
안녕하세요!
오늘은 5월 3주차 세번째 알고리즘 Longest String Chain 풀이를 작성해보겠습니다.
문제
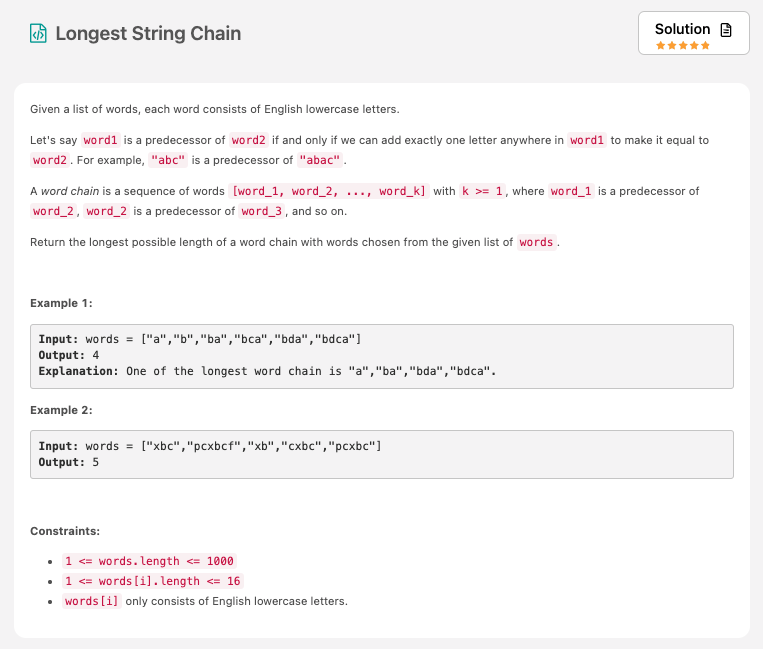
요약
주어진 words 에서 문자열끼리 연관성이 있는 chain 관계를 찾아서 가장 긴 chain 의 길이를 return하는 문제입니다.
처음 생각한 방법
우선
words배열을 길이순으로 정렬한 후, 가장 짧은String부터 차례로 다음에 나올String에 현재String이 포함되어있는지 체크해서 가장 큰count를 리턴한다.
이 방법의 문제점은 "bdca".contains("bda") 의 경우에는 false 가 도출되기 때문에, 로직이 잘못되었다는 것을 느꼈습니다.
두번째로 생각한 방법
그렇다면 거꾸로 찾아보자는 생각을 했습니다. 길이 기준 내림차순으로
words를 정렬하고 한 글자씩 제거한String을 구해서 그것이 배열에 포함되어있는지 확인하는 방식으로 진행했습니다.
이 방식은 한 단어로까지의chain이 어디까지 가느냐의 문제이기 때문에dfs방식을 응용했습니다.
그러면 이제부터 로직을 자세히 설명하겠습니다.
코드 설명
int maxChain = 0;
Set<String> wordSet = new HashSet<>();
Map<String, Integer> wordChainMap = new HashMap<>();maxChain 은 가장 긴 체인의 길이를 저장할 변수입니다.
words 배열로 들어오는 단어들을 wordSet 에 저장하고, 해당 단어의 최대 chain 을 저장할 wordChainMap 도 선언해줍니다.
for (String word: words) {
wordSet.add(word);
}wordSet 에 단어들을 저장해줍니다.
for (String word: words) {
maxChain = Math.max(maxChain, dfs(wordChainMap, wordSet, word));
}단어를 하나씩 chain 을 구해줄건데, 여기서 dfs 함수가 나타납니다.
dfs 함수의 값과 maxChain 의 값을 비교해서 더 큰 값을 maxChain 에 저장합니다.
dfs 함수
private int dfs(Map<String, Integer> map, Set<String> set, String word) {
if (map.containsKey(word)) return map.get(word);
int count = 0;
for (int i = 0; i < word.length(); i++) {
String compareWord = word.substring(0, i) + word.substring(i + 1);
if (set.contains(compareWord)) count = Math.max(count, dfs(map, set, compareWord));
}
map.put(word, count + 1);
return count + 1;
}map 에 해당 단어가 이미 존재한다면 그 단어의 chain 길이인 map.get(word) 를 return 합니다.
이 부분이 dfs 로직의 시간을 많이 줄여줍니다. 이미 체크한 word 의 chain 을 중복 체크하지 않아도 되기 때문이죠.
그리고 만약 map 에 해당 단어가 존재하지 않는다면 chain 길이를 구하기 위한 count 를 초기화해줍니다.
그리고 word 의 길이만큼 for문을 순회하며 word 에서 한 글자씩 제외한 compareWord 를 만듭니다.
모든 word 가 저장되어있는 set 에 compareWord 가 존재하면 chain 에 포함이 가능하기 때문에 count 를 체크합니다.
체크할 때에는 compareWord 로까지의 체인 길이를 계산해야하기 때문에 dfs 함수를 재귀호출합니다.
모든 가능한 compareWord 의 체인 길이 중 max 값을 구했다면, map 에 word 와 함께 count + 1 을 저장합니다.
count + 1 인 이유는 현재 word 까지 계산해야하기 때문에 1이 더해집니다.
전체 코드
class Solution {
public int longestStrChain(String[] words) {
int maxChain = 0;
Set<String> wordSet = new HashSet<>();
Map<String, Integer> wordChainMap = new HashMap<>();
for (String word: words) {
wordSet.add(word);
}
for (String word: words) {
maxChain = Math.max(maxChain, dfs(wordChainMap, wordSet, word));
}
return maxChain;
}
private int dfs(Map<String, Integer> map, Set<String> set, String word) {
if (map.containsKey(word)) return map.get(word);
int count = 0;
for (int i = 0; i < word.length(); i++) {
String compareWord = word.substring(0, i) + word.substring(i + 1);
if (set.contains(compareWord)) count = Math.max(count, dfs(map, set, compareWord));
}
map.put(word, count + 1);
return count + 1;
}
}마무리
어제, 오늘 둘 다 dfs 알고리즘을 활용해서 문제를 해결했습니다.
어제 dfs 문제를 풀어서인지 이번에는 조금 빠르게 해결한 것 같아 뿌듯하네요!
이번 포스팅도 읽어주셔서 감사하고 잘못된 부분에 대한 피드백 환영입니다 :)
