특정 Block에 데이터를 변경해야 할 경우 해당 Block의 사용자 명단에 자신의 정보를 적고 변경을 해야 합니다. 만약 다른 사용자가 그 Block을 수정하고 있어서 진입하지 못하는 상황이라면 대기자 명단(ITL)에 자신의 정보를 적고 자신의 순서가 될 때까지 기다려야 합니다.
Data Layer
Row Directory(Row Index)에는 다음과 같은 정보가 들어 있습니다.
- 첫 번째 빈 공간의 포인터 주소
- 빈 공간의 시작과 끝의 offset 주소
- 사용 가능한 빈 공간의 양
만약 Block 에 데이터가 insert될 경우 데이터가 우선 가운데(Free space)로 입력된 후 실제 데이터는 Row data로, 데이터의 정보는 Row Directory로 기록됩니다.
데이터가 update될 경우 일단 먼저 기존 공간을 재활용하려고 시도합니다. 그런데 데이터의 용량이 기존 공간을 초과하고, 비어있는 공간이 연속적이지 않다면 kdbcps() 함수를 호출해서 공간을 압축합니다. 예를 들어, 1, 2, 3, 4, 5 총 5건의 데이터가 있고, 각 데이터의 크기는 1byte라고 합시다. 그런데 2, 4의 데이터가 삭제된 상황에 update가 일어났고, 데이터의 크기가 2byte라면 2의 공간만으로는 데이터를 입력할 수 없습니다. 4도 함께 써야하는데 2, 4는 불연속적입니다. 이때 kdbcps() 함수가 동작해 1, 3, 5를 서로 모으고, 나머지 빈 공간을 2byte로 합쳐서 데이터를 입력합니다.
3. PCTFREE / PCTUSED
PCTFREE
해당 Block에 입력되어 있는 데이터들이 Update될 경우를 대비해서 예약을 해두는 공간입니다. 만약 이름이 3글자였던 사람이 5글자로 변경되었는데 해당 Block에 여유 공간이 없을 경우 다른 Block으로 Row Migration이 발생해서 성능이 저하되기 때문에 여유 공간을 미리 마련해두는 것입니다.
이 값은 해당 Block 크기의 %로 지정합니다. PCTFREE=20으로 지정한다면 전제 Block 크기의 20%를 update만을 위한 공간으로 지정하고, 이 공간에는 데이터가 insert되지 않습니다. 이 공간을 제외하고 데이터가 다 차게 되면 이 Block은 더 이상 빈 공간이 없는 Dirty Block 상태가 됩니다.
PCTUSED
만약 Block에 있는 Row가 삭제되어서 빈 공간이 생겼다 해도 Oracle에서는 이 Block을 바로 재사용하지 않습니다. 비어있는 공간이 특정 값이 될 때까지 기다렸다가 이 Block을 재사용합니다. 여기서 특정 값을 PCTUSED입니다.
이러는데는 이유가 있습니다. Oracle에서는 비어있는 공간이 있는 Block은 Free List에, 빈 공간이 없는 Block은 Dirty List에 기록하는데, 데이터 1건을 지울 때마다 Free List와 Dirty List가 업데이트 되어야 한다면 그 부하가 심해지기 때문입니다.
PCTUSED=40이라면 Dirty Block의 Free space가 Block 크기의 40%가 되었을 때 Free Block이 된다는 의미입니다.
이 값들은 Tablespace가 ASSM(Automatic Segment Space Management) 방식인지 MSSM(Manual Segment Space Management) 방식인지에 따라 그 역할이 달라집니다. MSSM 방식은 Free List를 사용해서 FLM(Free List Management)라고도 하며, 테이블 생성 시 PCTFREE, PCTUSED를 모두 사용하지만, ASSM은 PCTFREE만 사용합니다.
4. Row Data / Row Chaining / Row Migration
Block에 데이터가 입력될 때는 Row 단위로 특정한 형식을 가지게 됩니다.
