개요
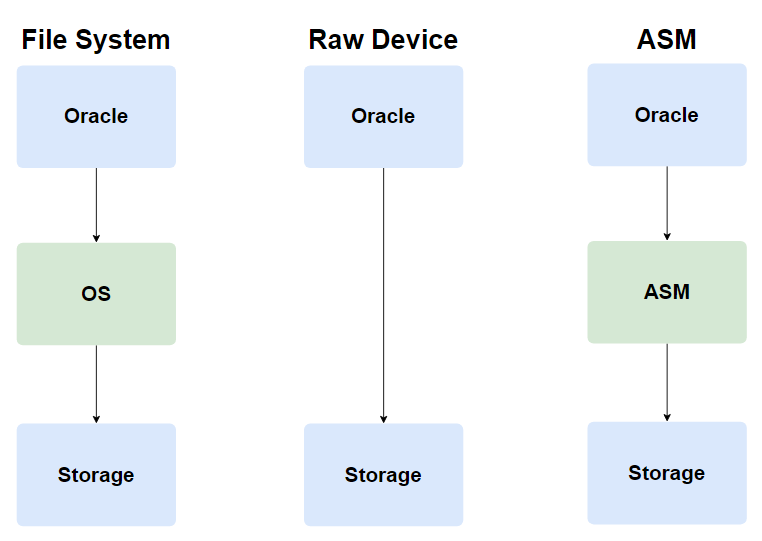
10g 이전 버전에서 데이터를 저장하고 관리하는 방식은 크게 OS를 통하여 관리하는 File System 방식과 Oracle에서 직접 스토리지에 데이터를 저장하는 Raw Device 방식이 대표적이었습니다.
File System 방식은 사용자가 관리하기 쉽다는 장점이 있는 반면, OS의 영향을 많이 받는 단점이 있습니다.
Raw Device 방식은 File System에 비해 성능은 좋다는 장점이 있지만 관리하기가 어렵고 불편한 단점이 있습니다.
위 두 가지 방식의 장점을 최대한 살린 방식이 바로 Oracle ASM 입니다.
File System 방식과 ASM 방식은 구조는 비슷합니다.
그러나 OS보다 ASM이 Oracle 환경에서 더 좋은 성능을 발휘하기 때문에 File System보다 권장되는 방식입니다.
1. ASM의 주요 특징
(1) 효율적인 디스크 관리
디스크 추가/삭제 작업을 보다 쉽게 할 수 있습니다. 보다 정확히는 추가/삭제 후 후속작업에 해당하는 파일 재배치 작업이 힘든 것인데, 기존 방식은 디스크 추가 후 관리자가 수동으로 이 작업을 해야 했지만, ASM 방식은 DB 중단 없이 Oracle이 자동으로 해줍니다.
즉, 관리자가 ASM Disk Group에 새로운 디스크를 추가/제거하기만 하면 나머지 후속 작업은 ASM에서 자동으로 Rebalancing(재배치) 작업을 해준다는 뜻입니다.
(2) 디스크 I/O의 효과적인 분산
기존 방식은 RAID로 구현되어 있어도 디스크가 교체되거나 추가되면 기존 디스크와 신규 디스크 사이에 데이터가 균등하게 분산되지 못하고 한쪽으로 쏠리는 현상이 발생하는 경우가 많았습니다.
ASM은 AU(Allocation Unit) 단위로 나누어서 서로 다른 디스크에 균등하게 데이터를 분산시켜 저장합니다. 이에 따라 I/O가 효율적으로 분산되어 성능이 많이 향상됩니다. 기존 RAID의 스트라이핑 방식은 디스크 튜닝이 아주 중요했지만 ASM 방식은 AU로 자동 관리해 주기 때문에 디스크 I/O 성능이 아주 많이 향상되었고 디스크 튜닝이 거의 필요가 없을 정도입니다.
(3) 비용의 절감
기존 방식의 경우 고가의 RAID 장비를 별도로 구매해서 설치하고 운영해야 하지만 ASM을 도입하면 Oracle에서 Software적으로 RAID의 기능들을 구현하기 때문에 별도의 하드웨어나 소프트웨어 구입 비용 없이 디스크 장애 대비나 I/O 분산을 통한 성능 향상을 도모할 수 있습니다.
