Ⅰ. 📚 오늘 배운 내용
- 브라우저의 역할
- google collab 웹스크래핑
1)bs4와requests라이브러리 설치- [prac] 네이버 뉴스 타이틀 크롤링
1) 뉴스 제목 가져오기
2) 뉴스 제목 여러 개 가져오기
3) 특정 키워드가 포함된 뉴스 타이틀 가져오기- [prac] 뉴스 타이틀 / 링크 / 언론사명 가져오기
1. 브라우저의 역할
- 서버에 받아올 정보를 api문(주소창)으로 요청해서 받아옴
2. google collab 웹스크래핑
1) bs4와 requests 라이브러리 설치
!pip install bs4 requests입력
🔥 [prac] 네이버 뉴스 타이틀 크롤링
❗️참고 : 웹개발 종합반_개발일지_Day 6 > 1) beautiful soup 사용법
- 라이브러리 사용시 만든 사람이 정해놓은 코드 작성법으로 입력해서 활용 (라이브러리 사용시 확인)
1) 뉴스 제목 가져오기
👉 input
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
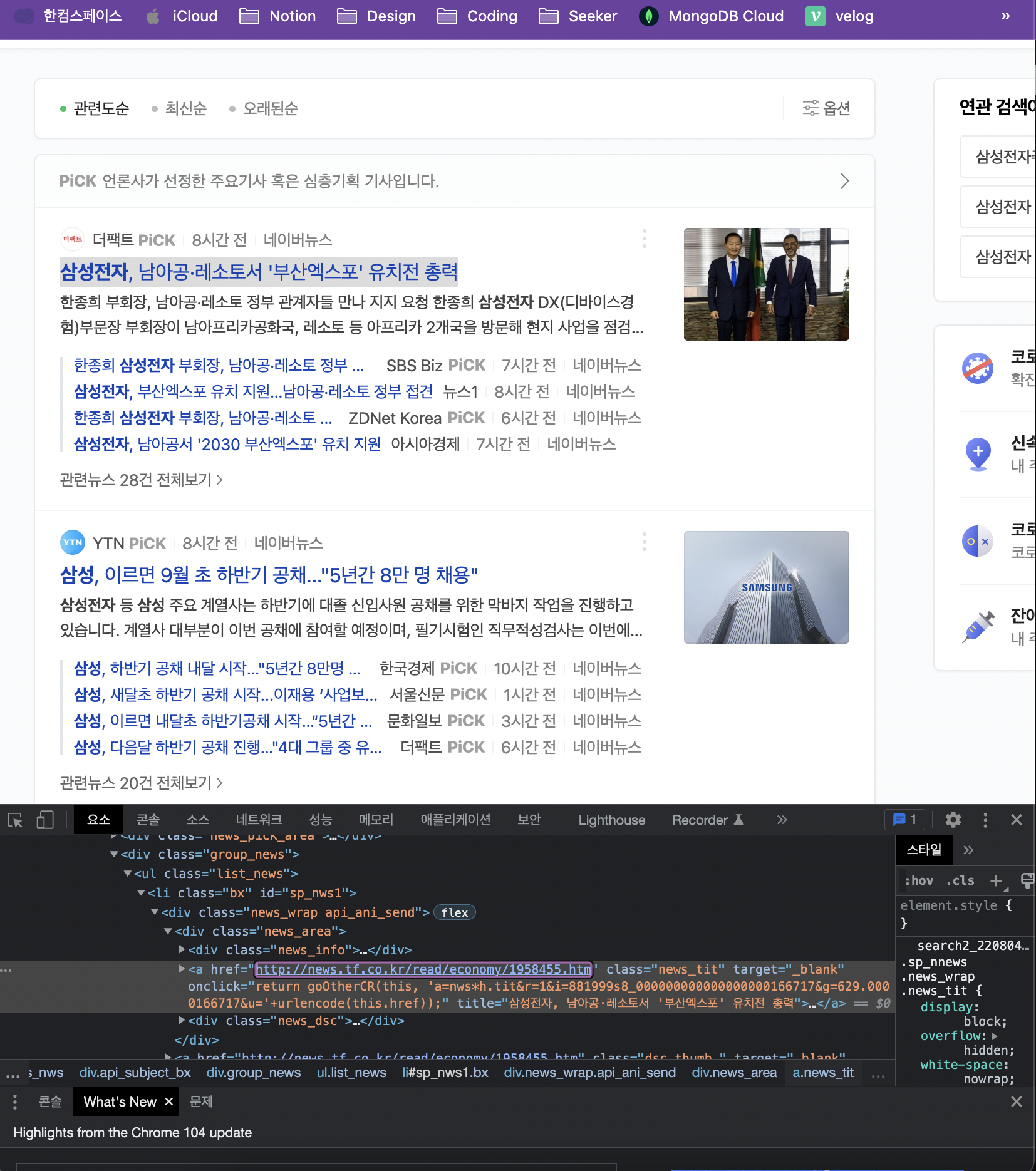
a = soup.select_one('#sp_nws1 > div.news_wrap.api_ani_send > div > a')
a.text➟ 삼성전자, 남아공·레소토서 '부산엑스포' 유치전 총력
2) 뉴스 제목 여러 개 가져오기
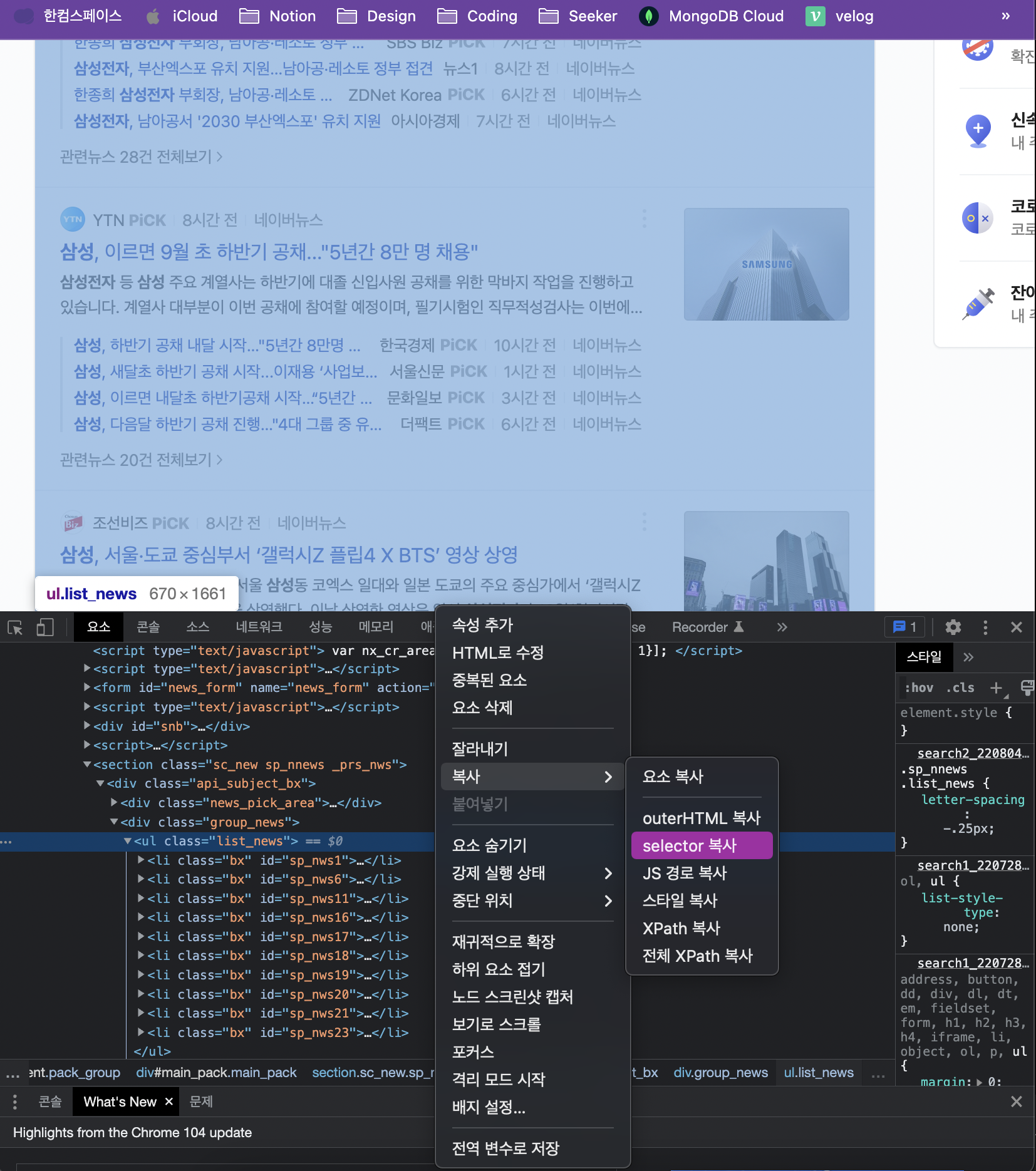
(1) <ul> 내 뉴스 <li> 항목들 가져오기