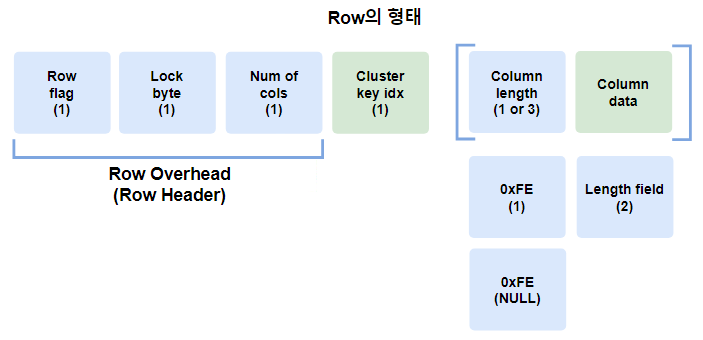
Row를 크게 나누면 Row Overhead 부분과 Column Data 부분입니다.
Row Overhead 부분에는 해당 Row에 동시에 트랜잭션이 일어나는 것을 막기 위한 Lock 정보 부분(Lock byte)과 해당 Row Piece에 들어있는 Column Data의 개수(Num of cols) 등이 기록됩니다.
Column Data에는 실제 데이터가 저장됩니다.
Row Chaining
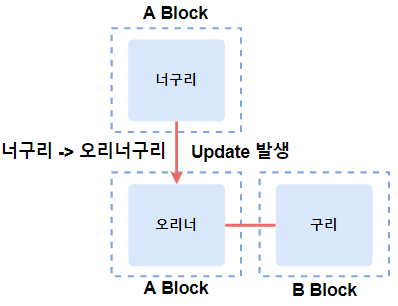
데이터가 너무 길어서 하나의 Row에 다 기록할 수 없을 경우 다른 Block에 연결해서 저장합니다.
예를 들어 A Block에 1KB가 남았는데 만약 2KB의 정보가 들어올 경우 A Block에 1KB를 먼저 저장하고 B Block에 나머지 1KB를 저장합니다. 이를 Row Chaining(로우 체이닝)이라고 부릅니다.
Row Migration
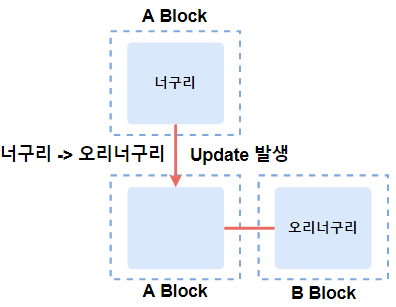
특정 Block에 위치하던 Row가 Update 등의 이유로 해당 Block에 공간이 부족해서 다른 공간으로 이사를 가는 것을 의미합니다. 새로운 Block으로 잘 찾아올 수 있도록 하기 위해 이전 Block의 Row에 신규 Block의 포인터 주소를 남겨둡니다. 그래서 이전 Block으로 찾아오는 액세스도 신규 Block으로 갈 수 있습니다.
Row Chaining, Row Migration의 문제점
두 가지 경우 모두 성능 관점에서 좋진 않습니다.
Row Chaining의 경우 Block의 크기보다 큰 데이터가 들어와서 생기는 경우가 많으므로 만약 Row Chaining 현상이 많은 경우 Block의 크기를 크게 생성하는 것이 좋습니다. 하지만 Block의 너무 크기가 커진다면 wait 현상이 많이 발생할 수 있겠죠.
Row Migration의 경우 PCTFREE의 값을 많이 주거나 테이블을 재생성(Reorg)하는 등의 작업으로 Row Migration이 일어나는 경우를 줄여야 합니다. 하지만 PCTFREE를 많이 주면 공간 낭비가 심해지겠죠.
그래서 성능을 잘 관리하기 위해 적절하게 조정해주며 관리하는 것이 무엇보다 중요합니다.
Row Chaining 확인하기
SQL> select owner, table_name, tablespace_name from dba_tables
2 where owner='SCOTT'
3 and table_name='EMP';
SQL> exec dbms_stats.gather_tabel_stats('SCOTT', 'EMP');
SQL> select num_rows, chain_cnt
2 from dba_tables
3 where table_name='EMP';
위에서 chain_cnt 부분이 Row Chaining 값입니다. 만약 이 값이 높다면 해당 테이블에 Row Chaining이 많이 발생하고 있다는 의미이므로 해당 테이블이 저장되어 있는 Tablespace의 Block 크기를 재조정하거나 Table Reorg를 심각하게 고려해야 합니다.
Table Reorg 방법은 Table을 move하면 간단히 해결됩니다. 명령어는 아래와 같습니다.