2. Oracle ASM 구조
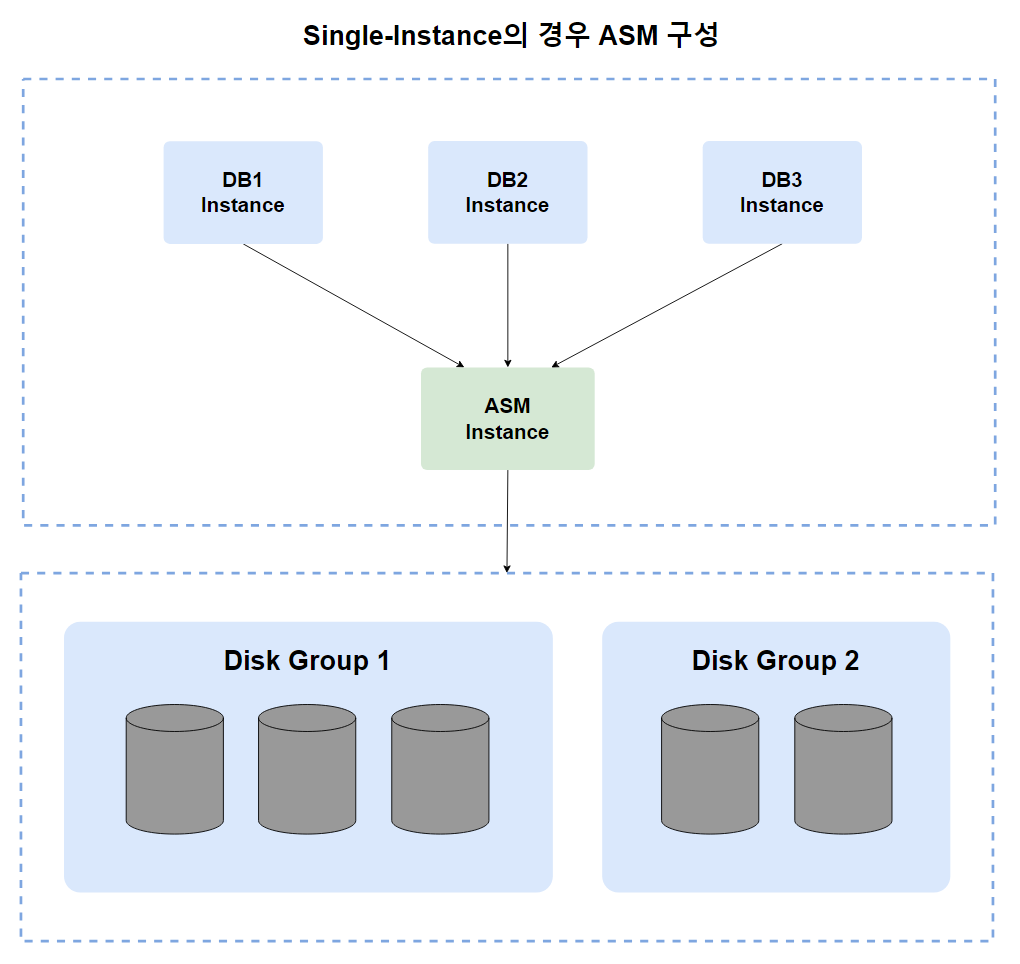
위 그림은 단일(Single) 인스턴스로 구성되어 있는 여러 개의 데이터베이스들이 ASM 인스턴스를 통해 Storage에 접속해서 데이터를 관리하는 구성도입니다. 위와 같은 경우를 Multi-Instance라고도 합니다.
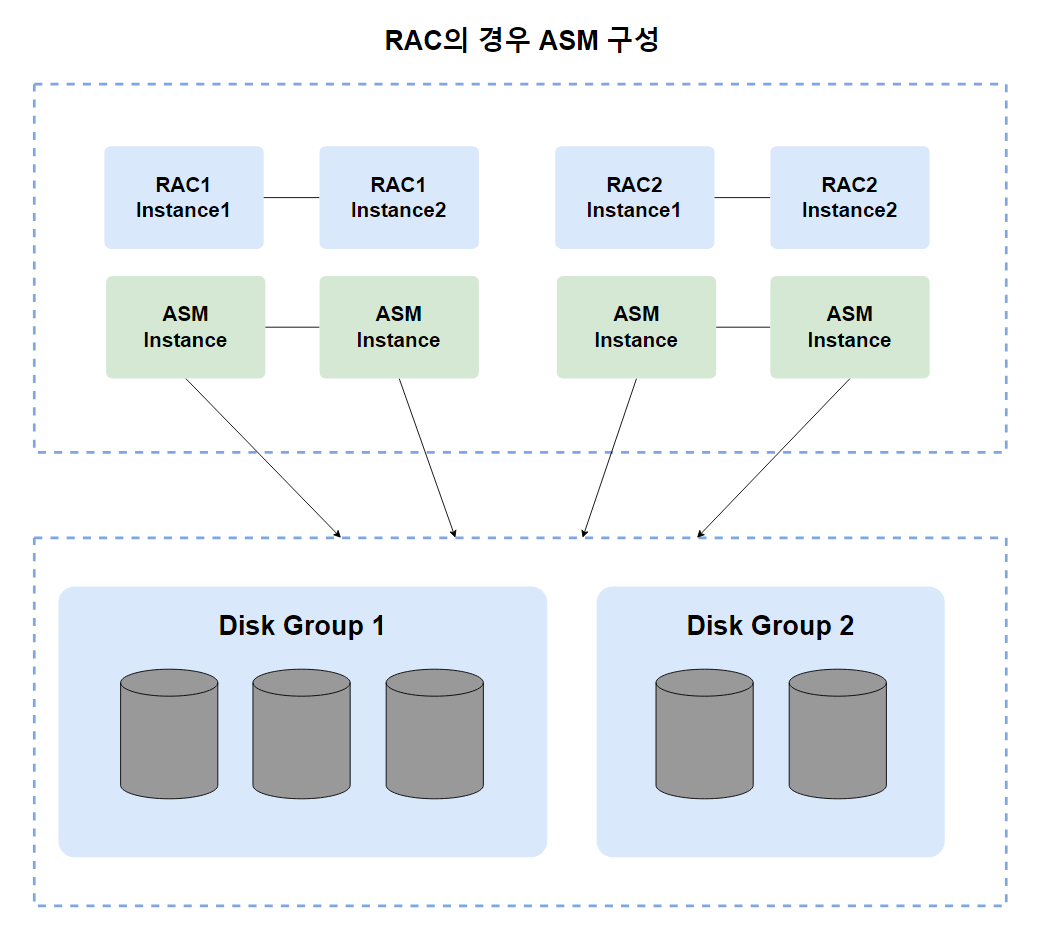
위 그림은 2개의 RAC 환경에서 각 Node 별로 ASM 인스턴스를 구성해서 Storage에 접근하는 방식을 나타내고 있습니다.