👉 input
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
lis👉 output
(2) <li> 내 뉴스 타이틀 가져오기
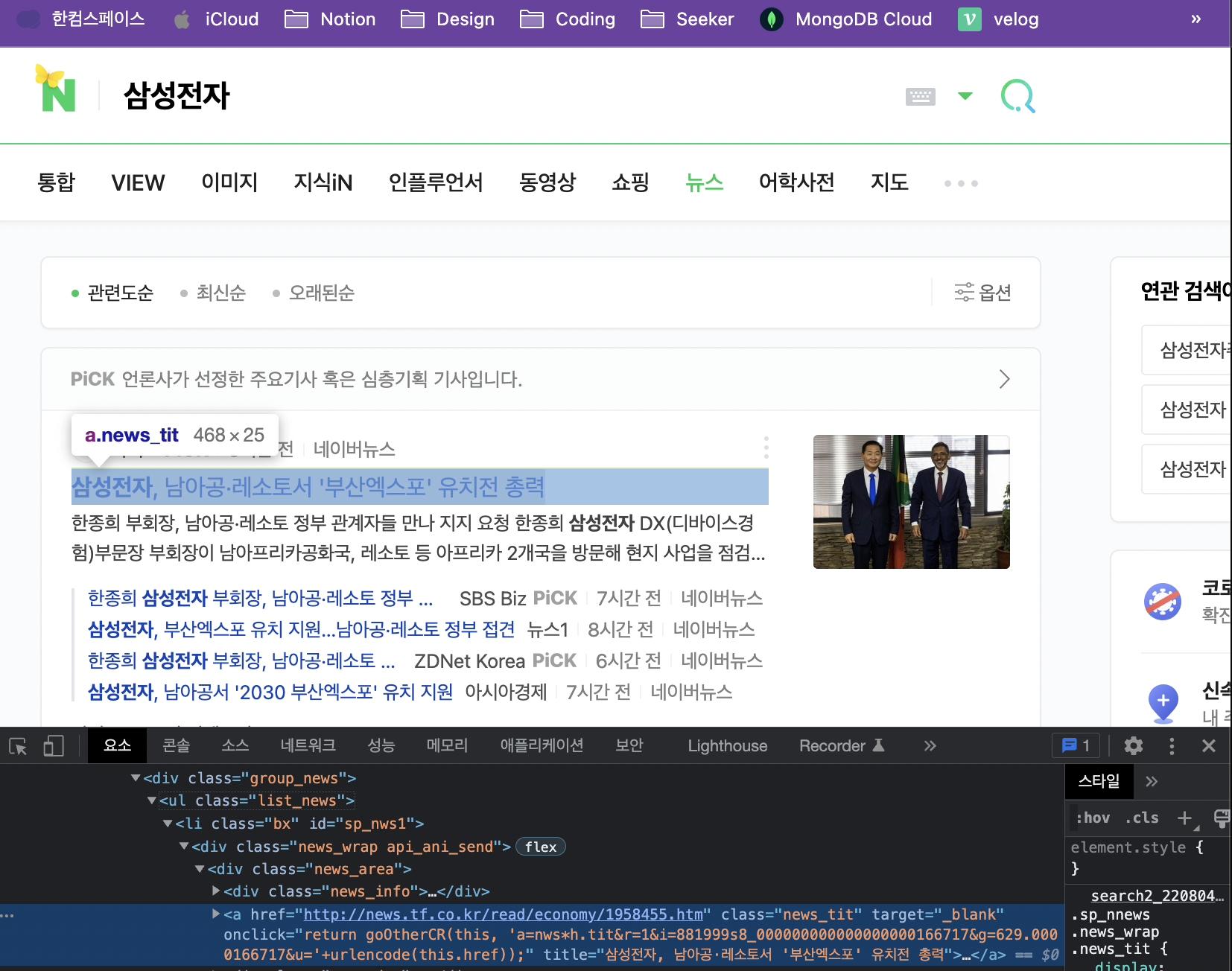
- class
news_tit값으로 타이틀 요소를 특정- 띄어쓰기는
.으로 표현
ex)<a>내class="new_tit"=a.new_tit
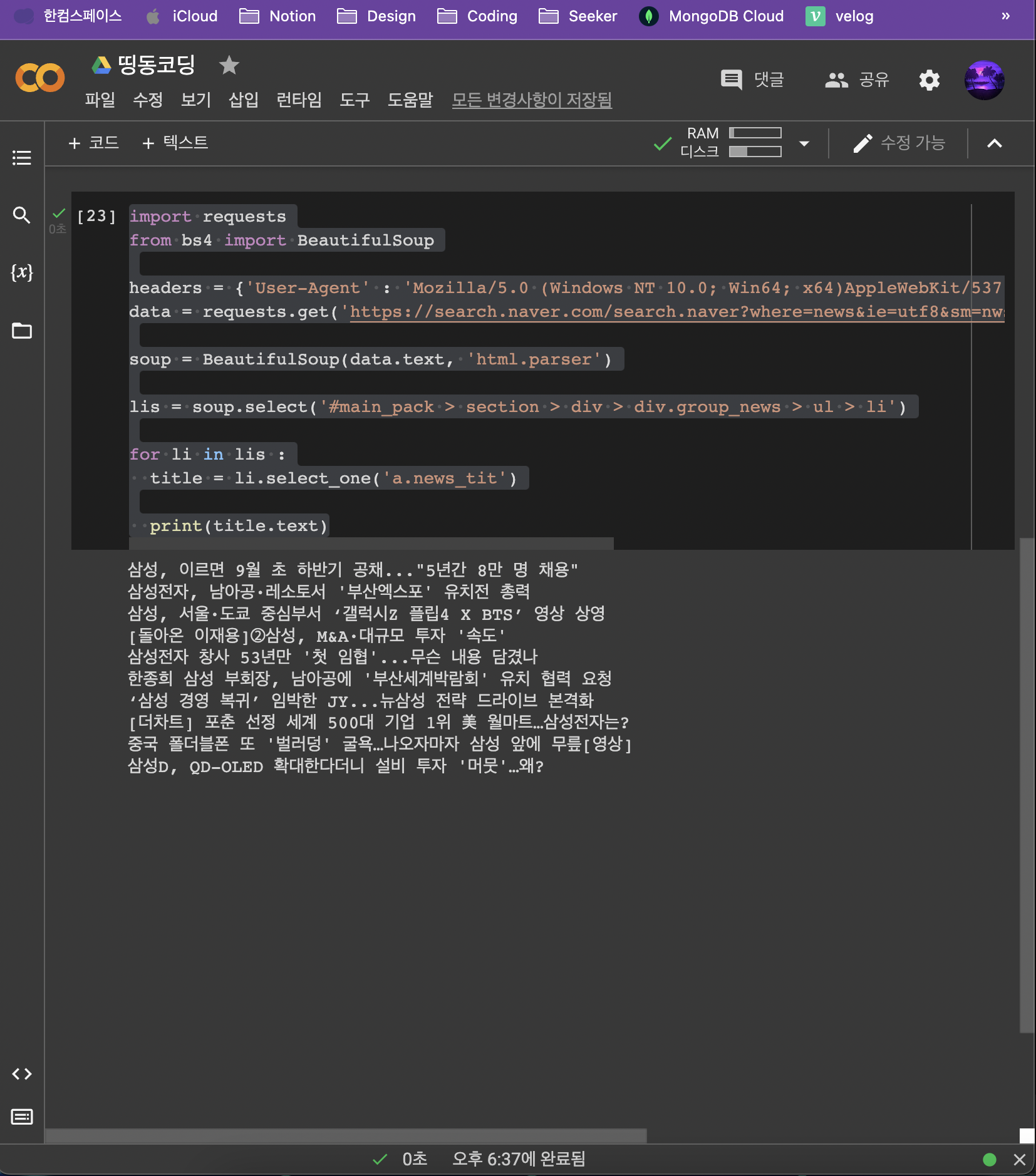
👉 input
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
for li in lis :
title = li.select_one('a.news_tit')