SQL> alter table scott.emp move tablespace example;
SQL> select owner, table_name, tablespace_name from dba_tables
2 where owner='SCOTT'
3 and table_name='EMP';
꼭 다른 Tablespace로 move 해주어야 하는 것은 아닙니다. 현재 EXAMPLE Tablespace에 있지만 move tablespace example로 지정해도 reorg가 동일하게 적용됩니다.
위와 같이 기존에 USERS에 있던 EMP Table을 EXAMPLE Tablespace로 이동시키게 되면 해당 Table에 있던 Index가 모두 사용 못함(UNUSABLE) 상태로 변경되므로 반드시 해당 Index까지 rebuild 작업을 해주어야 합니다.
SQL> exec dbms_stats.gather_table_stats('SCOTT','EMP');
SQL> select table_name, index_name, status
2 from dba_indexes
3 where table_name='EMP';
SQL> alter index scott.pk_emp rebuild;
SQL> exec dbms_stats.gather_table_stats('SCOTT','EMP');
SQL> select table_name, index_name, status
2 from dba_indexes
3 where table_name='EMP';
SQL> alter table scott.emp allocate extent (size 128k);
SQL> analyze table scott.emp compute statistics;
SQL> select num_rows, blocks, empty_blocks as empty
2 from dba_tables
3 where table_name='EMP';
위의 방법은 FLM 기반일 경우 많이 사용했던 정보 조회 방식이고, ASSM의 특징인 Block별 사용량은 확인할 수 없습니다. Block별 사용량을 조회하려면 아래와 같은 방식으로 수행합니다.
SQL> create table scott.assm
2 ( no number,
3 name varchar2(10),
4 addr varchar2(10));
SQL> begin
2 for i in 1..10000 loop
3 insert into scott.assm
4 values (i, dbms_random.string('A',9), dbms_random.string('B',9));
5 end loop;
6 commit;
7 end;
8 /
SQL> select count(*) from scott.assm;
SQL> set serveroutput on;
SQL> declare
2 p_owner varchar2(30) := 'SCOTT';
3 p_segname varchar2(30) := 'ASSM';
4 p_segtype varchar2(30) := 'TABLE';
5 p_partition_name varchar2(30) := null;
6 l_total_blocks number;
7 l_total_bytes number;
8 l_unused_blocks number;
9 l_unused_bytes number;
10 l_last_used_extent_file_id number;
11 l_last_used_extent_block_id number;
12 l_last_used_block number;
13 l_unformatted_blocks number;
14 l_unformatted_bytes number;
15 l_fs1_blocks number;
16 l_fs1_bytes number;
17 l_fs2_blocks number;
18 l_fs2_bytes number;
19 l_fs3_blocks number;
20 l_fs3_bytes number;
21 l_fs4_blocks number;
22 l_fs4_bytes number;
23 l_full_blocks number;
24 l_full_bytes number;
25 BEGIN
26 /*blocks space*/
27 DBMS_SPACE.SPACE_USAGE(
28 segment_owner => p_owner,
29 segment_name => p_segname,
30 segment_type => p_segtype,
31 partition_name => p_partition_name,
32 unformatted_blocks => l_unformatted_blocks,
33 unformatted_bytes => l_unformatted_bytes,
34 fs1_blocks => l_fs1_blocks,
35 fs1_bytes => l_fs1_bytes,
36 fs2_blocks => l_fs2_blocks,
37 fs2_bytes => l_fs2_bytes,
38 fs3_blocks => l_fs3_blocks,
39 fs3_bytes => l_fs3_bytes,
40 fs4_blocks => l_fs4_blocks,
41 fs4_bytes => l_fs4_bytes,
42 full_blocks => l_full_blocks,
43 full_bytes => l_full_bytes) ;
44 DBMS_OUTPUT.PUT_LINE(RPAD('OWNER',40,'.')||p_owner);
45 DBMS_OUTPUT.PUT_LINE(RPAD('SEGMENT_NAME',40,'.')||p_segname);