(3) ASM Instance 내부 구조
3. ASM Disk Group 개요
ASM에서는 디스크를 여러 개 묶어서 Disk Group으로 관리합니다. 1개의 Group에는 최소 2개의 디스크가 있어야 합니다.
데이터가 들어올 때는 AU 단위로 나누어서 Disk Group 별로 분산시켜 저장합니다. AU는 COARSE-grained 방식과 FINE grained의 두 가지 옵션을 가질 수 있습니다. COARSE일 경우 AU 단위는 1MB이며 주로 Data File과 Archive Log File에 사용하며, FINE의 경우 128KB이며 Redo Log File, Control File, Flashback Log File을 디스크에 기록할 때 사용합니다.
11g ASM 부터는 AU의 종류가 1/2/4/8/16/32/64MB로 다양하게 지원되며 Disk Group을 생성할 때 지정할 수 있게 되어 성능 향상이 이루어집니다.
(1) Redundancy
Disk Group 내의 한 디스크에 장애가 날 경우 전체 Disk Group 내의 데이터를 모두 손실할 수 있기 때문에 안정성(Redundancy)를 위해 Disk Group을 생성할 때 3가지 방법을 설정할 수 있습니다.
Normal: 2-way mirroring. 디스크가 2배가 있어야 합니다.High: 3-way mirroring. 디스크가 3배가 있어야 합니다.External: ASM mirroring 기능을 사용하지 않습니다. 이 경우 반드시 RAID 기능으로 디스크를 보호하고 있을 경우에만 사용하길 권장합니다.
일반 디스크를 ASM Disk Group으로 사용하기 위해서는 물리적 디스크를 논리적 ASM Disk로 구성해야 합니다. 일반 디스크를 특정 파일 시스템으로 포맷하는 것과 동일한 원리입니다.
ASM Disk에 저장되고 관리될 수 있는 파일의 목록은 아래와 같습니다.
- Control files
- Data files, temporary data files, data file copies
- SPFILEs
- Online redo logs, archive logs, Flashback logs
- RMAN backups
- Disaster recovery configurations
- Change tracking bitmaps
- Data Pump dumpsets
(2) ASM Extents
File System 환경에서 Oracle이 디스크에 데이터를 저장할 때 block -> extent 단위로 저장하는 것과 마찬가지로 ASM 환경에서도 Block에 해당되는 AU(Allocation Unit)와 AU가 여러 개 모인 Extent를 사용해 ASM Disk에 데이터를 저장합니다.
ASM 내부에서 데이터를 효과적으로 관리하기 위해 다양한 Extent Size를 제공합니다.
최초 2만개: 해당 Disk Group의 AU size와 동일합니다. (0 - 19999)다음 2만개: AU size * 4의 크기입니다. (20000 - 39999)그 다음 나머지들: AU size * 16 (40000+)
보시면 데이터가 많아질 수록 AU 크기가 증가하는 모습을 볼 수 있는데 이는 데이터의 양이 많아 지면서 I/O를 줄이기 위해서입니다.
4. ASM 관리하기
(1) ASM Instance 파라미터 파일
ASM의 구조 역시 Instance와 Disk 부분으로 나누어져 있습니다. 특정 데이터를 요청했을 때 메모리 부분인 ASM Instance에 캐싱해 두었다가 전달하는 것이 성능에 훨씬 좋기 때문입니다.