print(title.text)👉 output
3) 특정 키워드가 포함된 뉴스 타이틀 가져오기
- '임윤찬'이 포함된 기사
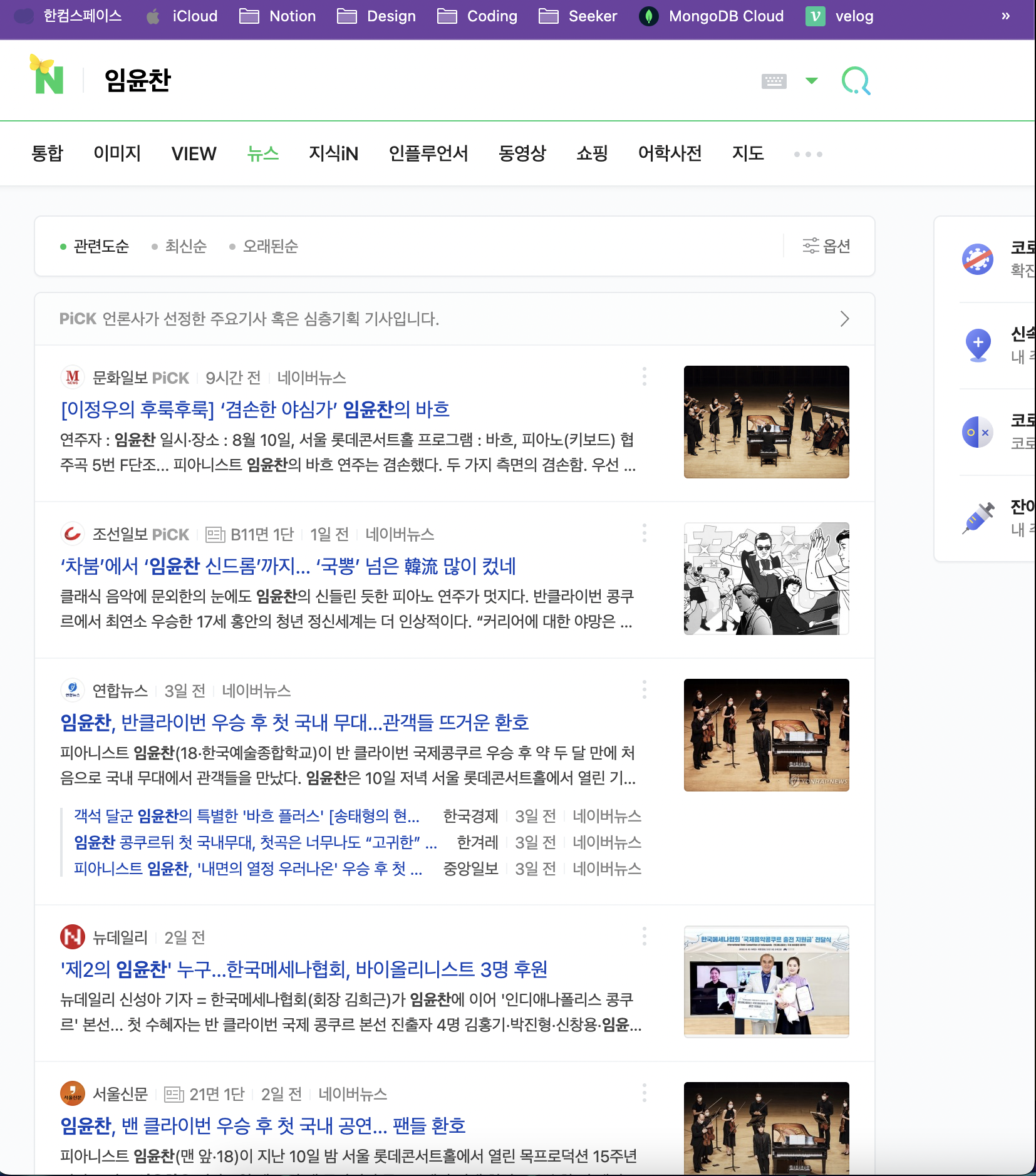
👉 input
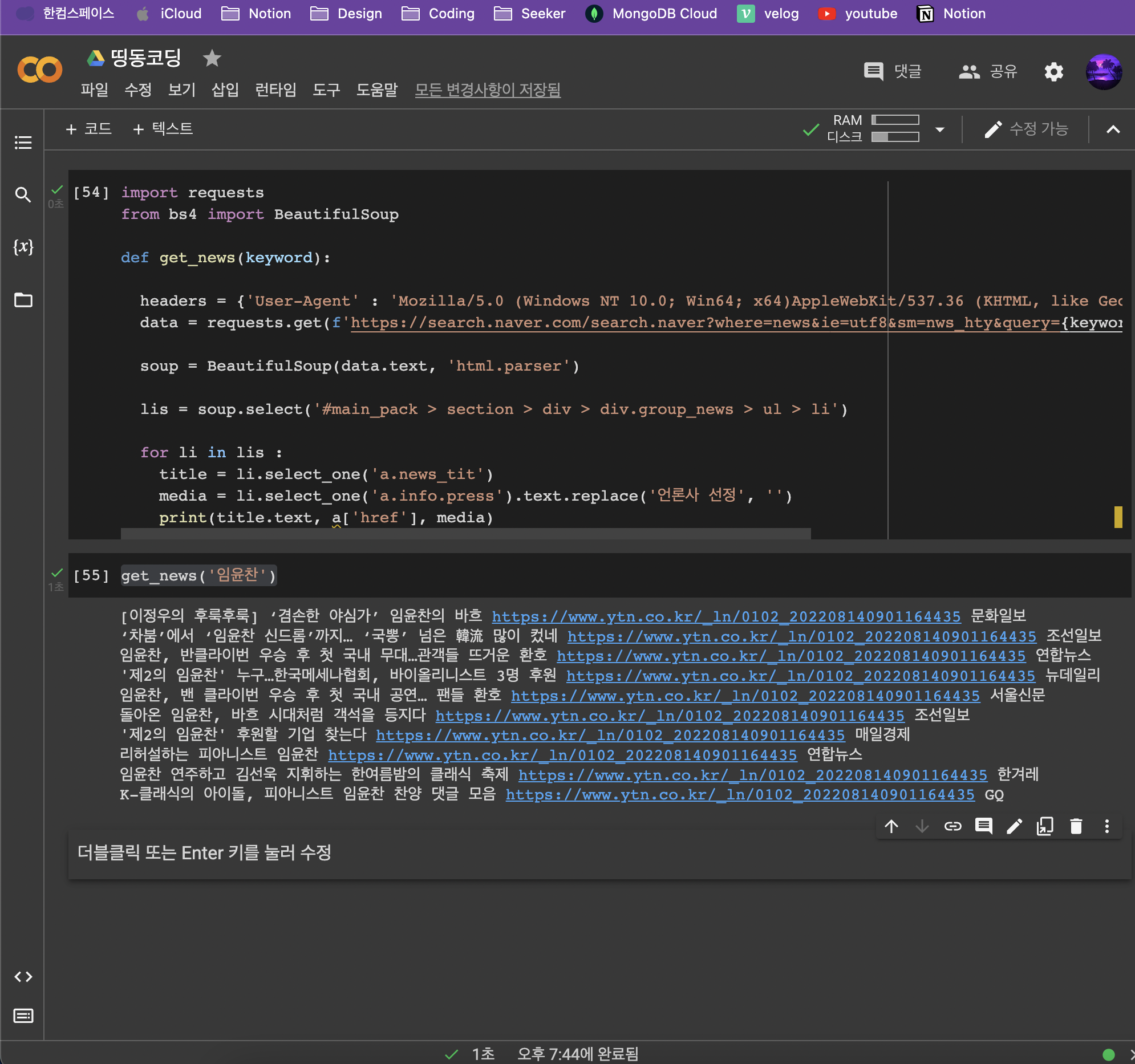
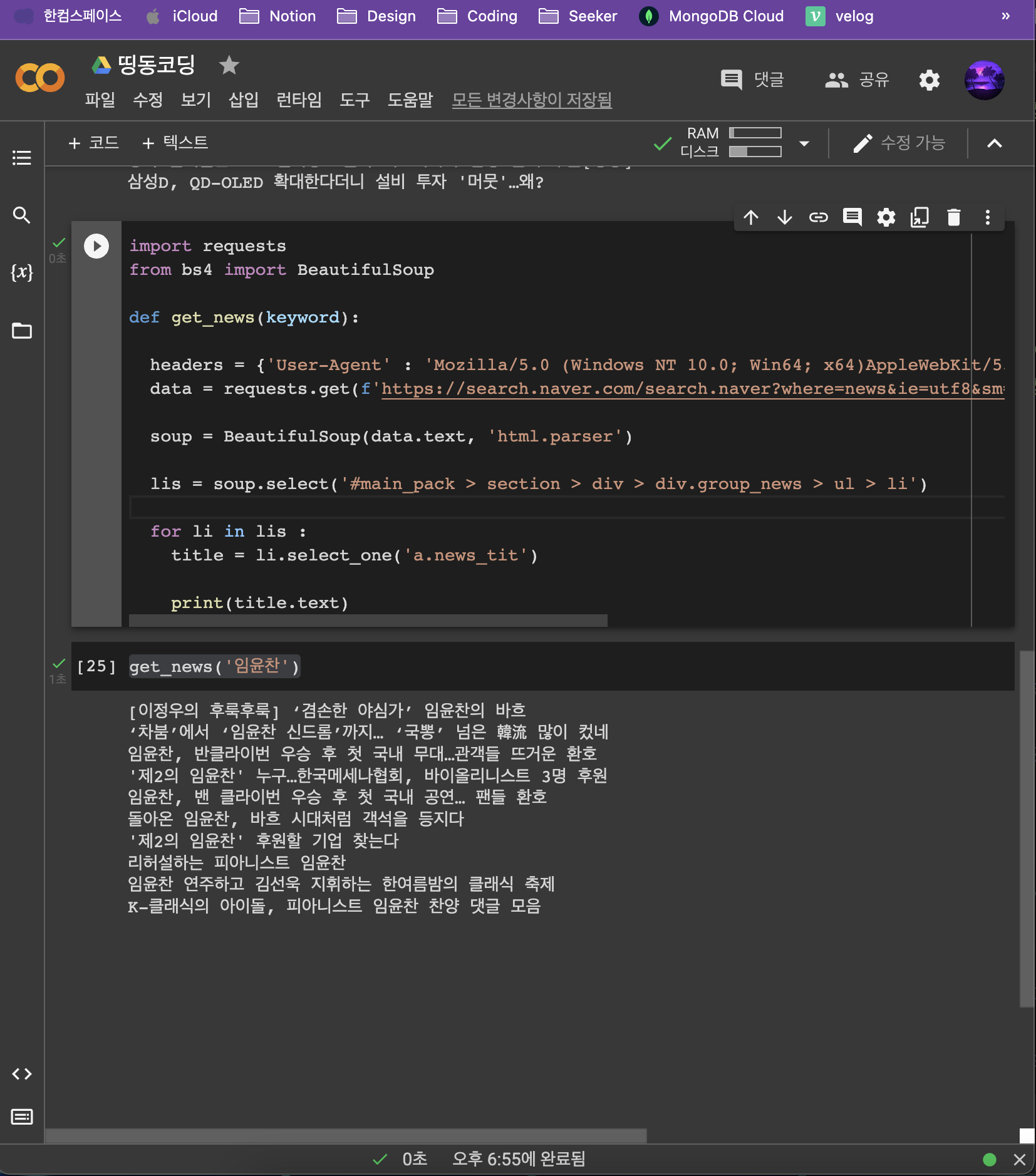
import requests
from bs4 import BeautifulSoup
def get_news(keyword):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
for li in lis :
title = li.select_one('a.news_tit')