46 DBMS_OUTPUT.PUT_LINE(RPAD('SEGMENT_TYPE',40,'.')||p_segtype);
47 DBMS_OUTPUT.PUT_LINE(RPAD('PARTITION_NAME',40,'.')||p_partition_name);
48 DBMS_OUTPUT.PUT_LINE(RPAD('*',0,'*'));
49 DBMS_OUTPUT.PUT_LINE(RPAD('unformatted_blocks',40,'.')||l_unformatted_blocks);
50 DBMS_OUTPUT.PUT_LINE(RPAD('unformatted_bytes',40,'.')||l_unformatted_bytes);
51 DBMS_OUTPUT.PUT_LINE(RPAD('fs1_blocks : 0 to 25% free space',40,'.')||l_fs1_blocks);
52 DBMS_OUTPUT.PUT_LINE(RPAD('fs1_bytes : 0 to 25% free space',40,'.')||l_fs1_bytes);
53 DBMS_OUTPUT.PUT_LINE(RPAD('fs2_blocks : 25 to 50% free space',40,'.')||l_fs2_blocks);
54 DBMS_OUTPUT.PUT_LINE(RPAD('fs2_bytes : 25 to 50% free space',40,'.')||l_fs2_bytes);
55 DBMS_OUTPUT.PUT_LINE(RPAD('fs3_blocks : 50 to 75% free space',40,'.')||l_fs3_blocks);
56 DBMS_OUTPUT.PUT_LINE(RPAD('fs3_bytes : 50 to 75% free space',40,'.')||l_fs3_bytes);
57 DBMS_OUTPUT.PUT_LINE(RPAD('fs4_blocks : 75 to 100% free space',40,'.')||l_fs4_blocks);
58 DBMS_OUTPUT.PUT_LINE(RPAD('fs4_bytes : 75 to 100% free space',40,'.')||l_fs4_bytes);
59 DBMS_OUTPUT.PUT_LINE(RPAD('full_blocks',40,'.')||l_full_blocks);
60 DBMS_OUTPUT.PUT_LINE(RPAD('full_bytes',40,'.')||l_full_bytes);
61 END;
62 /
위 결과를 보면 FS1, FS2, FS3, FS4의 개수와 용량을 볼 수 있습니다. 뿐만 아니라 full 상태의 Block의 개수도 알 수 있네요.
5. Extent와 Segment
Extent는 Block을 묶어둔 것을 의미하는 논리적 단위입니다. Extent가 여러 개 모여서 Segment를 구성합니다. 사용자가 테이블(Segment)를 생성하게 되면 데이터가 없더라도 기본값을 가지고 Data File에 연속적인 Block을 묶어서 Extent를 생성하게 됩니다. 데이터가 계속 추가되어서 최초 Extent 공간을 다 사용하게 되면 Extent를 추가로 생성합니다.
SQL> create tablespace test_extent
2 datafile '/app/oracle/oradata/testdb/ex_test01.dbf' size 5M;
SQL> create table ex_table01
2 (no number, name varchar2(10)) tablespace test_extent;
SQL> select tablespace_name, extent_id, blocks, bytes
2 from user_extents
3 where segment_name='EX_TABLE01';
TABLESPACE_NAME EXTENT_ID BLOCKS BYTES
------------------------------ ---------- ---------- ----------
TEST_EXTENT 0 8 65536
위 내용을 보면 테이블이 생성되면서 Block이 8개 생성되고, 64KB의 Extent 1개가 생성된 것을 볼 수 있습니다.
데이터가 더 추가되면 어떻게 될까요?
SQL> begin
2 for i in 1..10000 loop
3 insert into ex_table01 values (i, 'AAAA');
4 end loop;
5 commit;
6 end;
7 /
PL/SQL procedure successfully completed.
SQL> select tablespace_name, extent_id, blocks, bytes
2 from user_extents
3 where segment_name='EX_TABLE01';
TABLESPACE_NAME EXTENT_ID BLOCKS BYTES
------------------------------ ---------- ---------- ----------
TEST_EXTENT 0 8 65536
TEST_EXTENT 1 8 65536
TEST_EXTENT 2 8 65536
Extent 1개를 모두 사용한 후 추가로 늘려서 사용한 것을 볼 수 있습니다.
특정 테이블에 Extent를 수동으로 추가하려면 아래 명령어를 이용합니다.
SQL> alter table ex_table01
2 allocate extent ( size 100k
3 datafile '/ORA19/app/oracle/oradata/ORACLE19/ex_test01.dbf' );
Table altered.