ASM을 설치하게 되면 Oracle이 Disk Group 내부에 ASM Instance 용 Parameter File과 Passwd file을 생성하게 됩니다. Parameter File은 spfile을 공유된 장소에 생성해서 여러 노드에서 사용할 수 있도록 구성하는 것이 권장사항인데, 만약 각 노드의 로컬에 pfile을 사용하길 원할 경우 pfile 내부에 spfile의 경로를 적어주면 그 값을 사용해 spfile을 찾아가서 ASM Instance를 시작할 수도 있습니다.
11g 부터는 ASM Instance에 접속할 때 권한을 sysasm으로 접속해야 합니다.
$ sqlplus / as sysasm
SQL> set line 200
SQL> show parameter spfile;
10g에서는 $ORACLE_HOME/dbs/init+ASM.ora로 생성되었지만 11g부터는 ASM 스토리지 내부에 저장되어 있습니다. 그래서 초기 설치 시에는 $ORACLE_HOME/dbs 디렉토리에 ASM parameter file이 없습니다.
SQL> create pfile='$ORACLE_HOME/dbs/init+ASM.ora'
2 from spfile;
SQL> !ls $ORACLE_HOME/dbs
MEMORY_TARGET
전체 메모리(SGA+PGA)를 자동으로 관리하는 파라미터입니다. 만약 ASM 환경이라면 전체 메모리는 SGA+PGA+ASM입니다.
ASM_DISKGROUPS
ASM Instance가 시작될 때 자동으로 마운트 될 Disk Group 명을 지정하는 파라미터입니다. 기본값은 NULL이며 동적 파라미터라 서버 운영 중에 변경하고 적용할 수 있습니다.
ASM_DISKSTRING
ASM Instance가 사용할 디스크 명단을 지정해 주는 파라미터입니다.
Disk Group을 지정해서 사용하기 때문에 값을 설정하지 않아도 됩니다. 기본값은 NULL이며, NULL일 경우 ASM Instance가 시작될 때 기본 설정경로에서 모든 ASM Disk를 찾아서 사용하게 됩니다.
ASM_POWER_LIMIT
Disk Group 내에서 Rebalancing 성능을 결정하는 파라미터입니다. 0 ~ 1024까지 값을 지저할 수 있으며 기본값은 1입니다. 0은 Rebalancing 기능을 사용하지 않는다는 뜻이고, 숫자가 높을 수록 Rebalancing 속도가 빨라진다는 의미입니다. 단, 숫자가 높을 수록 Rebalancing 작업을 하기 위해 I/O가 많이 발생해서 다른 업무 속도에 영향을 줄 수 있습니다.
ASM_PREFERRED_READ_FAILURE_GROUPS
ASM Disk Group의 미러링 기능과 관련된 파라미터입니다. 데이터의 안정성을 위해 Disk Group1, 2를 미러링으로 구성한다면 라운드로빈 방식으로 데이터를 저장합니다. 즉, 데이터를 저장한다면 원본은 Disk Group 1에 저장, 사본은 Disk Group 2에 저장합니다. 다시 한 번 데이터를 저장한다면 이번에는 원본은 Disk Group 2, 사본은 Disk Group 1에 저장합니다. 만약 여러 인스턴스들이 데이터에 액세스한다면 우선적으로 Disk Group 1만을 찾게 되어 성능이 저하될 수 있습니다. 따라서 각 노드 별로 우선적으로 액세스할 Disk Group을 지정해줄 수 있도록 이 파라미터를 이용합니다.
SQL> alter system set asm_preferred_read_failure_groups = 'DG1.DG01','DG2.DG02';위 명령어를 수행한 노드는 DG1 Disk Group의 DG01 디스크를 최우선적으로 액세스합니다.
SQL> col instname for a10
SQL> col dbname for a8
SQL> col failgroup for a10
SQL> set line 200
SQL> select instname,dbname,group_number,failgroup,disk_number,reads,writes
2 from v$asm_disk_iostat
3 order by 1,2,3,4,5,6;
DB_CACHE_SIZE
이 파라미터는 ASM Instance에서 메타 데이터 블록을 관리할 메모리 용량을 지정하는 파라미터입니다. AMM 기능을 사용하고 있는 경우 이 파라미터를 지정할 필요는 없습니다.
DIAGNOSTIC_DEST
ASM의 각종 로그 파일이 저장될 경로를 지정하는 파라미터입니다.
INSTANCE_TYPE
현재 인스턴스의 타입을 지정해 주는 파라미터입니다. ASM 환경일 경우 ASM으로 지정하면 됩니다.
LARGE_POOL_SIZE
ASM 저장공간의 Extent들의 Map 정보를 저장하는 파라미터입니다. AMM 기능을 사용할 경우 이 파라미터를 지정할 필요는 없습니다.
PROCESSES
ASM Instance에 접속할 수 있는 Process들의 개수를 지정하는 파라미터입니다. 권장값은 50+(50 X ASM 접속 인스턴스 수)입니다.
REMOTE_LOGIN_PASSWORDFILE
ASM에서 접속 시에 사용될 패스워드 파일 사용여부를 지정합니다.