print(title.text)get_news('임윤찬')👉 output
🔥 [prac] 뉴스 타이틀 / 링크 / 언론사명 가져오기
- 타이틀 내
href주소로 링크 가져오기- 언론사
class명으로 특정 짓기
👉 input
import requests
from bs4 import BeautifulSoup
def get_news(keyword):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
for li in lis :
title = li.select_one('a.news_tit')
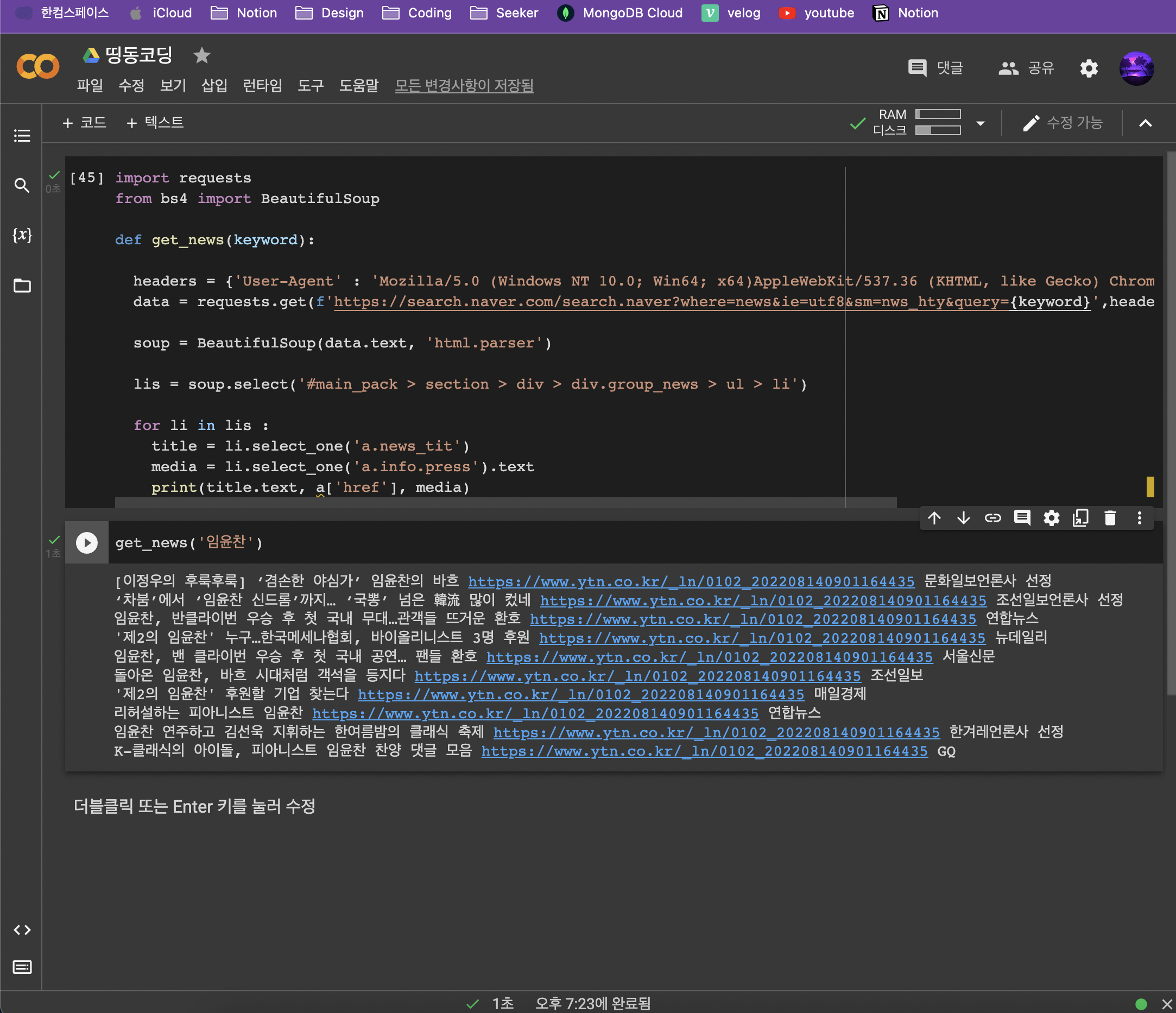
media = li.select_one('a.info.press').text
print(title.text, a['href'], media)
``
```python
get_news('임윤찬')👉 output
❗️ media 값 중 '언론사 선정'이 붙는 경우가 있어서 값이 통일되지 않음
- 문자열 대체 함수
replace()를 이용하여 '언론사 선정'을 공백으로 대체할 것
📍 media 값 통일 ver.
👇 오류 코드
import requests
from bs4 import BeautifulSoup
def get_news(keyword):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
for li in lis :
title = li.select_one('a.news_tit')
media = li.select_one('a.info.press').text
if media == '언론사 선정':
media = media.replace('언론사 선정', '')
print(title.text, a['href'], media)📍 오류 이유
언론사 선정을 빼려면 if 조건문으로 '언론사 선정'이라는 글씨가 있을 때 공백으로 대체하라 해야 한다고 생각했는데, 오류가 났다. 생각해보니 media 값에서 언론사 선정이라는 글씨가 있다는 걸 어떻게 인식하지? 라는 의문점에 if 조건문을 쓸거면 먼저 '언론사 선정'이라는 글씨를 추출하는 조건이 필요하다는 걸 생각했다. 그냥 이 경우에는 meida값 코드에 replace 함수를 붙여버리면 된다.