SQL> select tablespace_name, extent_id, blocks, bytes
2 from user_extents
3 where segment_name='EX_TABLE01';
TABLESPACE_NAME EXTENT_ID BLOCKS BYTES
------------------------------ ---------- ---------- ----------
TEST_EXTENT 0 8 65536
TEST_EXTENT 1 8 65536
TEST_EXTENT 2 8 65536
TEST_EXTENT 3 8 65536
TEST_EXTENT 4 8 65536
결과를 보면 100KB를 추가했지만 64KB 단위로 총 128KB가 추가되어 2개의 Extent가 추가된 것을 확인할 수 있습니다.
Extent를 수동으로 할당해 주는 이유는 미리 확보하기 위함입니다. 하나의 Data File에는 여러 개의 Table이 저장될 수 있으므로, Table에 대한 데이터가 여러 Data File에 분산되기 전에 특정 Table을 위한 Extent를 미리 할당해 놓는 것입니다.
그렇다고 마냥 Extent를 미리 확보해두는 것이 좋은 걸까요. 만약 Extent를 할당해 놓았는데 그만큼의 데이터가 없다면 공간 낭비가 될 것입니다.
사용되지 않은 Extent를 반환하는 방법은 아래와 같습니다.
SQL> alter table ex_table01 deallocate unused;
Table altered.
SQL> select tablespace_name, extent_id, blocks, bytes
2 from user_extents
3 where segment_name='EX_TABLE01';
TABLESPACE_NAME EXTENT_ID BLOCKS BYTES
------------------------------ ---------- ---------- ----------
TEST_EXTENT 0 8 65536
TEST_EXTENT 1 8 65536
TEST_EXTENT 2 8 65536
만약 반납하려는 Extent에 데이터가 들어 있다가 삭제되어 비어 있는 경우라면 사용된 Extent이기 때문에 이 방법으로는 반납할 수 없습니다. 이런 경우라면 Table을 Reorg하는 등의 방법으로 조치를 해야 합니다.
Extent 크기를 지정하는 방법은 Segment를 생성할 때 STORAGE라는 파라미터를 이용해 수동으로 지정할 수 있고 만약 이 파라미터를 생략하면 해당 테이블이 저장될 Tablespace의 기본 설정값을 적용 받게 됩니다. 만약 Tablespace가 생성될 때 Segment Space Management Auto 설정값을 가지고 만들어졌다면(10g부터는 설정이 자동 적용) Oracle이 시스템이 최적화된 Extent 크기를 자동으로 결정합니다. 최소 값은 64KB이고 만약 Block Size가 16KB 이상인 경우 Extent의 최소값은 1M으로 설정됩니다.
Extent를 설정하는 이유
예를 들어 3개의 테이블이 있고 모두 하나의 Data File에 저장되어 있습니다. Extent가 없다면 각 테이블의 데이터가 Block 단위로 각각 뒤죽박죽 저장되어 조회 시간이 오래 걸릴 확률이 많아 성능이 저하됩니다. 이것보다 같은 테이블의 내용이 가까운 Block들에 저장되어 있으면 조회 시간을 많이 줄일 수 있고 성능이 향상될 것입니다.
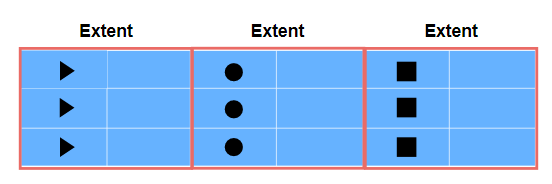
그래서 테이블 별로 Extent를 여러 개 만들어놓고 같은 테이블의 내용은 같은 Extent에 모아 놓는 것입니다.
HWM(High Water Mark)
만약 Table에서 데이터를 추가하는데 Extent가 부족하다면 새로운 Extent를 할당 받을 것이고, 새로운 Extent는 기본적으로 8개의 Block이 묶여 있을 것입니다. 그 Block들 중 2개만 사용할 것이라면 2개의 Block만 포맷을 하고 데이터를 기록합니다. 그리고 2개까지 사용했다는 의미로 HWM(High Water Mark)를 설정합니다.
Segment
Oracle Object 중에서 독자적인 저장 공간을 가지는 것들을 말합니다. 다른 말로 create로 만드는 모든 것을 의미합니다. 대표적으로 Table, Index, Undo, Temp, LOB 등이 있습니다. Segment는 Extent의 집합으로 만들어져 있습니다. 그리고 논리적으로 Tablespace에 저장됩니다.