SHARED_POOL_SIZE
ASM Instance에서 데이터들을 관리하기 위해 필요한 메모리의 총량을 지정합니다. AMM 기능을 사용할 경우 이 파라미터를 지정할 필요가 없습니다. DB Instance에서 DB_CACHE_SIZE와 비슷한 역할을 합니다.
(2) ASM Instance 시작하기/종료하기
DB 인스턴스와 동일하게 ASM 인스턴스 역시 startup으로 시작하고, shutdonw으로 종료합니다. 옵션 역시 동일합니다.
보통 ASM을 사용하게 되면 인스턴스는 ASM 인스턴스와 DB 인스턴스, 총 2개가 만들어집니다.
DB 인스턴스는 데이터를 저장하거나 가져올 때 ASM 인스턴스를 사용하므로, DB 인스턴스가 시작되기 전에는 ASM 인스턴스가 시작되어 있어야 할 것입니다. 따라서,
startup 할 때는 반드시 ASM 인스턴스 -> DB 인스턴스
shutdown 할 때는 반드시 DB 인스턴스 -> ASM 인스턴스
순으로 진행되어야 합니다.
위 사항을 지키지 않는다면 아래와 같은 에러가 발생합니다.
DB 인스턴스를 먼저 시작하려 할 시,
SQL> startup
ORA-01078: failure in processing system parameters
ORA-01565: error in identifying file '+DATA/testdb/spfiletestdb.ora'
ORA-17503: ksfdopn:2 Failed to open file +DATA/testdb/spfiletestdb.ora
ORA-15077: could not locate ASM instance serving a required diskgroupASM 인스턴스를 먼저 종료하려 할 시,
SQL> shutdown immediate;
ORA-15097: cannot SHUTDOWN ASM instance with connected client(3) ASM Disk Group 관리하기
DB Instance에 연결되어 있는 disk group 정보 확인하기
SQL> set line 200
SQL> col disk_group for a10
SQL> col label for a10
SQL> col stat for a10
SQL> select a.name disk_group, d.name label, a.state
2 from v$asm_disk d, v$asm_diskgroup a
3 where d.group_number=a.group_number
4 order by 2;
SQL> select instance_name
2 from v$instance;
ASM Instance에서 현재 연결되어 있는 disk group 확인하기
SQL> select instance_name from v$instance;
SQL> set line 200
SQL> col group_number for 99
SQL> col name for a10
SQL> col type for a10
SQL> col state for a10
SQL> select group_number, name, type, state
2 from v$asm_diskgroup;
각 disk group 세부 정보 확인하기
SQL> col group_number for 999
SQL> col disk_number for 999
SQL> col name for a10
SQL> col mount_status for a10
SQL> col path for a15
SQL> select group_number, disk_number, name, mount_status, path, total_mb
2 from v$asm_disk;
각 disk group 별로 저장되어 있는 파일 내역 확인하기
SQL> set pages 50
SQL> col group_number for 99
SQL> col file_number for 999
SQL> col type for a20
SQL> select group_number, file_number, round((bytes/1024/1024),1) MB, redundancy, type
2 from v$asm_file;
새로운 Disk Group 생성 및 관리하기
- 파티션작업
- ASM Disk 생성
- Disk Group 생성
-- 파티션작업
# fdisk /dev/sdg
Command: n
Command action
p
Partition number (1-4): 1
First cylinder(1-652, default 1): <Enter>
Last cylinder: <Enter>
Command: w
# fdisk /dev/sdh
Command: n
Command action
p
Partition number (1-4): 1
First cylinder(1-652, default 1): <Enter>
Last cylinder: <Enter>
Command: w
-- ASM Disk 생성
# /etc/init.d/oracleasm createdisk asm3 /dev/sdg1
# /etc/init.d/oracleasm createdisk asm4 /dev/sdh1
# oracleasm listdisks
-- ASM Instance에 접속
-- ASM 디스크 상태 먼저 확인
SQL> set line 200
SQL> col path for a15
SQL> select group_number, mount_status, path, total_mb
2 from v$asm_disk;
-- Disk Group 조회
SQL> select group_number, name, state from v$asm_diskgroup;
-- Disk Group 생성
SQL> create diskgroup new_asm external redundancy
2 disk 'ORCL:ASM3';
SQL> select group_number, name, state from v$asm_diskgroup;
-- 각 Disk Group이 어떤 디스크로 구성되어 있는지 확인
SQL> set lines 200
SQL> col group_name for a10
SQL> col disk_name for a10
SQL> select b.name group_name, a.name disk_name, a.header_status, a.state, a.free_mb
2 from v$asm_disk a, v$asm-diskgroup b
3 where a.group_number=b.group_number;
6. Disk Group에 새로운 member disk 추가하기
SQL> alter diskgroup new_asm
2 add disk 'ORCL:ASM4' rebalance power 5;
SQL> select b.name as group_name, a_name as disk_name, a.header_status, a.state, a.free_mb
2 from v$asm_disk a, v$asm_diskgroup b
3 where a.group_name=b.group_name;
SQL> alter diskgroup new_asm drop disk asm4;
SQL> select b.name as group_name, a_name as disk_name, a.header_status, a.state, a.free_mb
2 from v$asm_disk a, v$asm_diskgroup b
3 where a.group_name=b.group_name;
7. Disk Group 연결 해제(dismount)하기
SQL> alter diskgroup new_asm dismount;
SQL> select group_number, name, state
2 from v$asm_diskgroup;
8. Disk Group 연결(mount)하기
SQL> alter diskgroup new_asm mount;
SQL> select group_number, name, state
2 from v$asm_diskgroup;
9. Disk Group 점검하기
- Disk Group을 구성하는 디스크의 문제 여부 확인
- 파일을 구성하는 Extent Map 정보와 공간 사용량 정보 등 확인
- 파일과 디렉토리의 링크 정보와 메타데이터 정보 확인
- 디렉토리 트리의 별칭 정보 확인
SQL> alter diskgroup data check all repair;
repair: 문제가 발생할 경우 자동으로 repair 수행norepair: 문제가 발생할 경우 메시지만 보입니다.