👇 정답 코드
import requests
from bs4 import BeautifulSoup
def get_news(keyword):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
for li in lis :
title = li.select_one('a.news_tit')
media = li.select_one('a.info.press').text.replace('언론사 선정', '')
print(title.text, a['href'], media)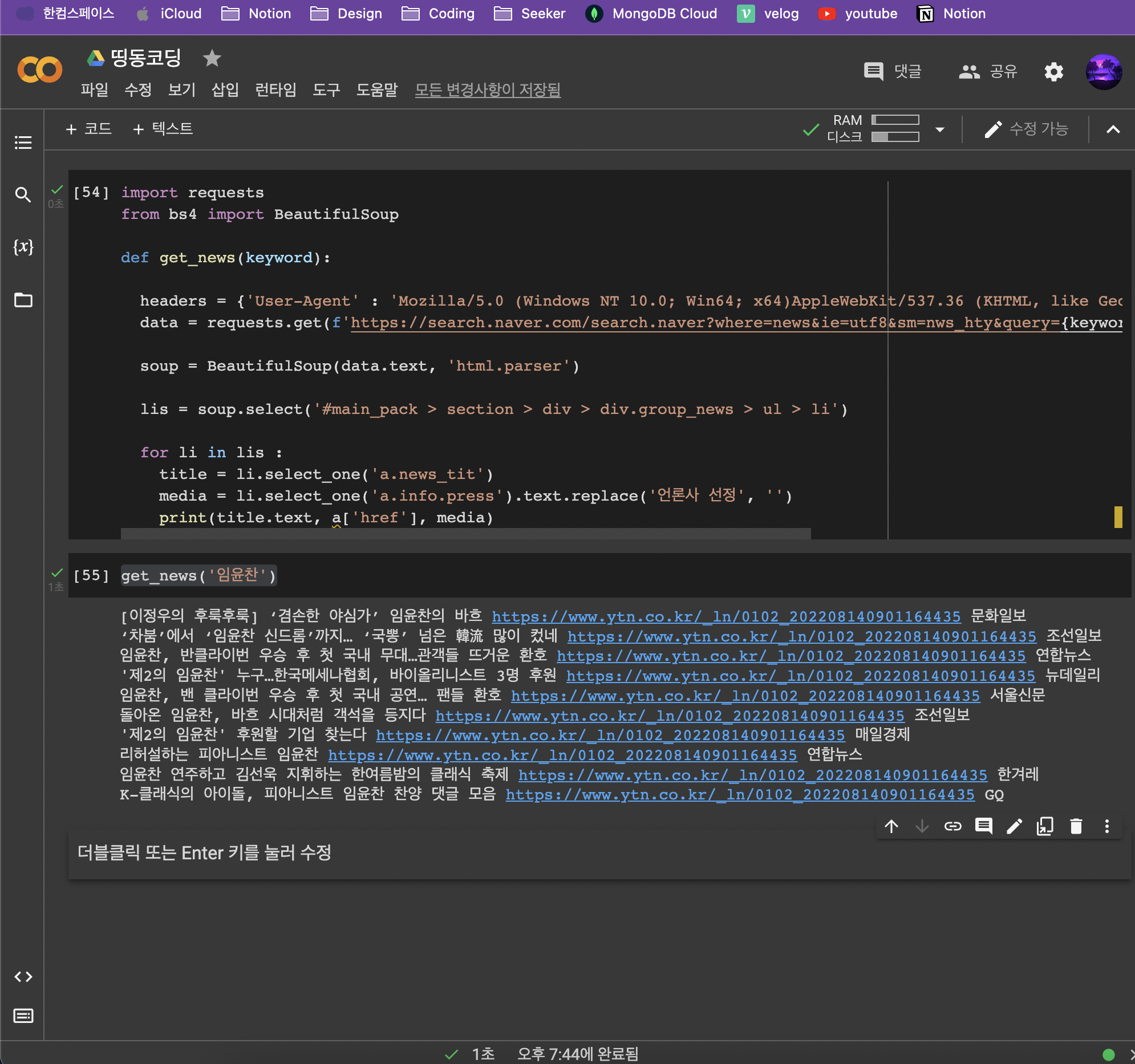
Ⅱ. 📝 회고
웹종반 수업과 틀은 비슷하지만, 연습할 때 조금씩 배울 수 있는 내용이 달라서 좋은 것 같다. 오늘 같은 경우도 기존에 웹개발 종합반_개발일지_Day 6랑 맥락은 비슷하지만, replace()함수를 활용하는 내용이 추가로 있어서 새로운 함수를 또 하나 배울 수 있었다.
Ⅲ. ☑️ TO DO
- 링크 트리

코딩입문 코린이