Segment를 이루고 있는 여러 개의 Extent 중 가장 첫 번째 Extent의 첫 번째 Block에 Segment의 전체 요약 정보인 Segment Header 정보가 들어갑니다. Extent의 할당 상태와 공간 사용 내역 등의 주요 정보가 포함됩니다.
Segment와 Extent의 특징은 FLM, ASSM일 경우에 따라 다릅니다.
6. FLM 기법을 사용한 Extent 관리
DMT(Dictionary Management Tablespace)
8i 버전까지 쓰던 Free Block 관리법입니다. Block들의 정보들을 딕셔너리를 사용해서 중앙에서 일괄적으로 관리하는 방식이 바로 DMT(Dictionary Management Tablespace)입니다. Free Block은 FET$(Free Extent Table)에서 일괄적으로 관리하고 사용자는 DBA_FREE_SPACE에서 조회해 볼 수 있습니다. Dirty Block은 UET$(Used Extent Table)에서 일괄적으로 관리하며 DBA_EXTENTS에서 볼 수 있습니다. 만약 Dirty Extent가 Free Extent가 된다면 FET과 UET를 업데이트해야만 하는데 데이터가 한꺼번에 몰릴 경우 심각한 병목 현상이 발생할 수 있습니다. 여러 Server Process는 1명이 딕셔너리 작업을 진행하는 동안 대기하는 상태가 되기 때문입니다.
LMT(Locally Managed Tablespace)
인터넷 환경이 급속도로 발달하면서 여러 Server Process가 동시에 작업을 수행하는 경우가 굉장히 잦아졌습니다. 따라서 DMT 방식은 한계가 있었고 9i부터 새롭게 등장한 방식이 바로 LMT(Locally Managed Tablespace)입니다.
FLM 방식에서 Free Extent를 찾는 순서
FLM(Free List Management) 방식으로 Free Extents를 관리하기 위해서 Free List와 Free List Group이라는 것을 사용합니다. 이 속성들은 해당 Segment를 생성할 때 지정할 수 있습니다.
Free List는 LIFO(Last In First Out) 방식으로 운영됩니다. 사용자가 어떤 테이블에 새로운 데이터를 입력해야 할 경우 Undo segment를 먼저 확보한 후 해당 Table Segment가 속해있는 Tablespace의 Data File에서 Free Extent 내의 Free Block을 먼저 확보해야 합니다. 그리고 다른 Server Process가 사용하지 못하도록 해당 Block에 Lock을 걸고 해당 Block을 DB Buffer Cache로 복사합니다. 이때 Free Extent를 찾기 위해서 모든 Block을 찾아다니는 것이 아닙니다. Free Block의 명단을 가지고 있는 Free List를 참고해서 빠르게 찾습니다.
한편 Free List는 Linked List 형태로 구성되어 있습니다. 즉, 첫 번째 Free Block을 찾으면 그 Block에 두 번째 Free Block의 위치가 연결되어 있고 두 번째 Free Block에는 세 번째 Free Block의 위치가 연결되어 있습니다. 이런 특징으로 인해 성능 저하의 문제가 되기도 합니다.
Free List에는 3가지 종류가 있습니다.