10. Disk Group 삭제하기
-- DB 인스턴스 접속
SQL> create tablespace test
2 datafile '+NEW_ASM' size 5M;
SQL> set line 200
SQL> col tablespace_name for a10
SQL> col file_name for a50
SQL> select tablespace_name, bytes/1024/1024 MB, file_name
2 from dba_data_files;
Disk Group에 데이터 파일이 있을 경우 including contents 옵션을 주면 됩니다.
(Disk Group에 데이터 파일이 있으면 삭제되지 않습니다)
SQL> drop diskgroup new_asm;
SQL> drop diskgroup new_asm including contents;
11. 데이터가 없는 Disk Group 이름 변경하기
SQL> alter diskgroup new_asm dismount;
$ renamedg dgname=new_asm newdgname=data2 verbose=true
$ sqlplus / as sysasm
SQL> select group_number, name, state
2 from v$asm_diskgroup;
SQL> alter diskgroup data2 mount;
SQL> select group_number, name, state
2 from v$asm_diskgroup;
12. 데이터가 존재하는 Disk Group rename 수행하기
Tablespace가 존재하는 Disk Group을 Rename 해보겠습니다.
테스트를 위해 먼저 Tablespace를 생성하겠습니다.
SQL> create tablespace test
2 datafile '+DATA2';
SQL> select tablespace_name, bytes/1024/1024 MB, file_name
2 from dba_data_files;
Disk Group을 Rename 해보겠습니다.
SQL> alter tablespace test offline;
SQL> alter diskgroup data2 dismount;
-- OS의 ASM용 계정에서 renamedg 명령 수행
$ renamedg dgname=data2 newdgname=data3
$ sqlplus / as sysasm
SQL> alter diskgroup data3 mount;
SQL> select group_number, name, state
2 from v$asm_diskgroup;
SQL> alter tablespace test rename datafile
2 '+DATA2/testdb/datafile/test.256.nnnnnnnnn'
3 to '+DATA3/testdb/datafile/test.256.nnnnnnnnn'
SQL> alter tablespace test online;
SQL> select tablespace_name, bytes/1024/1024 MB, file_name
2 from dba_data_files;
만약 offline이 되지 않는 system tablespace 같은 경우 DB 인스턴스를 종료한 후 동일하게 변경하면 됩니다.
(4) ASM Disk Group 속성
ASM은 스토리지 보안을 위해서 Disk Group의 속성 제어, ASMCMD의 setattr 명령을 사용해 특정 사용자나 그룹의 접근을 제한할 수 있는 기능을 제공합니다.
ACCESS_CONTROL.ENABLED
ASM Disk Group에 접근제어를 활성화 할 것인지를 결정하는 속성입니다.
SQL> alter diskgroup data set attribute 'compatible.rdbms'='11.2';
SQL> alter diskgroup data set attribute 'access_control.enabled'='true';
SQL> alter diskgroup data add user 'ora_asm';
ACCESS_CONTROL.UMASK
유닉스 환경의 umask와 비슷한 성격으로 숫자 3자리의 조합을 사용해 접근 권한을 설정합니다. 형태는 소유자|소유자가 속한 그룹|나머지이며, 각 자리마다 0,2,6의 숫자 조합을 사용할 수 있습니다. 0은 모든 권한, 2는 쓰기 권한을 막는 것이며 6은 읽기와 쓰기 권한을 막는 것입니다.
SQL> alter diskgroup data set attribute 'access_control.umask'='026';
AU_SIZE
Disk Group을 생성할 때만 설정할 수 있는 속성으로 해당 Disk Group에서 사용할 저장단위인 AU의 크기를 지정하는 속성입니다.
CELL.SMART_SCAN_CAPABLE
Oracle Exadata를 위한 속성입니다.
COMPATIBLE.ASM
ASM Disk Group을 사용할 최소한의 ASM software version을 지정합니다. 예를 들어 10.1이라면 최소한 10.1 버전 이상만 현재 ASM Disk Group을 사용할 수 있다는 의미가 됩니다.
COMPATIBLE.ADVM
ASM Disk Group에 ASM 볼륨을 포함할 수 있는지의 여부를 결정합니다. 이 속성의 기본값은 NULL로 설정되어 있습니다.
CONTENT.TYPE
Oracle Exadata를 위해 만들어진 속성으로 Disk Group의 Type이 data인지 recovery인지 또는 system인지 결정하는 속성입니다. 기본값은 data입니다. Disk Group을 생성할 때 지정할 수 있으며 생성 후에 alter 명령으로 변경할 수도 있습니다. alter 명령어로 변경한 경우에는 Disk Group을 Rebalance 해야 적용됩니다. 또한 Disk Group의 redundancy가 normal, high일 경우에만 적용됩니다.
DISK_REPAIR_TIME
redundancy 기능이 적용될 경우 디스크에 장애가 날 경우 해당 디스크에 있는 내용이 주변의 다른 디스크로 rebalance 되었다가 장애 디스크가 복구되면 다시 원위치로 rebalance되는데 데이터의 양이 많을 경우 상당한 부하가 걸릴 수 있습니다. 그래서 ASM에서는 disk_repair_time 속성을 사용해 이 속성에 지정된 시간 동안에는 rebalance를 하지 못하도록 설정할 수 있습니다. 기본 시간은 3.6시간이며 이 시간 안에 디스크가 복구되면 rebalance를 하지 않고 데이터를 바로 사용할 수 있습니다.
SECTOR_SIZE
Disk Group 내의 Sector size를 지정할 수 있는 속성입니다.
(5) ASM Disk Group 관리를 위한 User Group 생성 및 관리
ASM 스토리지를 저장 공간으로 사용할 사용자(OS 사용자)들을 개별적으로 접근 제어 하기란 불편하기 때문에 그룹을 만들어서 그룹별로 Disk에 접근 제어할 수 있습니다. 그룹에 대한 사용자 정보는 v$asm_user 뷰를 통해서 조회 가능합니다.
SQL> selct group_number, os_name from v$asm_user;
SQL> alter diskgroup data add usergroup 't_group_1'
2 with member 'ora_asm','oracle';
위의 예는 t_group_1이라는 그룹을 생성하고 ora_asm, oracle이라는 OS 계정을 그룹에 넣어주었습니다.
- Disk Group에 속한 ASM User Group 삭제하기
SQL> alter diskgroup data drop usergroup 't_group_1';
- ASM User Group에 사용자 추가하기
SQL> alter diskgroup data modify usergroup 't_group_1'
2 add member 'oracle2';
- ASM User Group에서 특정 멤버 삭제하기
SQL> alter diskgroup data modify usergroup 't_group_1'
2 drop member 'oracle2';
- 특정 OS 계정을 직접 Disk Group 사용자로 등록하기
SQL> alter diskgroup data add user 'oracle';
SQL> !
$ su -
# useradd -g dba oracle3
# exit
$ exit
SQL> alter diskgroup data add user 'oracle3';
- 특정 OS 계정을 직접 Disk Group 사용자에서 삭제하기
SQL> alter diskgroup data drop user 'oracle3';
- 특정 파일에 권한을 설정하기
SQL> alter diskgroup
2 set permission owner=read write, group=read only, other=none
3 for file '+DATA/restdb/datafile/users.264.nnnnnnnnn';
특정 파일에 권한을 설정하려면 해당 파일이 open 상태가 아니어야 합니다.
- 특정 데이터파일의 소유권 설정하기
SQL> alter diskgroup data set ownership owner='oracle3', group 't_group_1'
2 for file '+DATA/restdb/datafile/users.264.nnnnnnnnn';
- 특정 disk group과 관련한 ASM User와 Group 확인하기
SQL> select dg.name AS_diskgroup, um.group_number, um.member_number, u.os_name, um.usergroup_number, ug.name
2 from v$asm_diskgroup dg, v$asm_user u, v$asm_usergroup_member um, v$asm_usergroup ug
3 where dg.group_number = um.group_number
4 and dg.group_number = ug.group_number
5 and dg.group_number = u.group_number
6 and dg.group_number = u.group_number
7 and dg.name = 'DATA'
8 and um.member_number = u.user_number
9 and um.usergroup_number = ug.usergroup_number;
(6) ASM 환경에서 파일 및 디렉토리 관리하기
Data File
SQL> select tablespace_name, bytes/1024/1024 MB, file_name
2 from dba_data_files;
Control file / Redo Log file
SQL> col name for a60
SQL> select name from v$controlfile;
SQL> col member for a60;
SQL> select member from v$logfile;
파일들의 이름을 지정하는 방식은 아래와 같습니다.