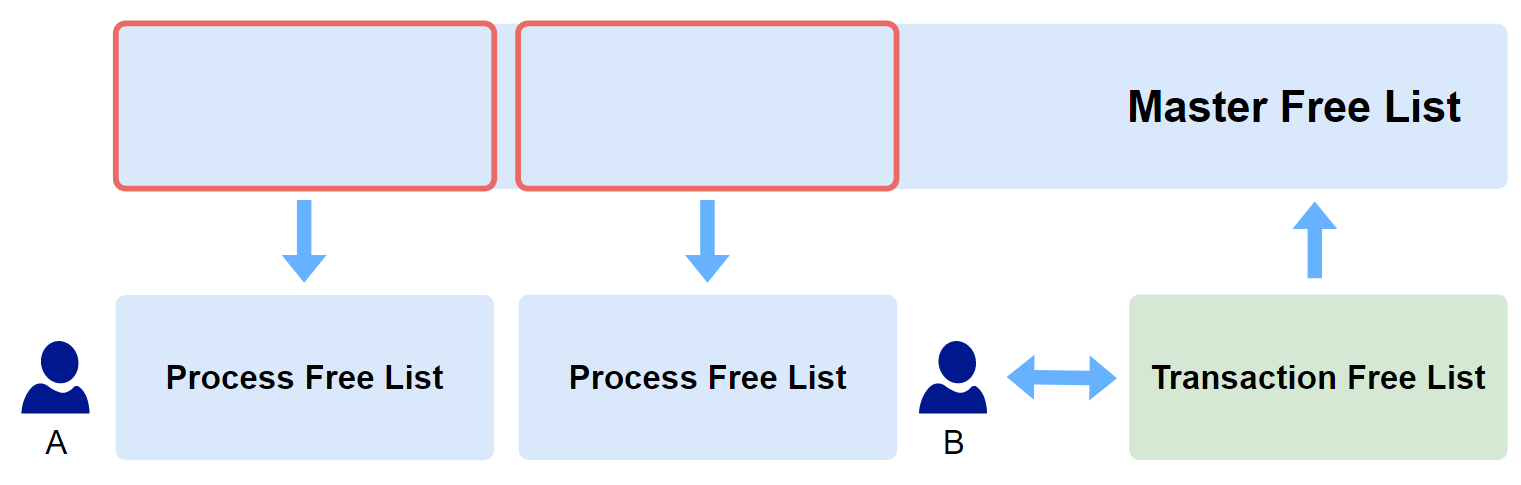
-
Master Free List(Segment Free List)
: 해당 Segment에서 새롭게 할당된 Free Block이나 Transaction이 종료되어 Dirty -> Free로 전환된 Block의 목록이 저장되어 있습니다. Process Free List를 생성하지 않으면 기본적으로 Master Free List가 전체 블록들을 관리하게 됩니다. -
Process Free List
: 마찬가지로 Dirty -> Free로 전환된 Block의 목록이 저장되어 있습니다. 이 List는 Master Free List의 경합을 막기 위해 사용합니다. 모든 Server Process가 Master Free List만을 조회한다면 1개의 Server Process가 조회하는 동안 다른 Server Process들은 대기해야 합니다. 이렇게 되면Buffer Busy Waits현상이 발생합니다. 그래서 Free List를 각 Server Process 별로 분리해서 할당합니다. 확실히 Server Process 간 경합이 줄어들어 성능이 더 좋아지게 됩니다. 이 값의 기본값은 1이기 때문에 별다른 설정이 없다면 사용하지 않는 것과 같습니다. 그래서 해당 Segment를 생성할 때Storage(... FREELISTS n ...)구문으로 개수를 지정하면 됩니다.
- Transaction Free List
: 현재 세션이 Transaction을 수행하는 도중 Free Block으로 변한 Block들의 목록을 관리합니다. 예를 들어, 현재 Transaction을 진행 중인 세션에서 Transaction 내에 특정 Row를 delete 혹은 update 하여 해당 Block이 PCTUSED 값에 도달해 Free Block으로 변할 경우 Oracle은 이 Block을 Master Free List로 즉시 기록하지 않고 해당 Transaction이 수행되고 있는 동안은 Transaction Free List에 기록하고 현재 세션이 Transaction을 수행하다가 Free Block이 필요해질 경우 우선적으로 사용하도록 해줍니다. Transaction이 끝나게 되면 Transaction Free List에 있는 목록들은 모두 Master Free List로 옮겨집니다.
만약 Process Free List에 할당된 Free Extent를 모두 사용하면 Master Free List에서 추가적으로 Free Extent를 할당 받아 사용합니다. Master Free List에도 Free Extent가 없을 경우 Oracle은 HWM을 오른쪽으로 이동시킨 후 Free Extent를 새로 생성해서 할당합니다. HWM를 이동시키려는 Server Process는 경합을 방지하기 위해 반드시 먼저 HW Lock을 획득하고, Free Extent를 확보한 후 그것을 Process Free List로 할당받게 됩니다.
HWM가 오른쪽으로 이동되는 값을 지정하는 파라미터는 _BUMP_HIGH_WATER_MARK_COUNT입니다. 예를 들어 이 값이 8로 설정되어 있으면 8개의 Block 만큼 이동합니다. 데이터의 입력이 많을 경우 이 값을 크게 주는 것이 성능 향상에 도움이 됩니다.
FLM의 Segment 구조를 살펴보면 첫 번째 Extent의 첫 번째 Block에 Segment Header가 생성됩니다.
Segment Header에는 HWM 정보 + 사용 중인 Extent들의 정보(Extent Map) + Free Block들의 위치 값(Free List Area)가 있습니다. 그리고 그 이후의 Block들에는 Header 정보에 맞게 데이터들이 들어있습니다.
7. ASSM(Automatic Segment Space Management) 기법을 사용한 Extent 관리
FLM은 Free List의 관리에 따라 성능이 결정되는 수동 모드의 관리 방법이었습니다. Oracle이 자동으로 Extent를 관리하는 방식은 ASSM(Automatic Segment Space Management)입니다.
기존에 사용하던 Free List 대신 Block의 사용 정도를 Bitmap으로 관리합니다. Bit Map Block(BMB)이 Free Block의 상태들을 관리합니다.
- 0000: 포맷 안된 상태
- 0001: 100% 사용 중인 상태
- 0010: 0% ~ 25% Free space인 상태(
FS1) - 0011: 25% ~ 50% Free space인 상태(
FS2) - 0100: 50% ~ 75% Free space인 상태(
FS3) - 0101: 75% ~ 100% Free space인 상태(
FS4)
Free space의 상태가 모든 Data Block의 Header 부분에 저장되어 있습니다. 이 정보를 가지고 L1 BMB가 만들어집니다. 하나의 L1 BMB에서 관리하는 Data Block의 개수는 Segment의 크기에 따라 아래와 같이 달라집니다.
- 1M 이하: 16 Blocks
- 1M ~ 32M: 64 Blocks
- 32M ~ 1G: 256 Blocks
- 1G ~: 1024 Blocks
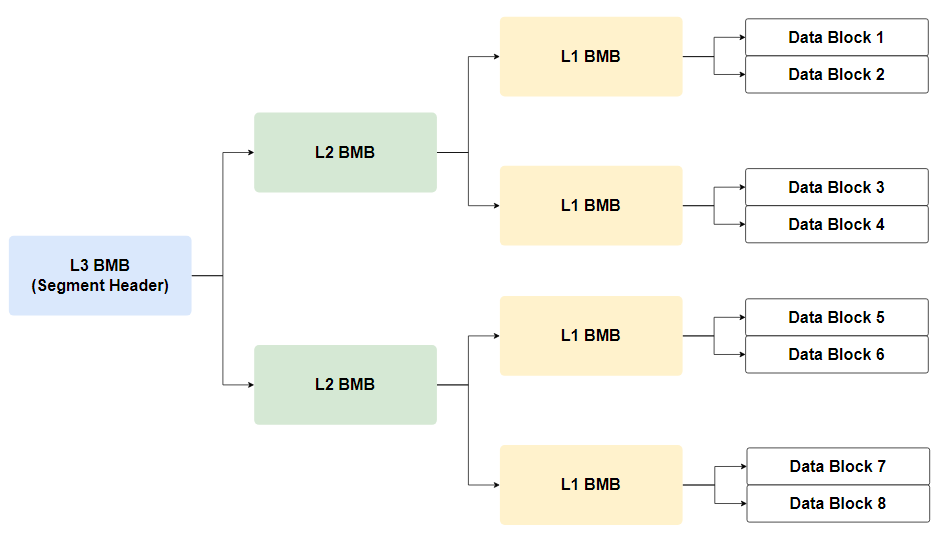
L3 BMB에 L2 BMB 정보가 들어 있고, L2 BMB에는 L1 BMB 정보가 들어 있습니다. L1 BMB에는 실제 Data Block 정보가 들어 있습니다. 새로운 데이터를 입력하기 위해서 Oracle은 가장 먼저 L3 BMB를 읽고 Free Block 정보를 가진 L2 BMB를 찾아서 또 읽고, 해당 Block을 관리하는 L1 BMB를 읽고, 마지막으로 실제 Data Block에 내용을 추가합니다. 만약 Block의 용량이 변경되면 Block Header 부분에 Bitmap 정보를 변경합니다.
ASSM이 도입되면서 Segment의 공간 관리 부분이 아주 많이 자동화되고 성능 역시 FLM에 비해 많이 개선되어 Tablespace를 생성할 때 좋은 성능을 얻기 위해서는 무조건 ASSM 기법으로 생성하기를 권장합니다. 10g부터는 기본적으로 ASSM이 적용되어 Segment의 성능 관련 이슈들이 많이 해결되었습니다.
참고
- <오라클 관리 실무> - 서진수