+<diskgroup>/<dbname>/<filetype>/<filetypetag.file.incarnation>
+는 루트 디렉토리와 같은 개념입니다.diskgroup: 해당 파일이 속한 disk group입니다.dbname:DB_UNIQUE_NAME파라미터의 값입니다.filetype: 저장되는 파일의 종류filetypetag: 각 파일타입에 대한 요약정보file.incarnation: 파일과 incarnation 번호를 세트로 구성해서 unique한 파일이름을 생성합니다.
(7) ASM 환경에서 Tablespace 관리하기
- 현재 상황 확인
SQL> set lines 200
SQL> col tablespace_name for a10
SQL> col file_name for a45
SQL> select tablespace_name, bytes/1024/1024 MB, file_name
2 from dba_data_files;
- 신규 TS 생성
SQL> show parameter db_create;
db_create_file_dest: data file이 생성되는 경로db_create_online_log_dest_n: online redo log file과 control file이 생성되는 기본 경로
-- asm 계정으로 접근(OS)
$ asmcmd -p
ASMCMD > ls
ASMCMD > mkdir +FRA/TESTDB/DATAFILE
ASMCMD > cd +FRA/TESTDB/DATAFILE
ASMCMD > pwd
-- oracle 계정으로 접근(OS)
SQL> create tablespace ts_new
2 datafile '+FRA/TESTDB/DATAFILE/test01.dbf' size 10M;
SQL> select tablespace_name, bytes/1024/1024 MB, file_name
2 from dba_data_files;
- ts_new TS에 새로운 data file 추가
-- oracle 계정으로 접속
SQL> alter tablespace ts_new
2 add datafile '+FRA/TESTDB/DATAFILE/test02.dbf' size 5M;
SQL> select tablespace_name, bytes/1024/1024 MB, file_name
2 from dba_data_files
3 order by 1;
offline이 가능한 ts_new TS를 +FRA -> +DATA 그룹으로 이동
1. tablespace offline
SQL> alter tablespace ts_new offline;
- data file copy
$ rman target /
RMAN> run {
2> copy datafile '+FRA/testdb/datafile/test01.dbf' to '+DATA/testdb/datafile/test01.dbf';
3> copy datafile '+FRA/testdb/datafile/test02.dbf' to '+DATA/testdb/datafile/test02.dbf';
4> }
- control file 위치 변경
SQL> alter tablespace ts_new rename datafile
2 '+FRA/testdb/datafile/test01.dbf'
3 to '+DATA/testdb/datafile/test01.dbf';
SQL> alter tablespace ts_new rename datafile
2 '+FRA/testdb/datafile/test02.dbf'
3 to '+DATA/testdb/datafile/test02.dbf';
- online
SQL> alter tablespace ts_new online;
SQL> select tablespace_name, bytes/1024/1024 MB, file_name
2 from dba_data_files;
offline 안되는 system tablespace를 +DATA -> +FRA로 이동하기
1. DB 인스턴스 종료 후 mount 단계 startup
SQL> shutdown immediate;
SQL> startup mount;
- system tablespace의 data file을 copy
(full 경로를 적어주면 에러가 발생합니다)
SQL> rman target /
RMAN> report schema;
RMAN> copy datafile '+DATA/testdb/datafile/system.260.nnnnnnnnn'
2> to '+FRA'
- alter database rename file 위치 정보 변경
SQL> alter database rename file '+DATA/testdb/datafile/system.260.nnnnnnnnn'
2 to '+FRA/testdb/datafile/system.263.nnnnnnnnn';
- DB 인스턴스 open
SQL> alter database open;
redo log file 관리하기
Redo log file은 복사가 안되므로 이동하고자 하는 그룹이나 멤버를 삭제한 후 대상 디렉토리로 다시 생성해야 합니다.
1번 그룹 redo log file을 +DATA/testdb/onlinelog/ 아래로 재생성하겠습니다.
SQL> alter database drop logfile
2 member '+FRA/testdb/onlinelog/group_1.257.807251625';
SQL> alter database add logfile
2 member '+DATA' to group 1;
SQL> select a.group#, a.member, b.bytes/1024/1024 MB, b.sequence# "SEQ#", b.status, b.archived
2 from v$logfile a, v$log b
3 where a.group#=b.group#
4 order by 1,2;
Control File 관리하기
SQL> select name from v$controlfile;
SQL> alter system set conrol_files='+DATA/testdb/controlfile/current.256.nnnnnnnnn','+DATA'
2 scope=spfile;
SQL> shutdown immediate;
SQL> !
SQL> rman target /
RMAN> restore controlfile from '+DATA/testdb/controlfile/current.256.nnnnnnnnn';
RMAN> exit
SQL> alter database mount;
SQL> alter database open;
SQL> select name from v$controlfile;
